
КОЛИЧЕСТВЕННЫЕ МЕТОДЫ В МЕНЕДЖМЕНТЕ...
234
Томский политехнический университет Программа МВА «КОЛИЧЕСТВЕННЫЕ МЕТОДЫ В МЕНЕДЖМЕНТЕ, СТАТИСТИКА» Рабочая тетрадь Составитель: Д. Г. Куртенков
Transcript of КОЛИЧЕСТВЕННЫЕ МЕТОДЫ В МЕНЕДЖМЕНТЕ...

Томский политехнический университет
Программа МВА
«КОЛИЧЕСТВЕННЫЕ МЕТОДЫ В МЕНЕДЖМЕНТЕ, СТАТИСТИКА»
Рабочая тетрадь
Составитель: Д. Г. Куртенков

Куртенков Денис Геннадьевич
Д. Г. Куртенков является специалистом в области информатики, статистики и
компьютерного моделирования экономических процессов. Защитил
кандидатскую диссертацию в 1998 году. В настоящее время является
доцентом кафедры международного менеджмента ТПУ и ведущим
специалистом центра программ МВА ТПУ. Д. Г. Куртенков преподает курсы
«Статистика», «Информационные технологии», «Компьютерное
моделирование экономических процессов». Имеет около 20 научных
публикаций в отечественной и зарубежной печати. Проходил стажировки в
Великобритании (Heriot-Watt University), Германии (Heidelberg University).
2

Содержание
Содержание Введение ................................................................................................................... 4
Литература ............................................................................................................... 5
Часть I. Введение в статистику .............................................................................. 6
Тема 1. Введение в статистику. Примеры корректного и некорректного
использования статистики............................................................................ 6
Тема 2. Основы математики: школьная математика в менеджменте .... 29
Часть II. Обработка числовой информации........................................................ 50
Тема 3. Представление данных.................................................................. 50
Тема 4. Анализ данных ............................................................................... 71
Тема 5. Сводные измерения ....................................................................... 88
Тема 6. Методы выборочного обследования ......................................... 112
Часть III. Статистические методы ..................................................................... 131
Тема 7. Распределения .............................................................................. 131
Тема 8. Статистический вывод ................................................................ 154
Часть IV. Статистические зависимости ............................................................ 176
Тема 9. Регрессия и корреляция .............................................................. 176
Часть V. Прогнозирование конъюнктуры ........................................................ 196
Тема 10. Временные ряды ........................................................................ 196
3

Введение
Введение Полная и достоверная статистическая информация является тем необ-
ходимым основанием, на котором базируется процесс управления экономи-
кой. Принятие управленческих решений на всех уровнях – от общегосудар-
ственного или регионального и до уровня отдельной корпорации или не-
большой фирмы – невозможно без должного статистического обеспечения.
Именно статистические данные позволяют выявить основные тенден-
ции развития отраслей экономики, измерить уровень инфляции, проанализи-
ровать состояние финансовых и товарных рынков, оценить конкурентоспо-
собность и рыночные позиции предприятия, сделать прогнозные оценки на
перспективу.
Статистическая методология исследования в настоящее время заняла
прочные позиции во многих областях знания. Статистические формулы на-
ходят применение в макро- и микро экономике, оценке бизнеса и недвижи-
мости, финансовом анализе, техническом анализе рынка ценных бумаг и т.д.
Статистический инструментарий, используемый как в макроэкономи-
ческой и отраслевых статистиках (статистике промышленности, сельского
хозяйства, торговли и прочих), социальной статистике и статистике населе-
ния, так и в сфере бизнеса в сложившейся отечественной классификации на-
ук является предметом теории (общей теории) статистики. За рубежом дан-
ная методология, как правило, рассматривается в курсах бизнес-статистики
(Business statistics) и иллюстрируется примерами из производственной, фи-
нансовой или коммерческой сфер деятельности.
Процесс статистического исследования включает три основные стадии:
сбор данных, их сводку и группировку, расчет и анализ обобщающих показа-
телей, и завершается формулировкой выводов и выработкой рекомендаций
для принятия управленческих решений.
В данном пособии изложена общая схема процесса статистического ис-
следования с приведением основных, наиболее распространенных и значи-
мых формул.
4

Литература
Литература Основная 1. Статистический словарь / Гл. ред. М.А. Королев.- М.: Финансы и
статистика, 1989.
2. Теория статистики: Учебник/Под ред. проф.Р.А Шмойловой - М.:
Финансы и статистика, 1998.
3. Ефимова М.Р., Петрова Е.В., Румянцев В.Н. Общая теория статистики:
Учебник. - М.: ИНФРА - М, 1998.
4. Венецкий И.Г., Венецкая В.И. Основные математико-статистические
понятия и формулы в экономическом анализе.- М.: Статистика, 1979.
5. Тюрин Ю.Н., Макаров А.А. Статистический анализ данных на
компьютере / Под ред. В.Э. Фигурнова.- М.: ИНФРА - М., Финансы и
статистика, 1998.
6. Елисеева И.И., Юзбашев М.М. Общая теория статистики: Учебник/Под
ред.чл.-корр. РАН И.И.Елисеевой. - М.: Финансы и статистика, 1997.
7. Общая теория статистики: статистическая методология в изучении
коммерческой деятельности: Учебник/Под ред. А.А. Спирина, О.Э.
Башиной.- М.: Финансы и статистика, 1997.
8. Баззел Р.Д., Кокс Ф.Д., Браун Р.В. Информация и риск в маркетинге.- М.:
Финстатинформ, 1993.
9. Quantitative Methods. A Distance Learning Programme. Professor David
Targett - HERIOT-WATT UNIVERSITY.
Дополнительная 10. James T. McClave, P. George Benson, Terry Sincich. A First Course In
Business Statistics. - Seventh edition. - Prentice Hall International, Inc. - 1998.
11. Elder Alexander. Trading for a living: psychology, trading tactics, money
management.- John Wiley & Sons, Inc., 1993.
12. Hamburg M. Statistical analysis for decision making.- New York, 1983.
5

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
6
Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры корректного и некорректного использования статистики
Статистика – общественная наука, изучающая количественную сторону
качественно определенных массовых социально-экономических явлений и
закономерностей их развития в конкретных условиях места и времени.
В этой теме мы сделаем небольшой обзор науки «статистика»,
основных идей и концепций на поверхностном уровне, позднее, на
следующих занятиях, мы рассмотрим многие понятия более детально и
подробно. Главная цель этой темы подготовить почву для «безбоязненного»
изучения статистки, как бы в ответ на то весьма скептическое отношение к
статистике как к некоему запутанному, сложному и весьма непонятному
предмету.
1.1. Введение Слово статистика означает одновременно как набор чисел, так и науку,
которая эти наборы чисел изучает. Зачастую оба этих смысла слова
статистики заслуживают отрицательного к ним отношения. Услышав слово
статистика, мы часто в уме проводим параллели – «ложь, неправда, обман».
Почему так происходит? Есть много причин, одна из них – это
восприятие статистики как некоего «языка». Также как и обычный язык
можно использовать неправильным образом (как это часто делают политики
или журналисты), так и числовой язык статистики может быть использован
некорректно (опять же в первую очередь журналистами и политиками). И
поэтому винить статистику за это, это то же самое, что винить русский
(английский) язык, когда предвыборные обещания не выполняются.
Часто те люди, которые не очень хорошо знакомы с предметом
статистики, непреднамеренно используют статистические приемы неверно,
ошибочно просто потому, что они не знают, как правильно применять этот
6

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
7
предмет. Простая грамотность и умение производить вычисления еще не
означает, что мы можем производить статистические выкладки и получать
правильные ответы на поставленные задачи.
К примеру, в годовом отчете компании отражено, что ее годовая
прибыль составляет $34 236 417. Первое, что нам приходит на ум, что, скорее
всего эта цифра правильная, ведь она такая точная и неровная, не правда ли?
А где доказательства, что методы ее подсчета были корректны, и что
подразделения компании, которые подавали свои данные в головной офис, не
лгали нарочно или ошибались непреднамеренно?
Или другой пример, имеющий некоторое отношение к маркетингу.
Допустим, в маркетинговом отчете отмечено, что 9 из 10 собак предпочитают
собачью пищу «ПедиГри». Правда ли это? Скорее всего – нет. И в голову
приходит сразу масса вопросов – «Предпочитают ПедиГри чему?»,
«Предпочитают при каких обстоятельствах?», «9 из 10 каких собак?».
Такие примеры, и масса других, могут создать и зачастую создают
негативное отношение к статистике, создают ей дурную репутацию. И даже
могут нас отпугнуть он нее, так же как и от всего другого, от чего попахивает
враньем. Но, с другой стороны, невозможно заниматься бизнесом и
игнорировать статистику. Ведь решения принимаются на основе
информации, информация же часто представлена в цифровом виде. А чтобы
принимать решения необходимо понимать цифровую информацию и
правильно ее организовывать. Именно этому нас и учит статистика, и именно
поэтому необходимо иметь знания по этому предмету.
Наука «статистика» состоит из двух частей. Первая часть называется
описательная статистика. В широком смысле этого слова она имеет дело в
сортировкой большого количества собранной цифровой информации для
того, чтобы главные особенности или характерные черты были видны как
можно скорее. Или другими словами она учит нас превращать наборы чисел
в полезную информацию. Предлагаются идеи и методы организации и
перегруппировки данных для того, чтобы в данных стали видны какие-либо
7

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
8
закономерности (если они там есть). Ну и конечно особую часть в
описательной статистике занимает изучение компьютерных статистических
программ, так называемых информационных систем или систем принятия
решений.
Вторая часть статистики называется статистика вывода. Эта часть
посвящена проблеме, как может небольшое количество собранных данных
(называемое выборка) быть проанализировано для того, чтобы сделать некий
логический вывод или заключение обо всех похожих данных, которые еще не
собраны, но существуют в природе (называемых генеральная совокупность).
Например, опросы общественного мнения используют статистику вывода для
получения мнений всего электората страны на основе полученных сведений
лишь от малой части населения этой страны.
Естественно, обе части статистики «открыты» для неправильного
использования. Но, даже обладая незначительными знаниями и чувством
здравого смысла, ошибки могут быть отслежены и исправлены.
1.2. Вероятность Самое первое и основополагающие понятие статистики – это
вероятность. Статистика часто, если не всегда, имеет дело с приближениями,
округлениями, догадками из-за того, что практически всегда невозможно
собрать ВСЕ необходимые данные. Очень редко получается что-то
утверждать со 100%-ной уверенностью.
Вероятность – числовая характеристика степени возможности
появления какого-либо случайного события при тех или иных определенных,
могущих повторяться неограниченное число раз условиях.
8

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
9
Все события, которые должны произойти в будущем, неопределенны в
какой-то степени. Скажем, то, что президент России Медведев останется по-
прежнему у власти в течение 2008 года весьма вероятно, но не бесспорно,
или то, что следующий президент в России будет коммунистом
неправдоподобно, но вполне возможно. Можно даже построить некую шкалу
вероятностей всех событий (по сути, прямую линию, см.рис.1.1).
На одном конце этой линии будут располагаться невероятные события
(скажем то, что мы можем самостоятельно переплыть Атлантический океан)
– их вероятность равна 0 (0%). С другой стороны будут расположены
абсолютно вероятные события (что мы все с вами когда-нибудь умрем). А
между этими двумя экстремумами располагаются все остальные более или
менее вероятные события согласно их вероятности.
Например, вероятность выпадения решки при бросании монеты – 0.5,
вероятность выигрыша в лотерее, состоящей из ста билетов – 0.01.
В математической записи «вероятность события A равна 0.6» будет
записана так: P(A)=0.6.
1.2.1. Расчёт вероятности Существует три метода для подсчета вероятности. Эти методы не
являются взаимозаменяемыми, так как в каждом случае для подсчета
вероятности подойдет только один из этих трех методов. Практически всегда
сразу понятно, какой метод и в каком случае случает использовать.
Метод «Априори»
В этом методе вероятность события подсчитывается при помощи
логических размышлений. Нет даже необходимости проводить
эксперименты. При помощи этого метода считают вероятности для монет,
игральных костей и карт. Скажем, вероятность выпадения цифры 3 на
игральной кости с шестью гранями равна 1/6. Если конечно игральная кость
«честная».
9

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
10
Метод «Относительных частот»
Когда событие было повторено или может быть повторено большое
количество раз, его вероятность может быть подсчитана по формуле:
Р = Количество свершившихся событий/Количество попыток.
Например, чтобы подсчитать вероятность дождя в сентябрьский день в
Лондоне, была проанализирована история осадков в Лондоне за последние 10
лет. Оказалось, что дождь в сентябре был 57 раз. Отсюда:
Р=57/(10*30)=0.19.
Субъективный метод
Третий метод является весьма и весьма спорным. Некоторые группы
ученых (классическая школа) утверждают, что такой метод использовать
вообще нельзя, некоторые использование метода допускают (например,
Байесовская школа). Нам же важно в настоящее время знать, что иногда
невозможно сосчитать вероятность того или иного события, используя
первые два метода. Скажем, как подсчитать вероятность того, что в 2010 году
Европа превратится в одно единое государство? Но, взвесив все за и против,
изучив большое количество фактов, текущее политико-экономическое
состояние в Европе, мы можем с большей или меньшей уверенностью
сказать, что вероятность такого события скажем 0.1. Естественно, это не
точно. Именно поэтому такой метод и называется субъективным. Именно
поэтому ученые до сих пор спорят об этом методе.
Примеры 1. Сосчитать вероятность выпадения черной масти из колоды в 36 игральных
карт?
2. Вероятность строительства метро в г. Томске?
3. Как сосчитать вероятность выпадения решки в монете со смещенным
центром тяжести. Известно, что монету подбросили 100 раз и орел выпал
40 раз?
4. Вероятность выпадения туза в колоде из 52 карт?
10

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
11
1.3. Дискретные статистические распределения Понятие вероятность делает возможным изучить другой интересный
статистический элемент – статистическое распределение. Его можно
рассматривать как один из первых шагов в описательной статистике или как
краеугольный камень в статистике вывода. Изначально он был рассмотрен в
описательной статистике. Давайте представим набор данных. Скажем
распределение продаж какого-либо товара (например, автомобилей Порше)
по дилерским центрам в США.
Числа – это измеренные значения какой-то переменной. То есть это
нечто, что можно измерить и то, что изменяется, когда производится
несколько различных наблюдений. Переменная может быть и количеством
серьезных преступлений в каждом регионе России, и рост мужчин возрастом
20 лет в Томской области. Числа в статистике часто называются также
наблюдения или точки данных.
Взглянув еще раз на наш рисунок с цифрами, мы замечаем простой
беспорядочный набор чисел. Нам трудно понять, что же он значит, и что же
из этих данных мы можем для себя извлечь. Не правда ли?
Первое, что из логики вещей нам придет сделать на ум, чтобы хоть как-
то упорядочить данные – это отсортировать и занести в таблицу (см.таб.1.1).
11

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
12
Эта таблица представляет собой отсортированный массив данных.
Теперь данные уже не в таком беспорядке, как раньше, но до сих пор
невозможно почувствовать эти данные. Или узнать среднее. Надо сделать
что-то еще…
Следующий шаг – это разбить данные по классам и записать эти
классы по порядку. Классификация данных означает группировку данных по
диапазонам (скажем от 50 до 59). Каждый класс имеет частоту, которая равна
количеству чисел, которые в этот класс или диапазон попадают.
Получившаяся таблица называется частотной таблицей (см.таб.1.2). По ней
уже видно, что 7 точек данных попали в диапазон больше или равно 40 и
меньше 50, 12 точек больше ли равны 50, но меньше 60. Так же видно, что
всего существует 100 точек данных.
Вот теперь уже легче понять общую концепцию данных, то есть то, что
эти данные значат. Например, мы видим, что большее количество точек
данных лежат между 60 и 90. А экстремумы – это 40 и 110. Конечно мы еще
не получили полной картины продаж автомобилей в США, но мы теперь уже
12

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
13
кое-что про это знаем, и главное, мы узнали это в очень короткое время. Не
так ли?
Следующее, что можно сделать, чтобы данные стали еще более
понятными – это превратить нашу частотную таблицу в частотную
гистограмму (см.рис.1.3).
Лишь бросив взгляд на гистограмму, мы уже видим экстремумы,
видим, в каком диапазоне сконцентрирован средний объем продаж. Итак,
потратив лишь немного времени, мы можем сделать данные более легкими в
понимании и в последующем анализе.
Вообще говоря, частотная гистограмма – это прекрасный описательный
инструмент и нет нужды каким-либо образом ее трансформировать во что-то
иное. С другой стороны, существуют такие аналитические задачи, когда
частотную гистограмму необходимо превратить в статистическое
распределение, но об этом чуть позже.
Теперь давайте установим связь между частотами и вероятностями в
нашей гистограмме путем применения метода «относительных частот».
Вероятность того, что случайно отобранное измерение лежит в каком-то
классе (диапазоне) может быть подсчитана по формуле:
Р(число лежит в классе Х) = Частота в классе Х / Общая частота или
Р(число лежит в классе Х) = Высота колонки Х / Общая частота или
P(40<=X<50) = 7/100 = 0.07.
13

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
14
Теперь мы можем превратить нашу частотную гистограмму в
гистограмму вероятностей путем откладывания по вертикальной оси
вероятностей (рассчитанных по формуле) вместо частот. Естественно, форма
гистограммы не изменится. Такую гистограмму мы можем назвать
распределением (распределением вероятностей). В нашем случае дискретных
вероятностей.
Переменная считается дискретной, если она ограничена в значениях,
которые она может принимать. Например, когда данные ограничены
классами, то переменные дискретны. Также, когда переменные могут
принимать только целые значения, она тоже дискретны.
Вероятностная гистограмма упрощает работу с вероятностями классов.
Например, если вероятности двух классов:
P(50<=X<60) = 0.12 и P(60<=X<70) = 0.22
тогда
P(50<=X<70) = 0.12 + 0.22 = 0.34.
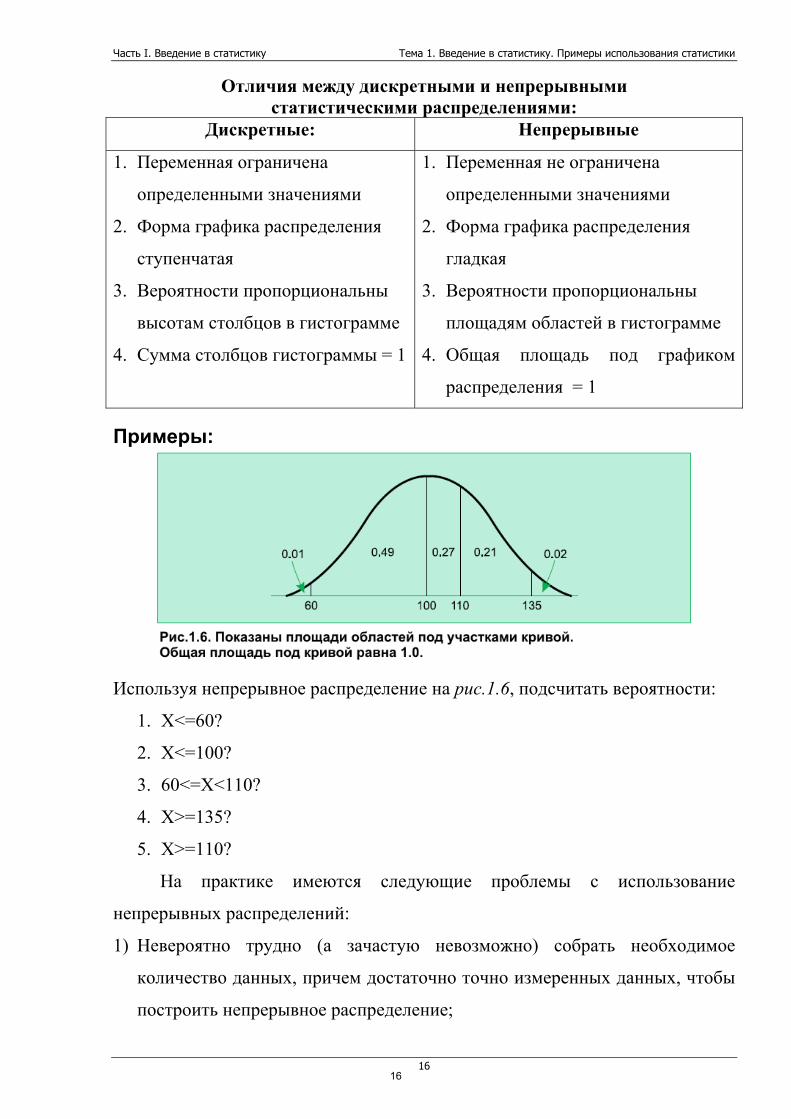
Примеры: 1. P(80<=X<100) = 0.19 + 0.10 = 0.29
2. P(X<70) = 0.07 + 0.12 + 0.22 = 0.41
3. P(60<=X<100) = 0.22 + 0.27 + 0.19 + 0.10 = 0.78
1.4. Непрерывные статистические распределения Еще раз повторим, существуют вероятностные гистограммы
переменных, из них могут быть получены вероятности любого из измерений
переменной, которая находится в одном из классов (диапазонов)
гистограммы. Такие распределения называют дискретными. Распределение –
потому что переменные распределены среди диапазона значений, дискретное
– потому что значения переменных ограничено значениями, которые они
могут принимать, они ступенчато изменяются (11, 12, 13…), а не плавно
переходят из одного в другое (11.(0)1, 11.(0)2…).
14

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
15
Непрерывные переменные не ограничены в значениях, которые они
могу принимать. Это могут быть и целые числа, и любые значения между
двумя соседними целыми числами. Распределение, сформированное из
непрерывных переменных – есть непрерывное распределение.
Давайте попробуем для примера превратить наше дискретное
распределение в непрерывное (см.рис.1.4).
В нашем случае с дискретным распределением мы определили, что
наши классы будут шириной в 10 единиц. На рис.1.4b мы уменьшаем ширину
класса вдвое (класс 50<=Х<60 превращается в два класса - 50<=Х<55 и
55<=Х<60, на рис.1.4с еще в несколько раз. Если этот процесс продолжать –
то распределение становится глаже и глаже, и, в конце концов, становится
непрерывным (рис.1.4d).
15
Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
16
Отличия между дискретными и непрерывными статистическими распределениями:
Дискретные: Непрерывные
1. Переменная ограничена
определенными значениями
2. Форма графика распределения
ступенчатая
3. Вероятности пропорциональны
высотам столбцов в гистограмме
4. Сумма столбцов гистограммы = 1
1. Переменная не ограничена
определенными значениями
2. Форма графика распределения
гладкая
3. Вероятности пропорциональны
площадям областей в гистограмме
4. Общая площадь под графиком
распределения = 1
Примеры:
Используя непрерывное распределение на рис.1.6, подсчитать вероятности:
1. Х<=60?
2. Х<=100?
3. 60<=Х<110?
4. Х>=135?
5. Х>=110?
На практике имеются следующие проблемы с использование
непрерывных распределений:
1) Невероятно трудно (а зачастую невозможно) собрать необходимое
количество данных, причем достаточно точно измеренных данных, чтобы
построить непрерывное распределение;
16
Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
17
2) Точно измерить площади под кривой распределения достаточно непросто.
Основное практическое использование непрерывных распределений
возможно тогда, когда они являются стандартными распределениями. Эта
тема, которую мы сейчас и рассмотрим.
1.5. Стандартные распределения Распределение, которое мы с вами рассматривали ранее можно также
назвать наблюдаемым распределением. Данные были собраны, затем была
построена гистограмма, и это и было распределением (в данном случае
продаж автомобилей). Стандартные распределения имеют теоретическую, а
не наблюдаемую основу. Это распределения, которые определены
математически исходя из теоретической ситуации. Характеристики этой
ситуации выражаются математически. И когда какая-то реальная обстановка
напоминает теоретическую, тогда и используются стандартные
распределения.
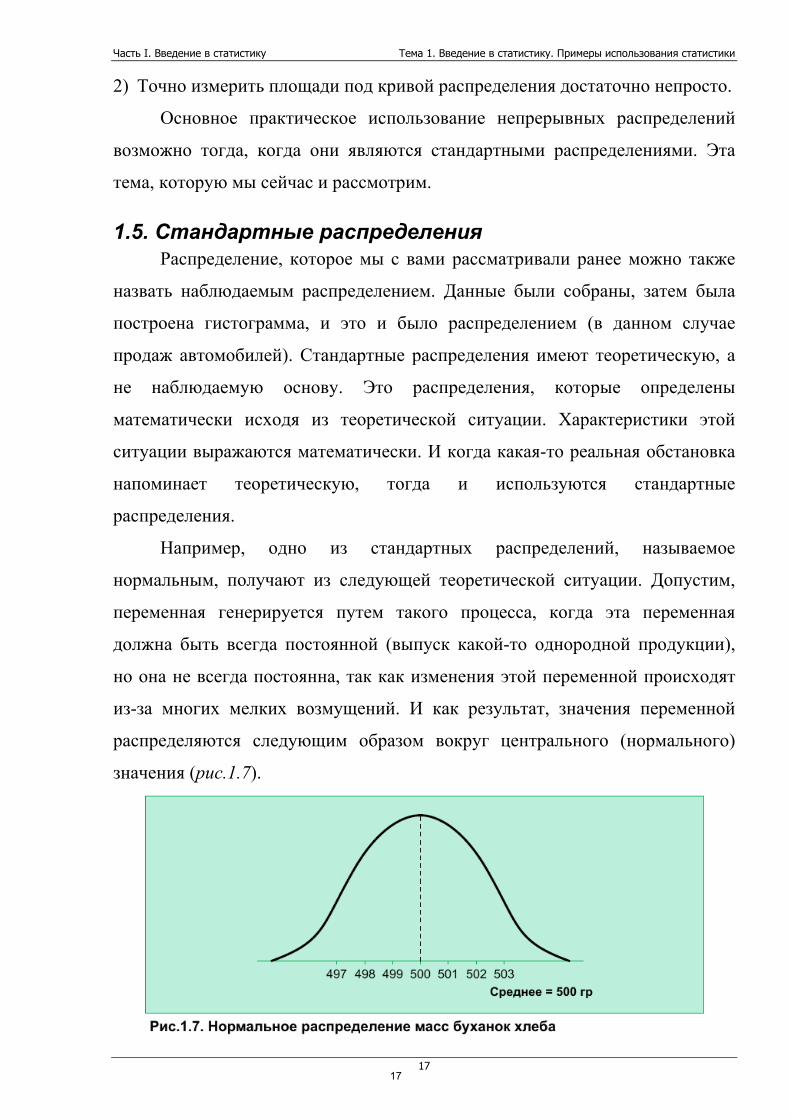
Например, одно из стандартных распределений, называемое
нормальным, получают из следующей теоретической ситуации. Допустим,
переменная генерируется путем такого процесса, когда эта переменная
должна быть всегда постоянной (выпуск какой-то однородной продукции),
но она не всегда постоянна, так как изменения этой переменной происходят
из-за многих мелких возмущений. И как результат, значения переменной
распределяются следующим образом вокруг центрального (нормального)
значения (рис.1.7).
17

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
18
Данный случай (центральное значение, множество мелких
возмущений) может быть выражен математически, и результирующее
распределение тоже может являться найденной математической формулой,
описывающей форму этого распределения.
Итак, кривая стандартного распределения может быть получена из
математической формулы, или, что чаще бывает, из готовых таблиц кривых.
Пример нормального распределения. Например, станок изготавливает
прутки металла определенной формы, разрезая стальную проволоку. Прутки
должны получаться одинаковой длины, но из-за вибраций, ошибок оператора
станка, неточности работы станка, прутки несколько отличаются друг от
друга по длине. Нетрудно сосчитать процент продукции, которая находится
за пределами, которые допустимы для данного технологического процесса.
Нормальные распределения могут применяться во многих схожих
случаях. Существует также и масса других стандартных распределений, и
также существуют условия, при которых эти распределения можно
применять на практике. Неоспоримым преимуществом таких распределений
над дискретными является то, что в дискретных не только необходимо
собирать экспериментальным путем большое количество данных, но и делать
это каждый раз для каждой конкретной ситуации.
Использование наблюдаемых распределений подразумевает, что
данные должны быть собраны и затем построены гистограммы,
использование стандартных распределений подразумевает, что генерируемые
каким-либо процессом данные близко напоминают теоретическую ситуацию,
для которой распределение может быть построено математически.
1.5.1. Нормальное распределение Давайте теперь рассмотрим нормальное распределение более
подробно. Рис.1.7 дает нам поверхностное представление как оно выглядит в
случае с массой выпекаемых буханок хлеба. Принципиальные особенности
этого распределения – оно симметрично и формой похоже на колокол, оно
18

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
19
имеет один перегиб (или вершину). И эта вершина является средней среди
всех переменных.
Тем не менее, не все нормальные распределения абсолютно
одинаковые. Не все они могут представлять собой как веса буханок хлеба (со
средним значением в 500 грамм и разбросом в 10 грамм) и роста взрослых
мужчин (со средним значение 1.75 м и разбросом в 40 см). Все нормальные
кривые имеют одно и тот же количество общих свойств, таких как было
сказано выше, но они еще и отличаются тем, что описывают различные
совокупности данных.
Два фактора, называемых параметрами, охватывают эти
характеристики и они достаточны для различения одной кривой от другой.
Первый параметр называется средним распределения. Несмотря на то,
что мы еще не рассмотрели такой термин как среднее, мы можем им
пользоваться, так как знакомы с ним из нашей повседневной жизни (скажем
среднее из 2 и 4 равно 3). Два нормальных распределений, отличающихся по
этому параметру, имеют абсолютно одну и ту же форму, но расположены в
разных частях вдоль горизонтальной линии оси координат.
Второй параметр – стандартное отклонение. Точное определение этого
понятие будет дано позднее. Оно характеризует разброс или рассеивание
переменной. Другими словами, некоторые переменные группируются тесно
около среднего значения (как скажем у массы буханок хлеба). У этих
распределений небольшое стандартное отклонение. График такого
распределения узкий и высокий. Переменные, которые распределяются в
широких пределах относительно среднего, имеют высокое стандартное
отклонение и кривая для таких переменных низкая и плоская. Рис.1.8
демонстрирует примеры распределений с большим и малым стандартным
отклонением: зарплаты в больнице имеют широкий разброс (от уборщиков
до врачей высокой квалификации), зарплаты в школе характеризуются
меньшим разбросом.
19

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
20
Существует очень важное правило, что для любого нормального
распределения 68% значений переменной лежит в интервале плюс/минус
одно стандартное отклонение. То есть, если мы вернемся к нашим буханкам
хлеба массой 500 грамм и стандартным отклонением в 2 грамма, но 68%
выпекаемых буханок имеют массу 498-502 грамма. Далее, 95% значений
лежит в интервале плюс/минус двух стандартных отклонений. То есть 95%
буханок имеют вес 496-504 грамма. И, наконец, 99% значений лежит в
интервале плюс/минус трех стандартных отклонений. То есть 99% буханок
весит 494-506 граммов.
Пример: Имеется станок, который производит прутки определенной длины.
Было проанализировано 1000 прутков. После измерений выяснилось, что
средняя длина прутка составляет 2.96 см, стандартное отклонение 0.025 см.
Подсчитать, в каких пределах (размерах) лежат 95% всех выпускаемых
прутков?
1.6. Некорректное использование статистики Статистика может быть использована неправильно, если
статистические доказательства представлены таким путем, что они ведут к
неверному заключению. Если привести в пример рекламу, то в Европе
существует специальный орган «Бюро рекламных стандартов», который
20

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
21
защищает публику от неразрешенной рекламы. Но менеджер ничем не
защищен от неправильно поданных ему данных. Неправильные данные
могут быть переданы менеджеру случайно или преднамеренно. Давайте
рассмотрим несколько типичных примеров «неправильных» данных.
1.6.1. Определения Зачастую статистические выражения и переменные не имеют точных
определений. Поэтому можно предположить, что создатель данных
использует другое определение, нежели их пользователь. И используя другое
определение, пользователь может в итоге получить неверный вывод,
проанализировав данные. Скажем, такое термин как «среднее» может быть
интерпретирован по-разному.
Например, в бюро по трудоустройству вы можете найти рекламный
буклет, который зазывает вас работать бухгалтером в фирму и средняя
зарплата в этой фирме $44 200. Исходя из этой суммы, можно заключить, что
это предложение очень заманчивое. Более детальный взгляд покажет нам
несколько иное:
• 3 зам. директора - $86 000
• 8 бухгалтеров - $40 000
• 9 мл. бухгалтеров - $34 000.
Тогда средняя зарплата будет (3*86000+8*40000+9*34000)/20=44200.
Среднее значение будет 40000 (медиана).
Наиболее часто встречающееся значение будет 34000 (мода).
Все эти цифры имеют право быть названными средними. Естественно,
фирма выбрала первую цифру, так как она больше. Но даже если мы будем
знать, каким образом было подсчитано среднее, этой информации также не
будет хватать. Нужно также узнать каким образом получается та или иная
зарплата. Включены ли в зарплату директоров проценты прибыли
предприятия, включены ли туда премии, входит ли туда оплата бензина для
вашей машины, страховка и прочее. И если все это из зарплаты убрать, то
может получиться следующее:
21

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
22
• 3 зам. директора - $50 000
• 8 бухгалтеров - $37 000
• 9 мл. бухгалтеров - $32 400.
И тогда уже средняя зарплата будет $36 880. И выяснится, что
предложение этой фирмы отнюдь не такое выгодное, как казалось с первого
взгляда.
1.6.2. Графика Графика используются в статистике, чтобы оценить данные как можно
быстрее, кинув на них лишь один взгляд.
В статистике используется большое количество графической
информации, главным образом графики. Если шкала на графики не указана,
или указана не точно, то очень просто воспринять данные не так, как
следовало бы. На рис.1.11 представлен график продаж (за три года) одной из
фирм. На первый взгляд фирма развивается успешно.
Однако масштаб на графике не указан. А если указать масштаб, то
график несколько изменится. И неплохо было бы привести цифры. А они
таковы: 1994 – 11250000, 1995 – 11400000, 1996 – 11650000. И если
учитывать инфляцию, то, скорее всего компания уже несет убытки…
22

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
23
1.6.3. Тенденциозность при сборе данных Часто статистические данные собираются в виде выборок, то есть в
виде какой-то небольшой части от общего количества данных. И обычно
заключение, полученное путем анализа выборки, используется и для всей
совокупности данных. Но так можно делать только тогда, когда выборка
действительно может представлять генеральную совокупность, или как
говорят когда выборка «репрезентативна». Если нет, то естественно выводы
могут быть неверными. Есть три пути, по которым можно пойти, чтобы
допустить такого рода ошибку.
Первый путь. Можно не совсем правильно собрать данные. Скажем,
если депутат-коммунист говорит, что 80% писем, которые он получает,
критикуют демократов, то еще нельзя заключить, что большинство людей за
коммунистов или против демократов.
Второй путь. Во время проведения опросов можно поставить
некорректные вопросы и в итоге получить некорректные данные. Скажем, на
вопрос «Регулярно ли вы посещаете стоматолога» многие ответят «Да». Но
что значит регулярно? Один раз в год, в 10 лет или в месяц? Вопросы
должны быть более конкретны.
Третий путь. Ошибки могут появиться и по вине сборщика
информации. Если, скажем, молодой человек будет проводить какой-то
опрос, то наверняка большинство опрашиваемых будут девушками.
Естественно, и результаты окажутся неверными…
Вообще говоря, технология правильного создания выборок весьма и
весьма непроста. Мы еще вернемся к этому вопросу позднее.
1.6.4. Допущения и пропуски в данных Простой пример. Вспомним наших собак и корм ПедиГри. Если в
рекламе говорится, что 9 из 10 собак едят этот корм, то зачастую мы это
воспринимаем, как «90% собак едят этот корм». А ведь мы бы сделали
другой вывод, зная что:
1. Всего было опрошено 10 собак (точнее хозяев).
23

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
24
2. У собаки был выбор есть либо ПедиГри, либо что-то совсем невкусное.
3. Размер выборки был не 10, а 12, и из 12 собак выбрали 9, которые если
этот корм…
1.6.5. Логические ошибки Статистика позволяет делать заключения о числах, которые мы видим.
Однако, числа - это на самом деле какие-то объекты, которые «скрываются»
за этими числами. Существует два пути для совершения логических ошибок.
Во-первых, числа это все-таки не то же самое, что и объекты, которые
они представляют. Например, неудовлетворенность служащего своей
работой иногда измеряется текучестью кадров. Причем изучается первое, а
измеряется второе. Но текучесть не всегда зависит от неудовлетворенности
персонала. Может иметься ряд других причин текучести кадров…
Второе, например, имеется определенная связь между средней
зарплатой священника и ценой на водку. Эти переменные часто изменяются
вместе и это можно легко проследить. Но это не значит, что священник
каким-то образом влияет на цену водки, или водка влияет на зарплату
священника. Дело в другом. Дело в инфляции, именно путем инфляции и
связаны эти две переменные. Да, обе переменные изменяются вместе, но они
не взаимосвязаны.
Для того, чтобы доказать отсутствие взаимосвязи между зарплатой
священника и ценой на водку сделаем следующее. Заморозим зарплату
священника. И что? Водка все равно будет дорожать. Следовательно, связи
нет.
1.6.6. Технические ошибки Ошибки также случаются тогда, когда человек недостаточно понимает
техническую сторону вопроса и потому неправильно производит
вычисления. Простой пример. Использование процентов. Скажем, рост
производительности труда в этом году составил 20%. А в прошлом году
производительность труда упала на 20%. На первый взгляд
24

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
25
производительность труда вернулась на прежний уровень. Однако нет. Если
принять производительность труда 2 года назад за 100%, то она сначала
упала на 20% и стала равной 80%. Потом выросла на 20%, т. е. на 16 единиц
и стала равной 96%. То есть до сих производительность труда не достигла
первоначального уровня.
1.7. Как опознать (или отловить) статистические ошибки
1.7.1. Кто обеспечивает доказательства Можно привести такой пример. Скажем, в суде немаловажную роль
играет то, кто выступает свидетелем. Бомж это или уважаемый в городе
человек. Или если свидетель может извлечь выгоду из того, что он будет
говорить, то к его словам нужно относиться более чем аккуратно.
Опять же, если вернуться к собачьей еде. Если мы слышим от
производителя ПедиГри, что собаки очень любят этот корм, это не значит,
что это правда. Ведь производитель заинтересован в продажах, не так ли?
Вот если бы это сказал независимый эксперт, было бы другое дело…
1.7.2. Откуда получены данные Согласно отчету медицинского госдепартамента Великобритании
средний британец принимает 2.38 ванны в неделю, 20 лет назад это было 1.15
ванн в неделю. Вроде бы источник информации весьма серьезный, но
насколько он надежен?
Откуда эти данные? Наверняка эти данные не результат какого-то
частного наблюдения. Наверняка был проведен опрос людей. Но люди
зачастую говорят неправду, может кому-то было стыдно признаться, что он
редко моется или еще что-то в этом духе… Следовательно, выборка эта
наверняка не совсем верна. И число 2.38 в неделю наверняка на самом деле
завышено. Но, тем не менее, данными можно более или менее пользоваться,
так как и двадцать лет назад люди вряд ли абсолютно честно отвечали на
этот вопрос. Но надо помнить, что 20 лет назад наверняка опрос был
25

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
26
проведен иначе. Было опрошено другое количество людей, были заданы
иные вопросы, может у людей иного социального статуса. Короче,
сравнивать эти результаты надо с большой долей осторожности.
1.7.3. Проходят ли данные простой «тест на здравый смысл»?
Иногда эксперты, серьезно занимающиеся тем или иным вопросом, так
сильно увлекаются своим исследованием, что видят только технические
аспекты своей работы, забывая о самых простых вещах. Обычные же люди
без должного опыта в этой области могут просто неверно понять, о чем же
говорит исследователь.
Например, один ученый исследовал доход в течение всей жизни
какого-либо индивидуума и его продолжительность жизни. И нашел
закономерность, что эти две переменные тесно связаны между собой.
Но ведь простой человек может заключить следующее. Если кто-то
больше живет, то он и заработает за жизнь больше. И потом можно
использовать результаты исследований чтобы сделать обратный вывод - если
кто-то прожил мало, то и заработает он мало. И это тоже будет верно. Но
исследователь так увлекся своим исследованием, что свято верил в то, что
только бедность ведет к более скорой кончине. И не более того.
1.7.4. Совершена ли одна из 6 обычных ошибок? Итак, мы рассмотрели типичные ошибки, которые мы можем встретить
во время проведения статистических исследований. Давайте вкратце
повторим:
1. Двусмысленность определения. Статистический термин (особенно
среднее) может быть использован в разных смыслах.
2. Не обманывает ли нас графическое представление данных. Внимательно
смотрите на шкалы графиков, если их нет – наверняка что-то не так.
3. Тенденциозность выборки – если две выборки сравниваются, можно ли
это делать. Сравнимы ли они?
26

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
27
4. Чего не хватает – может быть у нас нет какой-то информации, без которой
мы не можем сделать правильный вывод?
5. Нет ли логических ошибок – числа не всегда полностью представляют
объекты, которые они описывают. Не всегда кажущаяся тесная
взаимосвязь оказывается верной.
6. Нет ли технических ошибок – правильно ли использовались
определения/техники/методы? Ответы на эти вопросы часто требуют
знаний теории предмета.
1.8. Заключение Цель нашего введения в статистику была двояка. Первая цель была
представить вам некоторые статистические концепции как основа для более
детального изучения предмета впоследствии. Вторая цель была заставить
стать немного скептиками и привнести атмосферу здорового скептицизма
при рассмотрении статистической информации и статистических
доказательств.
В статистике практически любой термин, любой метод может быть
использован неверно. Даже вероятность и распределения можно
использовать неправильно.
Логические ошибки часто делаются при анализе вероятности. Простой
пример – представим себе, что была разослана брошюра-опросник о
маркетинге в разные компании. Из 200 ответов мы узнаем, что 48 компаний
вообще не занимаются маркетингом, а 30 – только образовались.
Какова вероятность того, что этот вопросник будет заполнен только
неспециалистами в этой области:
Вероятность = (48 + 30) / 200 = 39%.
И это не верно! Ведь среди 48 немаркетинговых фирм есть сколько-то,
которые только созданы. И если 10 ответов пришли от не-маркетинговых
фирм и они новые, то:
Вероятность = (48 + 30 – 10) / 200 = 34%.
27
Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
28
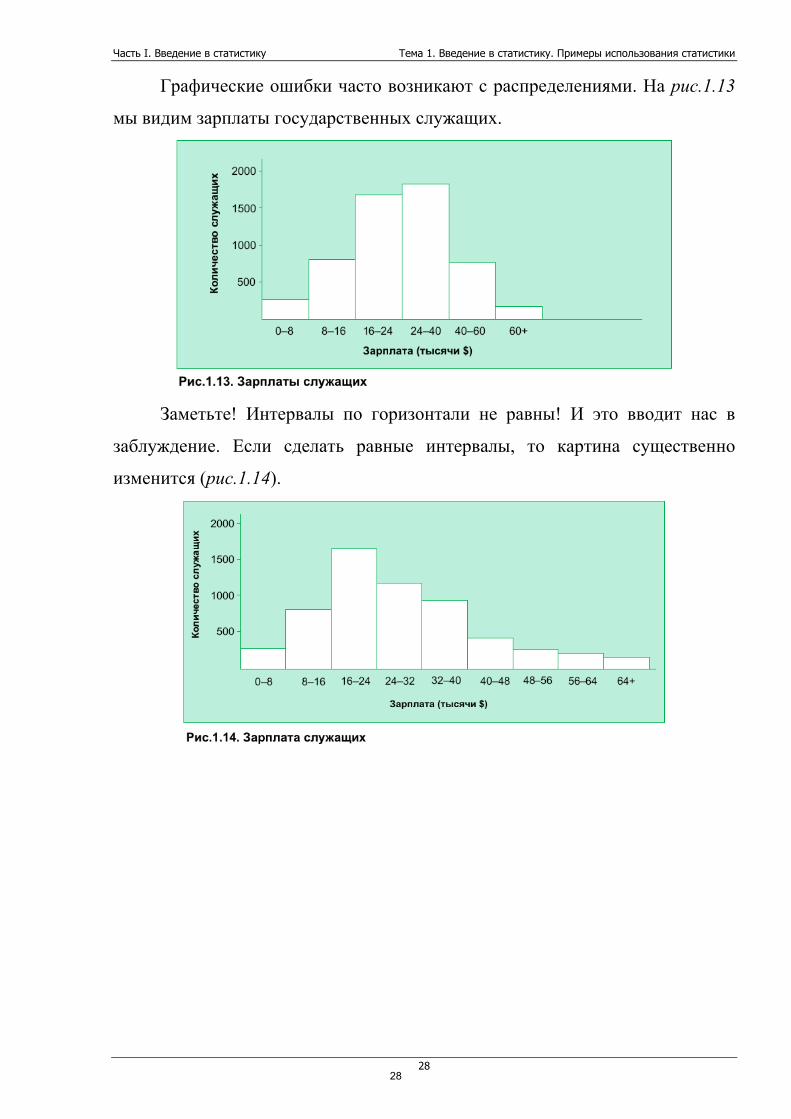
Графические ошибки часто возникают с распределениями. На рис.1.13
мы видим зарплаты государственных служащих.
Заметьте! Интервалы по горизонтали не равны! И это вводит нас в
заблуждение. Если сделать равные интервалы, то картина существенно
изменится (рис.1.14).
28

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
29
Тема 2. Основы математики: школьная математика в менеджменте 2.1. Введение
В этой теме рассматриваются некоторые основы математики и
связанные с этим понятия. Излагаются также некоторые аспекты применения
математики в менеджменте, но главная цель этой темы – подготовить
«математическую» основу для следующих занятий. Лучше уж столкнуться с
«математически» шоком сейчас, чем потом, иначе обилие математики может
оттолкнуть нас от изучения количественных методов вообще…
Вообще говоря, те знания из математики, которые нам могут
пригодиться при изучении статистики, изучаются в школе – это и алгебра, и
геометрия, и тригонометрия. Эти знания включают в себя такие понятия как
график, функция, система уравнений, экспонента. И, несмотря на то, что все
эти понятия весьма просты, тем не менее, они могут создавать для студента
некоторые сложности в их понимании.
Итак, практически все основные математические понятия мы повторим
именно на этом занятии.
2.2. Графическое представление данных
Графика – один из наиболее часто употребляемых методов
представления информации. Например, используя график можно сразу
увидеть:
• уровень продаж какого-то товара за какой-то промежуток времени;
• легко проследить взаимосвязь между двумя переменными – спросом и
предложением (то есть ценой товара и количеством купленных единиц
товара за каждую цену).
Сущность графического представления данных заключается в указании
места положения точки путем указания ее координат. Как и большинство
хороших идей – идея координат очень проста и надежна.
29

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
30
Для примера давайте рассмотрим карту города (см.рис.2.1). Для поиска
како-то улицы мы обычно заглядываем в оглавление карты и находим эту
улицу. Оглавление в итоге нас отсылает к определенной странице карты с
указанием кодового обозначения квадрата, где эта улица находится.
Открывая страницу №52, мы видим, что вся карта разделена на
квадраты. Для того чтобы найти нашу улицу мы смотрим вдоль строки F и
колонки 2. На пересечении этих координат расположен небольшой
прямоугольник, в котором уже не составляет труда найти нужную нам улицу.
Если сказать более общо, то любая точка на графике имеет две
координаты, которые являются горизонтальным и вертикальным
расстоянием от фиксированной точки, называемой «точкой отсчета» или
«центр координат».
Для точки с координатами (3, 2) это проиллюстрировано на рис.2.2.
30

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
31
Эта точка удалена от центра координат по горизонтали на 3 единицы
(горизонтальная шкала называется ось X или ось абсцисс) и на 2 единицы по
вертикали (ось Y или ось ординат). Первое значение обычно обозначается
координатой X и второе координатой Y. И в статистике, и в математике
принято именно такое именование шкал координат.
Далее, из логики вещей мы можем с вами заключить следующее:
1. Центр координат это всегда точка с координатами (0, 0).
2. Двигаясь по оси Y, координата X остается равной 0. И наоборот.
Двигаясь по оси X, координата Y остается равной 0.
3. Оси могут быть продолжены в обе стороны от центра координат.
Следовательно, координаты могут принимать и отрицательные
значения тоже. Когда оси координат идут во все четыре направления,
то систему координат можно разбить на квадранты (см.рис.2.3).
4. Любая точка, расположенная в системе координат, имеет одну и только
одну координату по X и одну и только одну координату по Y.
На рис.2.4 приведено несколько примеров точек, которые находятся в
системе координат. Заметьте, что координаты точек могут принимать не
только целые значения.
31

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
32
Графическое представление данных не ограничивается точками в
системе координат. При помощи графика можно также показать взаимосвязи
между переменными.
Давайте рассмотрим взаимосвязь между прибылью и объемами продаж
некоего товара. Чтобы рассчитать чистую прибыль, мы используем
следующую зависимость:
Прибыль y = (Цена p – Стоимость q) * Количество x.
Первое, что мы сделаем, это заменим символами цену, стоимость и
количество. Итак, x – это количество продаж товара, y – чистая прибыль, p –
цена товара, q – стоимость одной единицы товара. Тогда наше выражение
примет вполне математический вид:
y = (p – q)x (2.1)
Обратите внимание, что умножение может быть показано в формуле
различными методами – это и точка, и знак х, и просто слитное написание. В
статистике знак х не используют, чтобы не спутать его с переменной x.
32

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
33
ВОПРОС:
А) Зачем в алгебре зачастую делают то, что только что сделали мы – то
есть заменяют привычные слова короткими символами? (чтобы сократить
написание сложных формул)
Б) Зачем вместо конкретных значений – 2.5, 16.7 используют символы
(чтобы изучать какие-либо общие параметры и тенденции изменения
переменных).
Итак, формула, которую мы с вами получили, носит название
уравнение. В этом уравнении имеются две константы – это p и q. Ведь они у
нас постоянны и не изменяются. И в зависимости от уровня продаж
переменные x и y могут принимать разные значения. Следовательно, они
переменные. А так как из-за изменения переменной x изменяется переменная
y, то можно сказать, что y является функцией от переменной x.
Если значения констант известны (скажем в нашем случае пусть p=5,
q=3), тогда уравнение примет вид:
y=(5-3)x=2x (2.2)
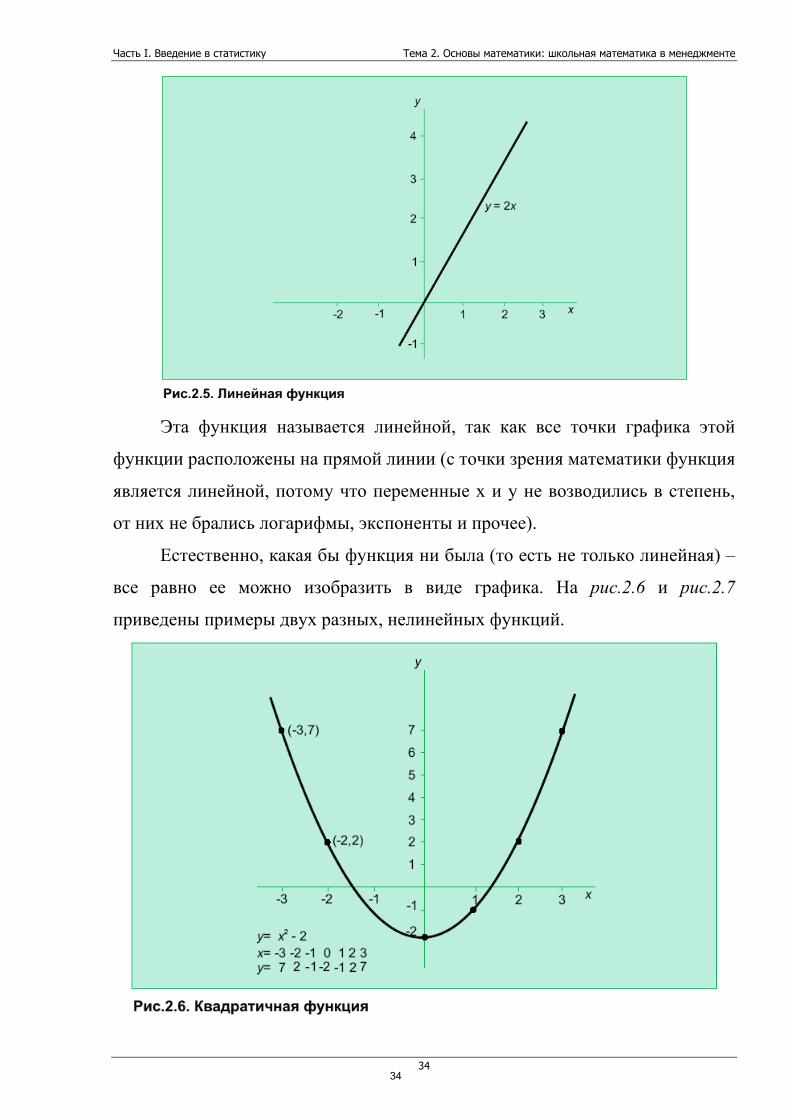
Теперь мы можем, наконец, построить график этой функции. И этот
график будет являться набором точек, которые удовлетворяют условию 2.2.
Например:
Когда х=0, то у=0,
Когда х=1, то y=2
Когда х=2, то у=4 и т. д.
Отметив в системе координат и проведя через них линию, мы и
получим наш график. График функции. На рис.2.5 как раз и отображен
рассчитанный нами график.
33
Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
34
Эта функция называется линейной, так как все точки графика этой
функции расположены на прямой линии (с точки зрения математики функция
является линейной, потому что переменные х и у не возводились в степень,
от них не брались логарифмы, экспоненты и прочее).
Естественно, какая бы функция ни была (то есть не только линейная) –
все равно ее можно изобразить в виде графика. На рис.2.6 и рис.2.7
приведены примеры двух разных, нелинейных функций.
34
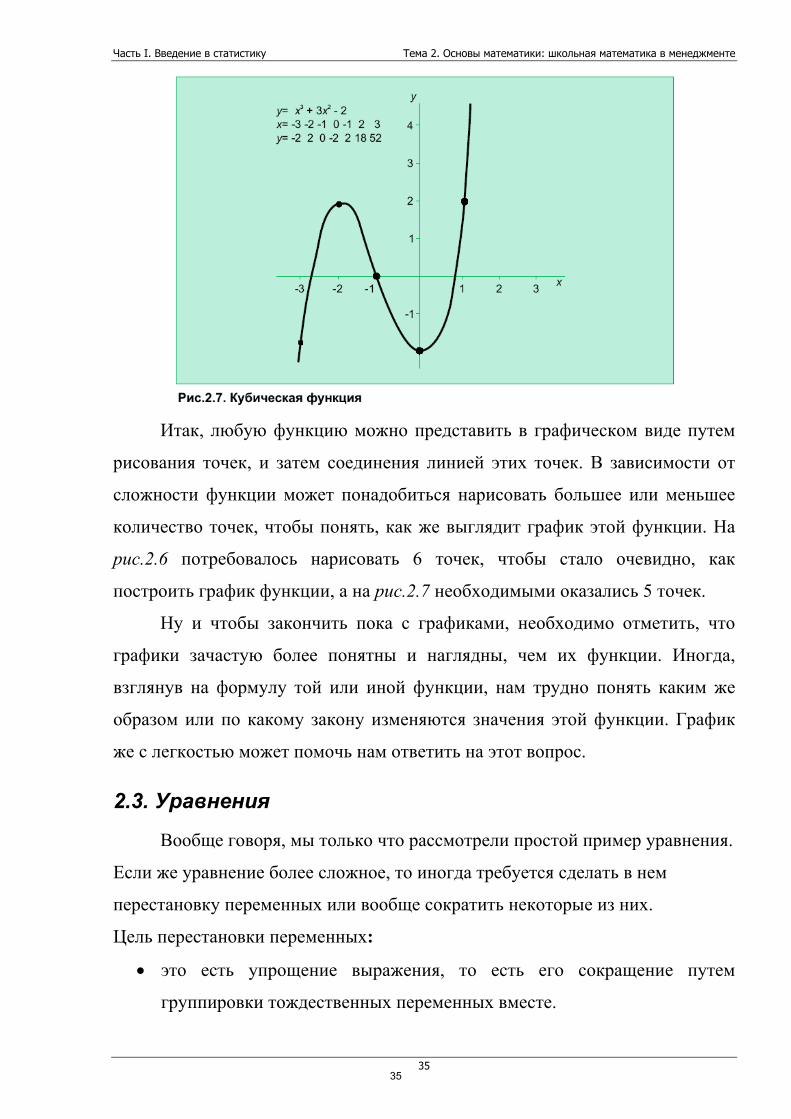
Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
35
Итак, любую функцию можно представить в графическом виде путем
рисования точек, и затем соединения линией этих точек. В зависимости от
сложности функции может понадобиться нарисовать большее или меньшее
количество точек, чтобы понять, как же выглядит график этой функции. На
рис.2.6 потребовалось нарисовать 6 точек, чтобы стало очевидно, как
построить график функции, а на рис.2.7 необходимыми оказались 5 точек.
Ну и чтобы закончить пока с графиками, необходимо отметить, что
графики зачастую более понятны и наглядны, чем их функции. Иногда,
взглянув на формулу той или иной функции, нам трудно понять каким же
образом или по какому закону изменяются значения этой функции. График
же с легкостью может помочь нам ответить на этот вопрос.
2.3. Уравнения
Вообще говоря, мы только что рассмотрели простой пример уравнения.
Если же уравнение более сложное, то иногда требуется сделать в нем
перестановку переменных или вообще сократить некоторые из них.
Цель перестановки переменных:
• это есть упрощение выражения, то есть его сокращение путем
группировки тождественных переменных вместе.
35

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
36
• решение уравнения в целом по какой-то из переменных. Скажем, если
мы сделаем перестановку переменных в уравнении таким образом, что
слева окажется Х=…, а справа все остальное, то мы, по сути, найдем
зависимость переменной Х от всех других переменных выражения.
Скажем, в экономике имеется зависимость продаж товара от изменения
его цены. Такая зависимость называется эластичностью, и ее формула дана у
вас в раздаточном материале после рис.2.7.
Q1 и Q2 – это количество проданного товара по ценам Р1 и P2,
соответственно. И теперь, если мы хотим узнать значение Q2 при известных
остальных значениях, мы должны преобразовать эту формулу в вид Q2=…
После этого мы с легкостью можем провести вычисления.
Существует четыре правила, при помощи которых мы можем
проводить перестановку переменных в уравнениях:
А) Сложение. Если прибавить константу к левой и правой части уравнения,
то получившееся уравнение будет эквивалентно начальному уравнению.
Х – 1 = 2
Х- 1 + 1 = 2 + 1
Х = 3
Х – 4 = У + 1
Х – 4 + 4 = У + 1 + 4
Х = У + 5
Б) Вычитание. Если отнять константу от левой и правой части уравнения, то
получившееся уравнение будет эквивалентно начальному уравнению.
У + Х – 5 = 2
У + Х – 5 + 5 – Х = 2 + 5 – Х
У = 7 – Х
В) Деление. Если каждую из частей уравнения разделить на одно и то же
число (но не на ноль), то результирующее уравнение будет эквивалентно
начальному.
36

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
37
8X = 72
8X / 8 = 72 / 8
X = 9
6X – 3Y – 5 = 2Y – 4X + 5
6X = 5Y – 4X + 10 (добавим 5 и 3Y)
10Х = 5Y + 10 (добавим 4Х)
X = 1/2Y + 1 (делим на 10)
Г) Умножение. Если обе части уравнения умножить на одинаковое число
(кроме нуля), то результирующее уравнение эквивалентно начальному.
Х / 3 = 6
Х = 18
2Y + 3 / 4 – Y = 1
2Y + 3 = 4 – Y (умножаем на 4 – Y)
3Y + 3 = 4 (добавляем Y)
3Y = 1 (отнимаем 3)
Y = 1/3 (делим на 3)
2.3.1. Использование скобок
Скобки в выражении указывают на то, что выражение в скобках
должно рассматриваться как один символ. Например, выражение 2(Y – 4)
значит, что и Y и 4 должны быть умножены на 2:
2(Y – 4) = [2 умножить на Y] – [2 умножить на 2] = 2Y – 8.
Когда одно выражение в скобках умножается на другое выражение в
скобках, то все из первой скобки умножается на все, что расположено во
второй скобке.
Например:
(Х + 3)(Y – 4) =
X * Y +
X * (-4) +
3 * Y +
3 * (-4) =
XY - 4X + 3Y - 12.
ПРИМЕР:
Упростить (Y + 3) / (4 – 3Y) = 4 / (Y – 1).
37

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
38
1) Умножим обе части на (4 – 3Y) и (Y – 1) (Y + 3)*(Y – 1) = 4*(4 – 3Y)
2) Перемножаем скобки Y2 – Y + 3Y – 3 = 16 – 12Y
3) Добавим 12Y, отнимем 16 Y2 + 14Y – 19 = 0
2.4. Линейные функции
Линейная функция от Х эта такая функция, которая имеет только
константы и коэффициент, на который умножается переменная Х.
Линейные функции очень важны в экономике. Не только потому, что
они описывают многие взаимосвязи, но также из-за их простоты и легкости в
использовании. Многие более сложные взаимосвязи могут быть легко
аппроксимированы до линейных функций.
Например, допустим, что у нас есть одна переменная, и она
представляет собой время. Линейная функция в таком случае может
представлять собой рост или спад чего-либо. Скажем, если мы используем
линейную функцию, связывающую время и продажи, то можно из уравнения
этой функции вычислить увеличение или снижение продаж с течением
времени.
Степеней, логарифмов и прочего в таких функциях нет. Если Y
является линейной функцией от Х, то тогда уравнение этой функции будет
иметь форму:
Y = mx + с, (2.3)
где «m» и «с» константы. Точнее «m» - это коэффициент при переменной
«х».
Уравнение (2.3) – это общая форма записи линейной функции.
Альтернативное определение линейной функции может быть
представлено в графической форме. Линейная функция представляет собой
прямую линию, для всех точек этой прямой линии изменение «х» на единицу
приводит к изменению «y» на «m» единиц.
38

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
39
2.4.1. Коэффициент «m» и константа «с»
На рис.2.8 представлен график линейной функции y=2x+1. В этом
примере коэффициент «m» равен 2 и константа «с» равна 1.
Значение «с» - это есть точка пересечения, то есть такая точка
координат, где график функции пересекает ось y. Это легко увидеть, если
подставить в уравнение вместо «х» значение 0.
Значение «m» это наклон линии графика. Иначе этот коэффициент еще
называется градиентом. Этот коэффициент означает отношение между
дистанцией, пройденной по горизонтали и пройденной по вертикали.
На рис.2.8 на графике отмечены две точки – А и В. Их координаты
соответственно (2, 5) и (1, 3). Считаем градиент: пройденное горизонтальное
расстояние 5 – 3 = 2 и пройденное вертикальное расстояние 2 – 1 = 1. Делим
2 на 1, получаем наклон (градиент) равный 2.
Если привести какой-то жизненный пример, то можно придумать
следующее. Если продажи компании описать линейной функцией от времени
с градиентом 3, то по истечении каждого периода времени продажи будут
увеличиваться втрое.
39

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
40
НЕСКОЛЬКО ВАЖНЫХ ФАКТОВ ОТНОСИТЕЛЬНО ЛИНЕЙНЫХ
ФУНКЦИЙ.
А) Наклон (градиент, коэффициент «m») может быть отрицательным. В
таком случае при увеличении значения «х», значение «у» уменьшается. Это
хорошо видно на рис.2.9.
Б) В случае, если коэффициент «m» равен нулю, то график функции будет
параллелен оси X.
В) В случае, если значение «m» бесконечно велико, то график функции будет
параллелен оси Y.
Теперь давайте рассмотрим, как можно построить уравнение для
любой из прямых линий. Существует всего четыре пути, по которым мы
можем пойти, чтобы узнать уравнение той или иной прямой:
1. Значения «m» и «с»
2. Значение коэффициента «m» и координаты любой точки, лежащей на
прямой.
3. Значение константы «с» и координаты любой точки, лежащей на
прямой.
4. Координаты двух точек на прямой.
В случае 1 уравнение находится тривиально. Мы просто подставляем
коэффициенты в общий вид линейной функции. Скажем если m=2 и с=4, то
уравнение линейной функции будет иметь вид y=2x+4.
40

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
41
В случаях 2 и 3 мы получаем уравнение с неизвестным коэффициентом
«m» или «с». Координаты известной точки подставляются в уравнение и оно
решается и мы находим соответственно «с» или «m».
В случае 4 наклон может быть подсчитан по формуле y1-y2 / x1-x2, а
затем мы проводим расчеты как в случаях 2. и 3.
ПРИМЕРЫ:
1. Известен наклон (m=2), прямая графика проходит через точку (3,4). Какое
уравнение?
Y=mx+с то Y=2x+с
Так как (3,4) то 4=6+с то с = -2.
Тогда y=2x-2.
2. Точка пересечения -3. Прямая графика проходит через (1,1). Какое
уравнение?
Y=mx+3
Так как (1,1) то 1=m-3 то m=4
Тогда y=4x-3.
3. Прямая графика проходит через (3,1) и (1,5). Какое уравнение?
1-5/3-1=-4/2=-2 то y=-2x+с
1=-6+с то с=7
Тогда y=-2x+7.
2.5. Системы уравнений
Связи между переменными могут быть описаны при помощи функций.
Например, как мы только что узнали, линейное уравнение может
представлять линейную связь между двумя переменными. Но, между тем,
существуют ситуации, которые описываются одновременно несколькими
уравнениями.
41

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
42
Например, в микроэкономике цена и уровень производства продукта
описываются двумя уравнениями. Первая связь между ценой и количеством
покажет нам число покупателей, которые желают приобрести товар с
казанной ценой. Второе – это взаимосвязь между ценой и количеством
товара, которое продавец желает продать за указанную цену.
Экономическая теория говорит нам, что существует некая точка
равновесия, когда какая-то цена и какое-то количество товара одновременно
удовлетворит и покупателей и продавцов (речь идет о кривой спроса и
кривой предложения).
Так вот это как раз один из таких случаев, в котором системы
уравнений нам могу помочь найти решении.
Представим себе два уравнения с переменными «х» и «у»:
3x+2y=18 (2.4)
x+4y=16 (2.5)
В ходе изучения данного вопроса мы сможем ответить на следующие
вопросы:
1. есть ли такие «х» и «у», которые удовлетворят условиям
одновременно обоих уравнений;
2. есть ли у этой системы уравнений хоть оно решение?
3. может быть таких пар «х» и «у» несколько?
2.5.1. Методы решения систем уравнений
Посмотрите на рис.2.10. График первой функции пересекает оси
координат в точках (0,9) и (6,0). График второй функции – в точках (0,4) и
(16,0).
42

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
43
Значения «х» и «у», которые удовлетворяют обоим уравнениям могут
быть найдены в точке пересечения графиков обеих функций. Так как эта
точка с координатами (4,3) лежит на обоих графиках, то она должна
удовлетворять условиям обоих уравнений. Это можно проверить, подставив
«х=3» и «у=4» в оба уравнения. В нашем случае мы имеем одно, или как
говорят «уникальное» решение системы уравнений. Других, как мы видим,
нет!
С другой стороны, возьмем другой пример: 2x+3y=12 и 2x+3y=24.
В этом случае эти два уравнения противоречивые. Левая часть обоих
уравнений одинакова - 2x+3y. И, естественно, невозможно уравнять левую
часть одновременно с 12 и 24. Давайте посмотрим на графики этих функций.
Они представлены на рис.2.11.
Графики этих двух функций параллельны, и, следовательно, никогда не
пересекаются. А, поэтому, не имеет решения и эта система уравнений!
Есть еще и третий вариант систем уравнений. Возьмем, к примеру,
уравнения x+3y=15 и 4x+12y=60. Если мы построим графики этих функций,
то увидим, что графики полностью совпадают. Следовательно, любая точка
на любом из графиков удовлетворяет условиям обоих уравнений. То есть
имеется бесконечное количество решений этой системы уравнений. Такие
уравнения называются зависимыми или связанными.
43

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
44
ИТАК, решение двух линейных уравнений с двумя переменными
значит поиск точки с координатами, которые удовлетворяют условиям обоих
уравнений. И существует всего три случая решения таких уравнений:
1. есть одна точка пересечения графиков, решение одно и оно уникально.
2. есть бесконечное число решений, уравнения связанные или зависимые.
3. решения нет, уравнения противоречивы.
2.5.2. Алгебраическое решение системы уравнений
В предыдущих примерах мы находили решение системы уравнений
графически. Имеется и неграфический, алгебраический подход к решению
систем уравнений.
Шаг Пример
3x+2y=18
x+4y=16
1. Умножьте одно или оба уравнения
на такое число, чтобы коэффициент
при «х» или при «у» стал одинаков в
обоих уравнениях.
умножаем обе части второго
уравнения на три.
3x+2y=18
3x+12y=48
2. Отнимите одно уравнение от
другого, чтобы все «х» или «у»
исчезли.
отнимаем первое уравнение от
второго
10у=30
3. решите уравнение с одной
переменной.
у=3
4. подставьте ответ в одно из
первоначальных уравнений и найдите
второй коэффициент.
Подставляем «у» в одно из
первоначальных уравнений
3х+2*3=18
3х+6=18
3х=12
х=4
х=4, у=3
44

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
45
ПРИМЕР:
Решить алгебраически систему уравнений: 5x+2y=17 и 2х-3у=3.
2.6. Показательные функции
Показательные функции важны в экономике, так как при их помощи
часто выражают рост или спад (например, увеличение или уменьшение
переменной в заданный период времени).
Давайте попробуем применить показательную функцию к продажам
нового продукта. Скажем, примем за «у» уровень продаж, а за «х» - время.
Если продажи подчиняются линейному закону, то каждый месяц будет
наблюдаться постоянное и одинаковое увеличение уровня продаж, если же
продажи подчиняются показательному (или экспоненциальному) закону, то
каждый месяц мы будем наблюдать постоянное увеличение процента уровня
продаж.
Итак, очередной пример. Предположим, мы положили в банк 1000
рублей. Процентная ставка по вкладу 10%:
• в конце первого года мы получим 1000 рублей + 10% = 1100 руб.
• в конце второго года мы получим 1100 рублей + 10% = 1210 руб.
• в конце третьего года мы получим 1210 рублей + 10% = 1331 руб.
• и т. д.
Заметьте, что каждый следующий год мы получаем +10%, но не от
суммы в 1000 руб., а от суммы + набежавший за год процент. Так вот, рост
наших сбережений как раз и описывается показательным
(экспоненциальным) законом. Посмотрите на рис.2.12.
45

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
46
На графике отчетливо видно как растут наши доходы. Мы видим, что
кривая идет вверх, и с каждым годом все круче и круче. И эта крутизна
зависит от процентной ставки (в нашем случае). Была бы она выше –
крутизна графика тоже увеличилась бы.
Математически, рост нашего благосостояния можно представить так:
• В конце 1-го года: 1000 * 1.10 = 1100
• В конце 2-го года: 1100 * 1.10 = 1000 * (1.10)2 = 1210
• В конце 3-го года: 1210 * 1.10 = 1000 * (1.10)3 = 1331
• …
• В конце года N получаем: 1000 * (1.10)n.
Показательные функции, как видно из этого примера, особенно
интенсивно используются в бизнес-прогнозировании.
2.6.1. Степени
Рассмотрим выражение ах. Основание – это а, степень – это х. Если х -
целое число, то выражение ах имеет очевидный смысл: а2=а*а, а3=а*а*а и т. д.
Но степень также может быть и дробным числом. Вспомним из математики
некоторые правила работы со степенями:
А) Умножение: ах * ау = ах+у.
Б) Деление: ах / ау = ах-у.
В) Возведение в степень: (ах)у = ах*у.
ПРИМЕРЫ:
1. (а4 *а3) / а2
2. 274/3
3. 4-3/2
4. (22)3
46

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
47
2.6.2. Логарифмы
Для работы со степенными функциями также очень полезно может
быть применение логарифмов. В школе и в математике в университете их
используют для умножения и деления больших чисел. Например, если у=ах,
то говорят, что «х» - это логарифм «y» от у по основанию «а». Пишется это
так – logay=x.
ПРИМЕРЫ:
1. log101000
2. log28
Имеются также правила обращения с логарифмами, которые, по сути,
вытекают из правил по обращению со степенями:
А) Сложение: logax + logay = logaxy
Б) Вычитание: logax - logay = loga|x/y|
В) Умножение на константу: с * logay= logayc
2.6.3. Показательные функции как таковые
Общий вид показательной функции выглядит так: y=kacx.
Если вспомнить наш пример с банком на рис.2.12, то здесь «у» - это
наш баланс в конце «с»-того года, «k» - первоначальный взнос, «а» – это 1
плюс процент, предлагаемый банком.
Тогда, в конце трех лет, как вы помните, наш баланс равен:
Баланс=1000 * (1.10)3.
Рассмотрим внимательно константу «с». Если она положительна, то мы
наблюдаем рост переменной «у», если она отрицательна – то «у»
уменьшается. На рис.2.13 представлено оба примера – и экспоненциальный
рост, и экспоненциальный спад.
47

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
48
Еще раз напомню о свойстве показательной функции – если связь межу
«х» и «у» степенная, и наблюдается рост, то при увеличении «х» на какую то
константу, то «у» увеличивается на какой-то постоянный процент (на
рис.2.13, верхний график - мы можем понаблюдать за точками (1,4), (2.8),
(3.16)). Каждый раз когда «х» растет на единицу, «у» увеличивается на 100
процентов.
И также, наоборот, при спаде. Если «х» увеличивается на какую-то
константу, то «у» уменьшается на какое-то постоянное количество
процентов.
Здесь наблюдается отличие от линейной функции, где при увеличении
(уменьшении) «у» на определенную величину, «х» каждый раз увеличивается
(уменьшается) на единицу.
48

Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
49
2.6.4. Связь между линейной и показательной функцией
Общий вид показательной функции как вы помните y=kacx.
Возьмем логарифм по основанию «а» от обеих частей уравнения:
logay=loga(kacx)
Использовав правила логарифмирования к правой части, получим:
logay=logak + loga(acx) (сложение)
= logak + cx * logaa (умножение на константу)
А так как logaa=1, то
logay= сх + константа (2.8)
Поэтому, связь между логарифмом от «у» и «х» линейна (сравним
выражение 2.8 и уравнение прямой линии). И, если «х» и «у» связаны между
собой показательной функцией, то logay и «х» связаны между собой линейно.
Другими словами путем трансформирования (преобразования) показательной
функции логарифмированием мы доказали, что с показательной функцией
можно работать как и с линейной. А это проще. Эти знания нам особенно
пригодятся в регрессионном анализе, которым мы вскоре займемся.
49

Часть II. Обработка числовой информации Тема 3. Представление данных
50
Часть II. Обработка числовой информации
Тема 3. Представление данных
3.1. Введение
На этом занятии мы попробуем научиться улучшать внешний вид
данных. Это важный момент при анализе данных или при передаче данных
другому лицу. Акцент сделан на визуальных аспектах представления данных.
Главным образом внимание будет уделено таблицам и графикам.
Что такое представление данных? По сути, это передача цифровой
информации. Как мы говорили ранее, слова можно использовать неверно,
тем самым, вводя в заблуждение человека. Также и неверно представленные
данные могут ввести нас заблуждение и заставить принять неверное решение
в итоге. Ну а так как в статистике большую часть времени мы тратим именно
на анализ данных, то имеет смысл узнать, какие же приемы используются
для того, чтобы донести данные до человека максимально быстро, просто и
эффективно.
В бизнесе анализируемая информация чаще всего представляется в
двух формах – в таблицах и графиках. Отметим, что главная наша цель
научиться представлять данные таким образом, чтобы они были удобны в
восприятии как человеку, который создает эти данные, так и тому, кто эти
данные будет изучать.
Зачастую, с развитием компьютерной техники, способ представления
данных больше зависит от возможностей программного обеспечения, нежели
от нужд менеджеров, бизнесменов и прочих потребителей информации. С
другой стороны компьютеры могут очень помочь в ускорении создания той
или иной формы представления данных. Мы рассмотрим типичные ошибки,
которые может допустить пользователь ПК при составлении графиков и
таблиц.
50

Часть II. Обработка числовой информации Тема 3. Представление данных
51
Руководствуясь тем, что требования пользователей к представлению
информации являются первостепенными, наша цель узнать, как же данные
могут быть представлены лучше.
А что значит «лучше»? Что скрывается под этим словом?
Давайте рассмотрим типичные случаи, когда и где человек может
встретиться с данными:
• Деловой отчет. Данные в этом случае служат доказательством
выполненной работы, проекта. Такие данные могут включаться прямо в
тело отчета.
• Информационные (компьютерные) системы. Обычно это весьма
большое количество данных, расположенных на экране или распечатке.
Часто получаемые на регулярной основе (квартал, месяц, год).
• Бухгалтерские данные. Для менеджера такие данные являются своего
рода индикатором основных финансовых успехов или неуспехов
организации.
• Данные, которые создаем мы сами, анализируя ту или иную
проблему. Например, мы можем проанализировать все оплаченные счета
за год и построить таблицу, которая содержит информацию, куда и в
каком объеме организация тратила деньги.
Во все перечисленных ситуациях скорость обработки данных является
одной из важнейших проблем. Чаще всего у нас просто нет времени сидеть и
изучать цифровую информацию, которая загромождает нам стол. Данные
должны быть представлены всегда таким образом, чтобы лишь бросив на них
взгляд, мы уже могли составить представление о том вопросе, который мы
изучаем. Пусть не подробно, но суть мы должны уловить практически сразу.
Также мы должны мгновенно видеть, что какая то часть данных серьезно
выбивается из всего набора. Скажем, если какое-то из отделений фирмы
работает из рук вон плохо, это должно быть сразу видно на графике или в
таблице.
51

Часть II. Обработка числовой информации Тема 3. Представление данных
52
Более того, правильное представление данных важно само по себе не
только тогда, когда мы получаем данные от кого-то еще, или когда передаем
кому-то данные. Очень важно и самим научиться подготавливать данные для
себя тоже как можно лучше. Опять же для того, чтобы потом максимально
эффективно с этими данными поработать.
3.2. Правила представления данных
Существует семь методов, которые можно использовать для улучшения
внешнего вида данных, с которыми мы работаем. Не всегда возможно
применять все семь правил к тому или иному набору чисел. В зависимости от
типа данных можно применять то или иное правило, или несколько из них.
Этот набор из семи правил составлен на основе психологических
исследований, которые изучали, как человеческих разум воспринимает
информацию. И если для человеческого разума естественно то или иное
представление данных, то именно таким образом и должны быть
представлены данные, чтобы они наиболее легко, понятно и однозначно
человеком воспринимались.
3.2.1. Правило 1. Округление чисел до двух наиболее значимых цифр
Было экспериментально доказано, что когда человек пытается
анализировать цифровую информацию, то он подсознательно округляет
цифры в уме. Округляет так, чтобы цифры воспринимались более легко.
Чаще всего человек округляет числа до двух наиболее значимых цифр.
Например, если мы попытаемся в уме сосчитать такое выражение:
34.8 / 18.3 то наверняка в уме мы будем считать так
35 / 18 и получим ответ «где-то чуть меньше 2».
52

Часть II. Обработка числовой информации Тема 3. Представление данных
53
Конечно, существует много различных ситуаций – например
инженерные вычисления, бухгалтерский учет и аудит, точные
статистические вычисления – когда округление может быть неуместно.
С другой стороны, округление весьма полезно при оценочных
вычислениях, то есть таких вычислениях, при которых результат не повлияет
на принятие какого-то важного решения, но может повысить читаемость и
доступность информации.
Скажем, если в данных существует некая система, если они
изменяются по некоему закону – то округление легко может помочь эту
систему увидеть, этот закон оценить.
Округление до двух наиболее значимых цифр – процесс немного
творческий. Не всегда округление делается одинаково. Вот несколько
примеров округления (см.рис.3.1).
Рис.3.1.
Эти числа округлены до двух значимых цифр. Если же мы округлим
эти же числа согласно математическим правилам округления до первого
знака после запятой, то результат будет выглядеть примерно как на рис.3.2.
Рис.3.2.
53

Часть II. Обработка числовой информации Тема 3. Представление данных
54
Конечно, округление всех чисел до одинакового количества знаков
после запятой выглядит более правильным, последовательным и логичным,
но не всегда округленные числа становятся более пригодны для
манипулирования или анализа. Округление же чисел до двух значимых цифр
превращает числа в такой вид, который легче воспринимается нашим
разумом. И, поэтому, округленные таким образом числа обрабатываются,
усваиваются нашим сознанием проще.
Но не все так просто с округлениями. Не совсем обычная ситуация
представлена на рис.3.3.
Рис.3.3.
На рисунке представлено несколько весьма схожих между собой чисел.
В данном случае, если мы округлим числа до 1100, 1300, 1500, 1200, 1600 –
то округление окажется слишком сильным. Ведь все эти числа – 1000 с чем-
то. Поэтому в данном случае следует считать значимыми второй и третий
разряды. И именно поэтому справа на рис.3.3 числа округлены до десятков.
Вот почему процесс округления немного творческий.
Многие менеджеры рассматривают округление как какой-то процесс,
ведущий лишь к появлению неточностей. С одной стороны – это правда.
Ведь округление – это всегда потеря точности.
Но, тем не менее, можно задаться и такими вопросами:
• «Будут ли более точные данные влиять на принятие того или иного
решения?»;
• «Не являются ли слишком точные данные подложными или
фальшивыми?»;
54

Часть II. Обработка числовой информации Тема 3. Представление данных
55
Ведь действительно, не всегда же следует уповать на то, что данные,
указанные с точностью 10 знаков после запятой, могут помочь принять то
или иное решение. Ведь вполне возможно, что сама методика сбора данных
не может обеспечить точность, более чем два знака после запятой…
Пример. Скажем, проводился мониторинг бюджета какого-то
предприятия. Анализировались издержки предприятия в течение всего
финансового года. И сравнивались со сметой общих затрат. И здесь есть
место для округлений в сравнении этих двух чисел. Если смета была $15000,
достаточно знать что издержки составили $13000 (числа уже округлены до
двух значимых цифр). Вряд ли, если бы числа не были бы округлены
($12997), было бы принято какое-то другое финансовое решение. Вывод то в
итоге один – издержки на 13% ниже, чем планируемая смета. Даже если бы
суммы были даны в точности до цента, 13% останутся 13%-ю процентами.
И еще одно замечание напоследок. Округление всегда ведет к потере
точности. Поэтому, если мы указываем округленные данные в таблице или
на графике – то абсолютно необходимо где-то внизу делать приписку, что
данные округлены, и где можно взять более точные данные.
3.2.2. Правило 2. Упорядочивание данных Проследить закономерность в данных легче, если данные представлены
в отсортированном виде. Таблица с отсортированными данными будет
выглядеть более организованной, и связь между данными будет лучше
подчеркнута.
Пример. См.табл.3.1.
55

Часть II. Обработка числовой информации Тема 3. Представление данных
56
В таблице перечисляются несколько подразделений компании, их
размер, оборачиваемость капитала и прибыль. Если отсортировать данные в
порядке их размера, то с первого взгляда на таблицу видно, у какой компании
как идут дела. Ведь по идее, чем больше компания, тем больше
оборачиваемость капитала и прибыль. Если же у подразделения проблемы с
прибылью, то мы это сразу отметим (ведь это число будет как бы выбиваться
из списка прибылей). В следующей таблице, табл.3.2, данные отсортированы
по размеру компаний и данные округлены.
Также в этой таблице видно, что восточное отделение компании
выбивается из общей закономерности. Ее прибыль находится выше того, что
по идее должно быть. Ведь ее размер самый маленький, но прибыль больше,
чем у северного и западного отделений.
Естественно, что это было понятно и из табл.3.1. Но это можно было
заметить не мгновенно, нам мешали неокругленные цифры, расположенные в
беспорядке.
А если нам необходимо проанализировать сотни таких таблиц?
Сколько мы потратим времени, вникая в беспорядок каждой таблицы? А ведь
таблицу 3.1. в таблицу 3.2 можно превратить автоматически, на компьютере.
То есть мы можем значительно сократить время на анализ таблиц. А время –
деньги!
Еще один момент. Зачастую данные в таблицах сортируют по
алфавиту. Это может помочь в том случае, если данных в таблице очень
много, и человек вообще не знаком с данными. Но, например, с финансовой
информацией не все так очевидно. Иногда сортировка по алфавиту может
являться барьером к пониманию смысла информации.
56

Часть II. Обработка числовой информации Тема 3. Представление данных
57
В менеджерской деятельности зачастую важно не какое-то конкретное
значение, а тенденция изменения данных. И, конечно, отсортировав данные
по алфавиту, мы эту тенденцию вряд ли сможем заметить. Она просто будет
потеряна.
Более того, менеджеры чаще всего имеют дело с информацией, с
которой они, так или иначе, уже знакомы. Скажем, если анализируются
данные по продажам какого-то товара по штатам США, то данные лучше
сгруппировать в порядке населения этих штатов. И, наверное, мы вправе
будем рассчитывать, что Калифорния будет расположена где-то в начале
списка (ведь это большой штат), а Аляска где-то в самом конце.
3.2.3. Правило 3. Перестановка строк и столбцов Сравнение данных или поиск закономерностей в них проходит легче,
если данные расположены одни под другими, нежели если они выстроены в
ряд. Почему так? Потому что, сравнивая несколько двух-, трех- или
четырехзначных чисел, мы их мысленно отнимаем друг от друга, чтобы
понять какое больше, а какое меньше. А отнимать нам легче тогда, когда
числа записаны столбиком. Видимо, это заложено в нас еще со школьной
скамьи. Ведь в школе нас учат делить, складывать, отнимать, умножать
именно столбиком.
Вернемся к табл.3.2. Данные о размере компаний можно было
представить и в ряд, как вы видите в табл.3.3. Или в столбик, как в табл.3.4.
57

Часть II. Обработка числовой информации Тема 3. Представление данных
58
Несомненно, что анализировать табл.3.4 значительно легче. Тем не
менее, в некоторых таблицах данные, расположенные в рядах, не менее
важны тех данных, которые записаны одно под другим. В таком случае
перестановка столбцов и строк невозможна.
3.2.4. Правило 4. Использование графы «среднее значение» Введение в таблицу и использование такой графы позволяет глазу
сфокусироваться на данных, когда мы рассматриваем таблицу по вертикали
или горизонтали. Имея в таблице такую графу, мы можем, лишь бросив на
нее взгляд, оценить степень разброса данных или сравнить какое-то
конкретное значение из таблицы со средним. Тем самым мы можем оценить,
насколько это значение выбивается из всего набора.
В табл.3.5 представлены данные о количестве рейсов на склад готовой
продукции в течение 20 дней. Среднее значение за эти 20 дней расположено
в правой части таблицы. Имея такое значение, мы можем оценить, насколько
каждый день отличался от среднестатистического дня работы склада. В
данном случае мы видим, что склад работал более-менее стабильно и разброс
значений не велик. Не имей мы такого значения, мы должны были бы
проанализировать все 20 значений. Это бы заняло какое-то время. А если бы
значений было бы 200 или 2000?
Несколько слов о хорошо известной графе «ИТОГО». Конечно, часто в
бухгалтерских документах без нее не обойтись. Но в менеджменте эта графа
зачастую может скрыть от нас истинное положение дел. По графе «ИТОГО»
нельзя проследить тенденций развития какой-то переменной. А чтобы узнать
вклад одной из переменных в графу «ИТОГО» мы уже должны проводить
дополнительные вычисления. А это опять же занимает дополнительное
время.
58

Часть II. Обработка числовой информации Тема 3. Представление данных
59
3.2.5. Правило 5. Сведение к минимуму пустого места и линий в таблице В таблицах в числами нужно стремиться к тому, чтобы в них осталось
как можно меньше линий и пустого пространства. Казалось бы, пустое
пространство в таблице должно выглядеть привлекательно, но в результате
избыток его ведет к снижению возможности наблюдения за
закономерностями в данных. Это происходит потому, что глазу приходится
проходить большие расстояния от одного числа до другого. Поэтому числа
должны располагаться достаточно близко друг к другу. Но, конечно, не до
такой степени, чтобы было трудно разобрать, где какое число есть.
Сетка в таблице (горизонтальные и вертикальные линии) иногда может
мешать глазу двигаться от одного значения к другому. Линии в таблице
лучше использовать лишь для отделения одного типа значений от другого.
Например, отделять графу среднее значение, графу «ИТОГО» от прочих
чисел таблицы.
В табл.3.6 содержатся те же самые данные, что мы анализировали в
табл.3.2. Но в данном случае добавлены большие промежутки между
цифрами и нанесена сетка. Сравните две таблицы – 3.6 и 3.7. Какая
воспринимается легче? По-видимому, все-таки вторая. Хотя мы
использовали в ней тоже какое-то количество пустого места и линии, но мы
не увлеклись этим. И, как результат, данные читаются легче.
59

Часть II. Обработка числовой информации Тема 3. Представление данных
60
Итак, таблицы предназначены для сравнения чисел. Белое
пространство в таблицах и линии привносят в таблицы обратный эффект.
Они обособляют данные и делают сравнение более трудоемким.
3.2.6. Правило 6. Подписи данных в таблицах должны быть понятными, но не избыточными Особое внимание также стоит уделять и маркировке данных (их
подписям), неправильное использование подписей может запутать или даже
отвлечь человека от данных. Несмотря на то, что это очевидно, зачастую
совершаются две общие ошибки.
Первая, создатель таблицы может использовать аббревиатуры или
сокращать подписи в таблицах, если он работает с этой информацией
достаточно давно. Он может полагать, что его сокращения понятны всем, и
часто очень в этом ошибается.
Вторая ошибка, из-за слишком длинных заголовков в таблице может
появиться большое количество пустого пространства между колонками
цифр, просто из-за того, что сами подписи занимают слишком много места.
Заголовки колонок или строк должны быть понятны, и не препятствовать
пониманию данных.
В табл.3.8 отображены данные о предприятиях топливно-
энергетического комплекса Великобритании.
Какие шероховатости мы можем увидеть в этой таблице?
Первое это то, что три последние подписи создают слишком большой
промежуток между первыми двумя подписями и цифрами. В третьей строке
используются сокращения, которые нам абсолютно непонятны.
60

Часть II. Обработка числовой информации Тема 3. Представление данных
61
В табл.3.9 эти ошибки исправлены. Теперь все подписи одинаковой
длины, понятные всем слова сокращены, непонятные – расшифрованы.
Итак, подписи в таблицах должны упрощать понимание данных, а не
усложнять этот процесс.
3.2.7. Правило 7. Написание небольшого словесного вывода Словесной вывод (резюме) может помочь достигнуть нашей цели –
доступного и понятного представления данных, направляя внимание к самым
важным особенностям в данных. Вывод должен быть краток и относится
только к самым главным особенностям конкретных данных, в нем не нужно
описывать какие-то маловажные, второстепенные детали. Даже если эти
детали будут описывать некие аномальности данных. Впрочем, если нет
нужды делать какие-то выводы, то его можно и не писать вовсе.
3.2.8. Пример использования 7-ми правил Давайте рассмотрим реальный пример (см.табл.3.10) и попробуем
использовать изученные нами правила что преобразования таблицы.
На таблице предложена информация о странах и их валовому
внутреннему продукту (ВВП). Изучение этого показателя за прошедшие годы
может помочь экономисту сделать прогнозы на будущее. В таблице указана
информация о многих европейских странах, плюс США и Япония даны для
сравнения.
При анализе этой таблице экономисту могут прийти в голову к
примеру следующие вопросы:
• Насколько отличается экономический рост в Германии и в
Великобритании?
• Насколько вообще отличается ВВП в разных европейских странах?
61
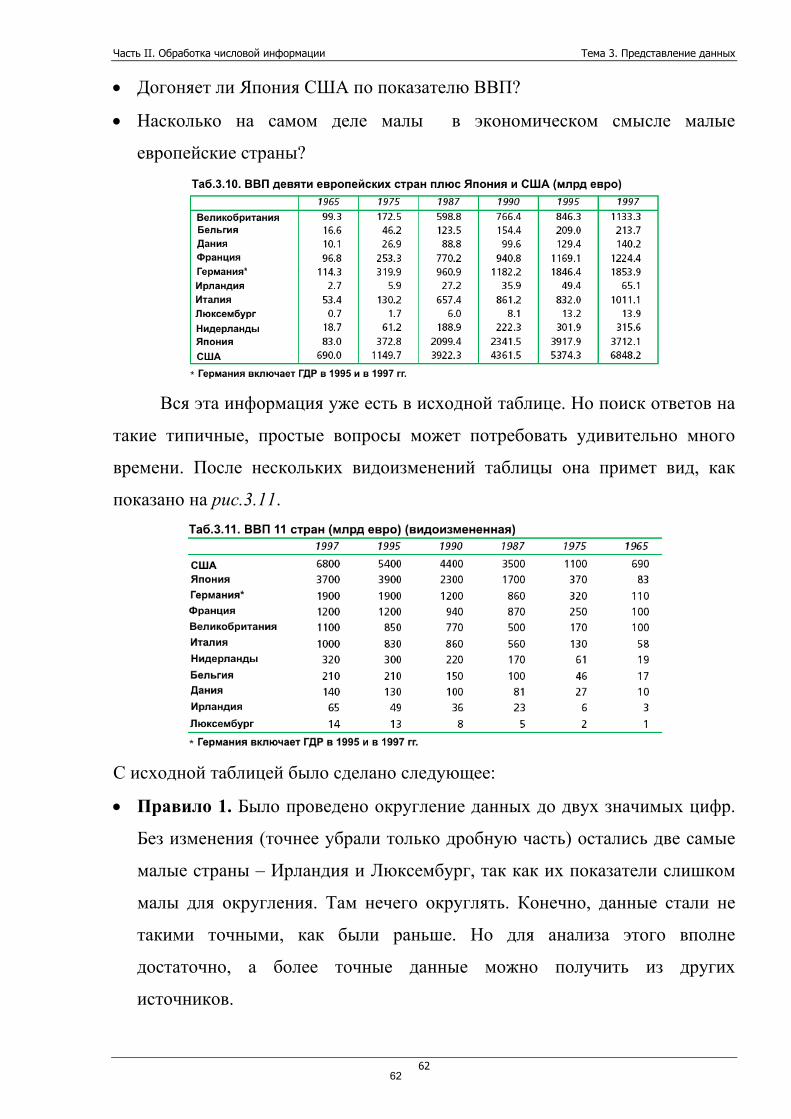
Часть II. Обработка числовой информации Тема 3. Представление данных
62
• Догоняет ли Япония США по показателю ВВП?
• Насколько на самом деле малы в экономическом смысле малые
европейские страны?
Вся эта информация уже есть в исходной таблице. Но поиск ответов на
такие типичные, простые вопросы может потребовать удивительно много
времени. После нескольких видоизменений таблицы она примет вид, как
показано на рис.3.11.
С исходной таблицей было сделано следующее:
• Правило 1. Было проведено округление данных до двух значимых цифр.
Без изменения (точнее убрали только дробную часть) остались две самые
малые страны – Ирландия и Люксембург, так как их показатели слишком
малы для округления. Там нечего округлять. Конечно, данные стали не
такими точными, как были раньше. Но для анализа этого вполне
достаточно, а более точные данные можно получить из других
источников.
62

Часть II. Обработка числовой информации Тема 3. Представление данных
63
• Правило 2. Строки таблицы отсортировали по размеру. Изначально
Великобритания стояла первой (видимо отчет делали в Великобритании) и
США с Японией замыкали таблицу, т. к. они расположены за пределами
Европы. Но этот факт и так всем известен! Алфавитный порядок не
помогал нам понять тенденции в экономическом развитии стран.
Сортировка данных по размеру позволяет нам значительно легче
сравнивать схожие по размерам страны. Также колонки теперь
расположены в обратном порядке. То, что было недавно расположено в
начале, слева, а то, что давно – дальше, справа. Ведь все-таки нас больше
интересует, что было недавно, а не 35-40 лет назад.
• Правило 3. Перестановка строк и столбцов здесь неуместна. Ведь мы
сравниваем страны, а не годы в данном случае.
• Правило 4. Смысла вводить графу «среднее значение» здесь также нет.
Что толку считать средний ВВП с 1965 по 1997 годы? Такое среднее не
несет никакого смысла. Хотя бы из-за инфляции. Также считать средний
ВВП за какой-то год по всем странам бессмысленно.
• Правило 5. Вертикальные линии удалены из таблицы полностью. Это
упростит сравнение значений по годам.
• Правило 6. Подписи данных в таблице весьма понятны и лаконичны:
страны, годы. Изменять здесь нечего.
• Правило 7. В данном случае сделать какой-то короткий словесный вывод
достаточно непросто. Более того, создатели этой таблицы наверняка не
хотели своим выводом заставить поверить нас в какие-то тенденции
данных. Тем более они очевидны и так. В данном случае вывод лучше
сделать самому.
63

Часть II. Обработка числовой информации Тема 3. Представление данных
64
Чего же мы в итоге добились в табл.3.11. Скажем, теперь четко видно,
что ВВП Германии возрос в 17 раз (1900/110), Италии – тоже более чем в 17
раз (1000/58), Японии – почти в 45 раз, Великобритании – только в 11 раз.
Видно также, что по ВВП Япония перегнала Германию, Францию и
Великобританию. Ирландия превосходит по ВВП Люксембург в 4 раза.
Чтобы найти ответы на эти вопросы по табл.3.10, мы потратим значительно
больше времени.
3.4. Представление данных при помощи графиков
Существует такая поговорка, что картинка может сказать тысячу слов
(а в статистике 1000 чисел). Для большинства людей картинки куда
интереснее, чем сухие наборы чисел. График – это тоже картинка, которая
используется в статистике для представления однородных данных. Но не
всегда графики полезны. Очень важно понимать, когда график может
принести пользу, а когда вред.
На рис.3.4. представлен график изменения процентной ставки в США в
период с 1985 по 1996 гг. На первый взгляд с графиком все окей. Тенденции
легко и быстро прослеживаются.
Но если мы попробуем использовать график такого типа для анализа
инфляции в нескольких государствах, то легкость чтения графика быстро
улетучится. Посмотрите на рис.3.5. График такого типа перестает хорошо
работать. Слишком много линий и они часто пересекаются, и в результате
мы не получаем ясной картины что же происходило в этих странах.
64

Часть II. Обработка числовой информации Тема 3. Представление данных
65
Более того, мы даже не можем использовать этот график для получения
какой-то конкретной числовой информации. Попробуйте найти процентную
ставку в Бельгии в 1993 г. То-то и оно, что очень трудно.
Рис.3.5.
Этот пример как раз и иллюстрирует принципы, лежащие в основе
анализа информации через графики. Итак, вот несколько из них:
1. графики полезны, когда:
• нужно привлечь внимание к тенденции развития данных
• когда графиками представлены достаточно простые наборы чисел
2. графики бесполезны или даже вредны, когда:
• когда данные даже слегка сложнее самых простых;
• когда график используется для получения из них числовой
информации.
Как видите, принципы эти более чем просты, и понять эти принципы не
составляет большого труда. Тем не менее, эти принципы нарушаются с
удивительной частотой. Вы только взгляните на рис.3.6. Там видно
несколько графиков, которые соответствуют нескольким разным странам.
65
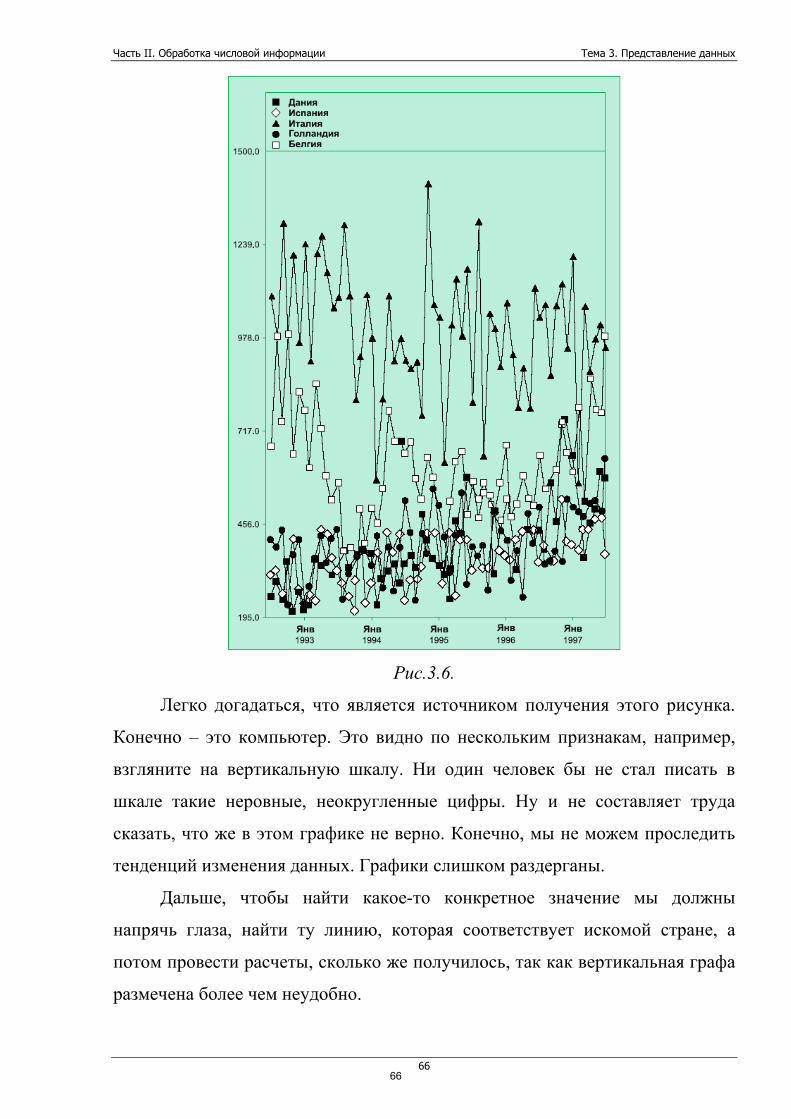
Часть II. Обработка числовой информации Тема 3. Представление данных
66
Рис.3.6.
Легко догадаться, что является источником получения этого рисунка.
Конечно – это компьютер. Это видно по нескольким признакам, например,
взгляните на вертикальную шкалу. Ни один человек бы не стал писать в
шкале такие неровные, неокругленные цифры. Ну и не составляет труда
сказать, что же в этом графике не верно. Конечно, мы не можем проследить
тенденций изменения данных. Графики слишком раздерганы.
Дальше, чтобы найти какое-то конкретное значение мы должны
напрячь глаза, найти ту линию, которая соответствует искомой стране, а
потом провести расчеты, сколько же получилось, так как вертикальная графа
размечена более чем неудобно.
66
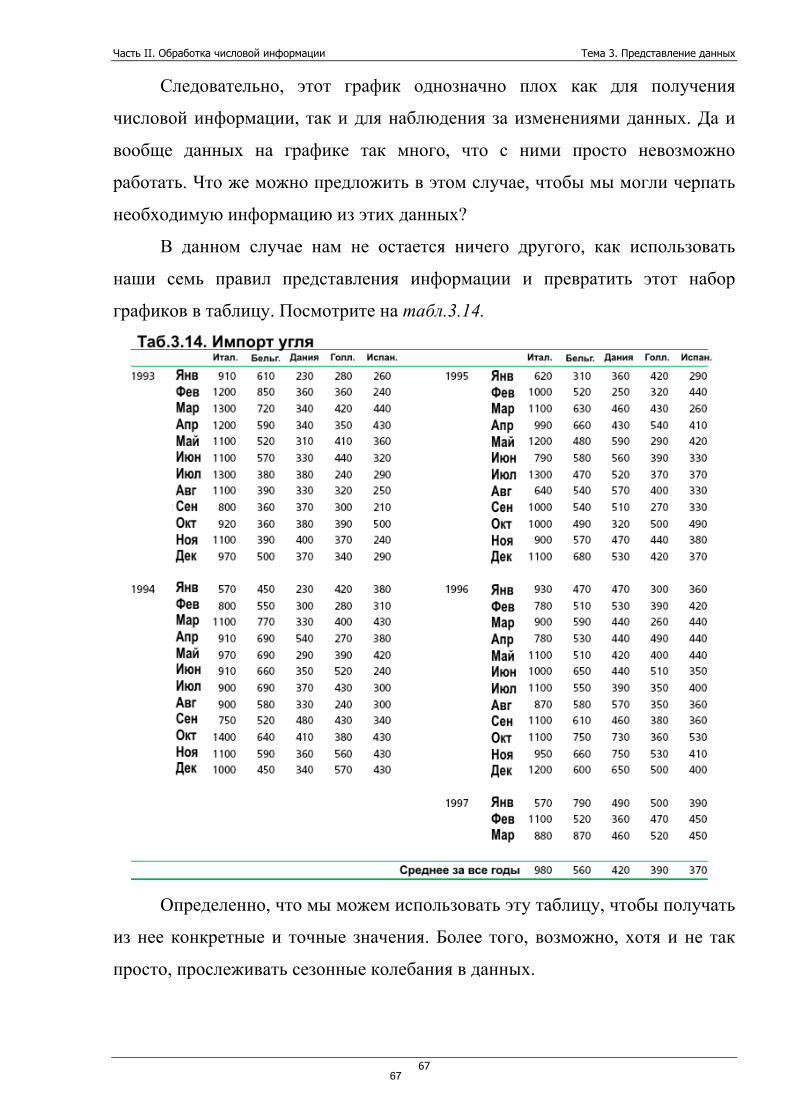
Часть II. Обработка числовой информации Тема 3. Представление данных
67
Следовательно, этот график однозначно плох как для получения
числовой информации, так и для наблюдения за изменениями данных. Да и
вообще данных на графике так много, что с ними просто невозможно
работать. Что же можно предложить в этом случае, чтобы мы могли черпать
необходимую информацию из этих данных?
В данном случае нам не остается ничего другого, как использовать
наши семь правил представления информации и превратить этот набор
графиков в таблицу. Посмотрите на табл.3.14.
Определенно, что мы можем использовать эту таблицу, чтобы получать
из нее конкретные и точные значения. Более того, возможно, хотя и не так
просто, прослеживать сезонные колебания в данных.
67

Часть II. Обработка числовой информации Тема 3. Представление данных
68
Если же требуется проследить тенденцию за годы или сравнить страны,
то лучше воспользоваться табл.3.15. На ней хорошо видно среднегодовые
значения, также хорошо видно, что все страны, кроме Италии в той или иной
степени увеличивали импорт. Только в Италии импорт снижался. Также
легко сравнить импорт по странам.
А вот теперь табл.3.15 можно превратить в понятный график. Он
показан на рис.3.7. Графики очень понятны, не так путаны, как раньше. Но
еще раз напомню, что если из таблицы мы можем легко почерпнуть
необходимые числовые данные, то график нам в этом вряд ли поможет. Если
на графике мы можем быть уверены о направлении изменения переменной
(увеличение или уменьшение), то на таблице мы берем конкретные данные.
Рис.3.7.
Что же в итоге получается? Получается, что графики являются одним
из самых важным способов графического представления информации, но
существуют также и другие графические методы – гистограммы, диаграммы
и прочее. Эти методы также имеют свои преимущества и недостатки.
Принципы их построения весьма схожи с графиками. Картинки, как мы уже
поняли, очень полезны для привлечения внимания и наблюдения за
развитием данных.
68

Часть II. Обработка числовой информации Тема 3. Представление данных
69
3.5. Заключение
В заключение отметим следующее. Зачастую люди, занимающиеся
количественными методами, пренебрегают такими очевидными средствами
преобразованиями данных, так как считают, что делать это слишком просто.
И думают, что только сложные вещи могут быть полезны.
Но, не смотря на такую техническую простоту, сложностей и вопросов
тут возникает немало. Вот несколько из них, о которых мы всегда должны
помнить:
• что за аудитория будет пользоваться данными?
• зачем вообще нужны эти данные?
• насколько мы можем пренебрегать точностью данных, чтобы это не
повлияло на принятие решения?
• не изменило ли нам чувство вкуса, когда мы рисовали графики или
гистограммы?
• и много других…
Напомню семь правил представления данных, которые мы сегодня с
вами рассмотрели:
• Правило 1. Округление чисел до двух наиболее значимых цифр
• Правило 2. Упорядочивание данных (сортировка)
• Правило 3. Перестановка строк и столбцов
• Правило 4. Использование графы «средее значение»
• Правило 5. Сведение к минимуму пустого места и линий в таблице
• Правило 6. Подписи данных в таблицах должны быть понятными, но
не избыточными
• Правило 7. Написание небольшого словесного вывода
69

Часть II. Обработка числовой информации Тема 3. Представление данных
70
Конечно, естественно то, что создатели данных уже привыкли
представлять их в своем собственном стиле. И конечно заставь мы их
использовать хотя бы эти 7 простых правил, наверняка встретим некое
сопротивление. Скажем, идея округления очень нелегко принимается
многими людьми.
Вы только посмотрите! Округлить 1005 до тысячи человек боится, а
вот построить график – так это «пожалуйста», это идет на ура. Хотя на
графике значения 1000 и 1005 вряд ли будут отличаться. А ведь графики –
это и есть суть округление. Не правда ли?
Почему для нас так важна тема представления данных? Дело в том, что
компьютеры начинают участвовать в нашей жизни все сильнее и сильнее. И
польза от компьютеров просто неоценима. Но не бесконечна. Количество
информации, циркулирующей в организации, возросло просто неимоверно.
Да и бумаги стало больше. Почему так? Потому что люди считают, что чем
больше информации, тем лучше. Тем больше пользы мы получим. К
сожалению, это совсем не так. Большое количество информации приводит
лишь к дополнительным сложностям и проблемам. Мы уже говорили сегодня
об этом. Когда приводили загруженный данными пример. Тольку от него
было мало.
Отсюда последний наш сегодняшний вывод – если информацию можно
быстро усвоить и понять, она будет использована и принята к сведению.
Если нет – то нет.
70

Часть II. Обработка числовой информации Тема 4. Анализ данных
71
Тема 4. Анализ данных
4.1. Введение
Сегодня мы узнаем, как систематически подходить к анализу данных.
Изучаемая методология весьма проста, основана в большой степени на
визуальном аспекте интерпретации данных. Но, тем не менее, она подходит
для большинства задач, которые могут встать перед менеджером.
Так из каких же составных частей состоит успешных анализ данных?
Очевидно, что этот вопрос не так и прост. Скажем, если дать таблицу с
данными группе менеджеров и попросить ее проанализировать, вероятнее
всего они выберут некоторые данные из таблицы. Те данные, которые
находятся в середине таблицы и которые подтверждают их давно
устоявшиеся взгляды на изучаемый предмет.
Если это данные, которые говорят о прибыли предприятия, то вполне
вероятно, что менеджер скажет следующее – «Я вижу, что западное
отделение компании заработало $220 000 в прошедшем году. Я всегда Вам
говорил, что новая система контроля себестоимости должна прекрасно
работать, и она работает!».
Но не всегда такой вывод верен. Иногда можно в шутку сказать, что
человек использует статистику так же, как и пьяница использует фонарный
столб, больше для поддержания равновесия, нежели для освещения».
Так вот, настоящий анализ данных, это использование статистики по
прямому предназначению – для освещения, а не для поддержки, или не для
защиты от больших наборов чисел. Анализ – это поиск сущности данных.
Поэтому успешный анализ данных должен включать в себя получение
фундаментальных закономерностей, тенденций в данных и выискивание
истинной информации из данных. И этот анализ должен быть проведен
до того, как делаются какие-либо серьезные умозаключения о каких-то
отдельных данных.
71

Часть II. Обработка числовой информации Тема 4. Анализ данных
72
И для того, чтобы действительно с уверенностью можно было
заключить «а так ли уж полезна новая система расчета себестоимости?», мы
должны проследить закономерности изменения этой себестоимости во всех
отделениях компании, и проанализировать прибыли всех этих отделений
после введения этой системы.
Цель нашей сегодняшней лекции, продолжая наш шутливый пример
про пьяницу, приобрести определенные навыки и научиться методам
«освещения» наборов цифр.
Нами будут изучены 5 шагов, которые могут помочь нам получать
реальную информацию из данных, конечно, если такая информация в этих
данных имеется. Эти шаги создают своеобразную систему взглядов,
придерживаясь которой мы можем с большой степенью вероятности
добиться успеха.
Вам наверняка известно, что статистика была разработана отнюдь
не для применения ее в бизнесе. Она скорее была предназначена для
использования в других областях, скорее всего в естествознании. Перенося
же статистику в область бизнеса, образуется некий промежуток между тем,
что статистика может предложить, и тем, что от нее требуется в этой области.
И зачастую, экономисты, менеджеры, прочитав пару книжек о статистике,
или прослушав какие-то статистические курсы, чувствуют, что им не хватает
чего-то. Что, несмотря на свои знания, они не могут добраться до сути
(корня) какой-то задачи, которая перед ними стоит.
На этом занятии мы как раз и попытаемся заполнить этот промежуток
определенными знаниями, теми знаниями, которые связывают классическую
статистику и её деловое применение.
72

Часть II. Обработка числовой информации Тема 4. Анализ данных
73
4.2. Задачи менеджера в анализе данных
Бизнесмен (менеджер) ежедневно встречает на своем пути уникальные
задачи, главная проблема в которых состоит в понимании числовой
информации, в правильной ее интерпретации. Мы с вами часто это можем
наблюдать по тем неверным решениям, выводам, которые компании иногда
делают (пример о слишком частых реформах в России, школьная реформа).
Очень часто при анализе данных игнорируются источники информации,
которые могут весьма серьезно повлиять на вынесение того или иного
решения.
И первый наш шаг – это осознание того факта, что такая проблема
существует. Эта проблема включает в себя следующее:
• Несовершенство статистики как таковой. Предмет «статистика» не
обладает всеми методами и технологиями, которые хотел бы иметь под
рукой при анализе данных бизнесмен, менеджер. Например, большая
часть статистики посвящена скрупулезной проверке гипотез. Менеджер
же, получив данные о (например) продажах, сначала эту гипотезу должен
построить, или же, другими словами, понять, что же реально кроется за
наборами чисел. Статистика ему может мало в чем помочь. Найдя же
какую-то закономерность, тенденцию в данных менеджер вряд ли должен
быть сильно озабочен скрупулезной проверкой данных, ему необходимо
принимать решение! Несомненно, он проверит достоверность
предоставленной ему информации, но сделает он это не количественными,
а качественными методами. В этом есть большое отличие от естественных
наук. Там мы тратим очень много времени именно на основательную
проверку полученных экспериментальных данных. Как видим, статистика
в бизнесе играет несколько иную роль, чем в других науках, областях
человеческой деятельности. Итак, первая проблема – это то, что
классическая статистика не располагает техниками и методами, которые
нам нужны.
73

Часть II. Обработка числовой информации Тема 4. Анализ данных
74
• Недостаток доверия, некомпетентность. Это проблема проявляется в
разных формах, с одной стороны это вообще боязнь чисел, с другой
стороны – это слишком агрессивный настрой, что менеджмент и бизнес в
целом – материи весьма инстинктивные, и никакие методологии при
анализе информации здесь неприменимы. Результат обычно один –
данные должным образом не анализируются. Хотя чаще всего, как вы уже
успели заметить, требуется отнюдь не много знаний для работы с
числами, зачастую в первую очередь требуется наличие здравого смысла,
логики. Анализ данных даже несколько схож с чтением. Читая деловой
отчет, мы делаем это внимательно, работаем и думает только над тем, что
автор пытался сказать, и, затем, решаем – прав он или нет. Тоже и с
данными. Данные должны быть «просеяны», осмыслены и взвешены.
Чтобы это сделать успешно, очень неплохо применить к данным те 7
правил, которые мы с вами недавно изучили. И очень часто нет нужды
проводить потом какие-то сложные математические вычисления. Знай
люди о том, что с данными можно работать как с текстом, многие могли
бы более успешно работать с числами, таблицами, графиками.
• Чрезмерное усложнение анализа. Поведение экспертов, специалистов в
области анализа данных, может зачастую смутить нас. Эти эксперты
используют жаргон, который совсем не плох, когда они общаются между
собой. Они прибегают к использованию сложных методов, когда
существуют совсем простые, они предоставляют результаты в чересчур
запутанном виде, мало думают о пользователях их отчетов, результатов.
Например, немудрено получить от такого эксперта проанализированные
данные в виде громадных, неудобоваримых таблиц с числами, имеющими
5 знаков после запятой. Да, все данные там верны до последнего знака. А
результат можем быть совсем иной. Эти эксперты как бы воздвигают
стену между ними и теми проблемами, которые они решают. И
соответственно между ними и нами. В итоге получается что?
74

Часть II. Обработка числовой информации Тема 4. Анализ данных
75
В штате компании могут держать большого ученого, который собаку съел
на статистике, но его услугами редко пользуются. Потому что они говорят
с ним на разных языках.
4.2.1. Некоторые примеры Следующие примеры показывают, как эксперты могут переусложнить
представление или анализ данных. И в каждом случае простая обработка
данных открывает нам новые, важные детали.
Пример 1. Из прошлой темы вы помните, как мы работали с табл.3.10.
Там содержались данные о ВВП европейских стран. Лишь слегка обработав
данные, мы построили новую таблицу, табл.3.11, на которой тенденции
изменения данных, закономерности были видны, в отличие от табл.3.10,
невооруженным взглядом.
75
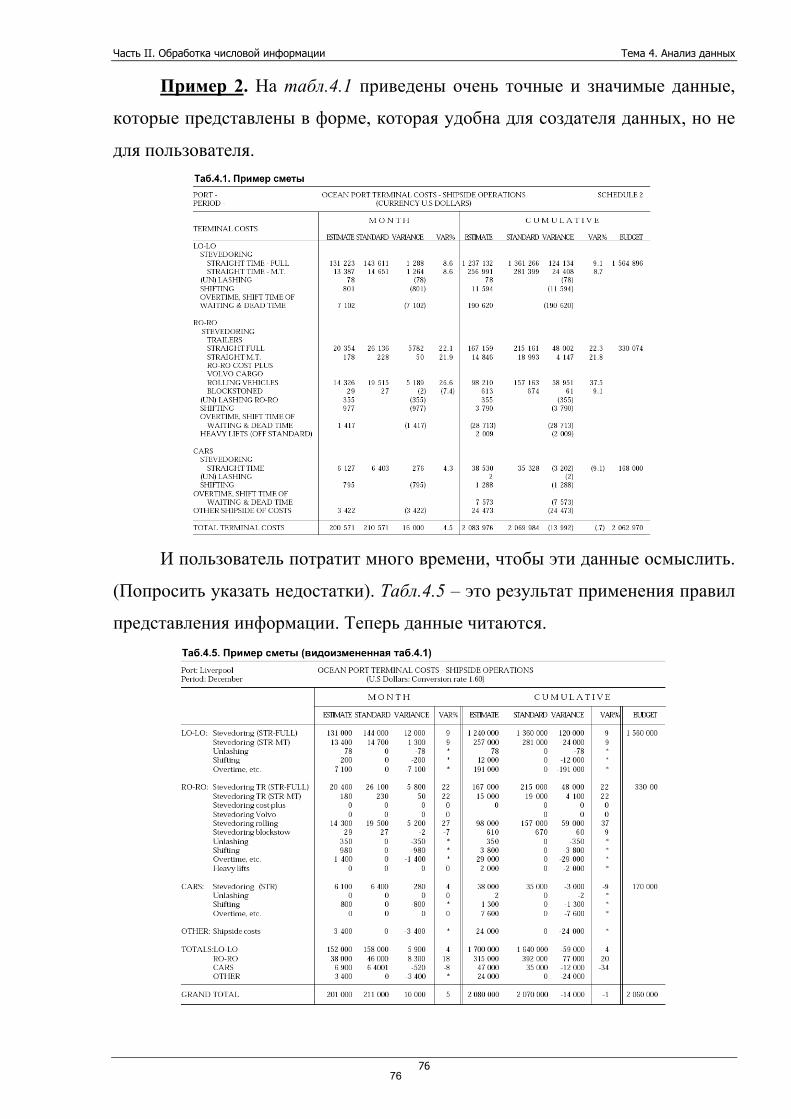
Часть II. Обработка числовой информации Тема 4. Анализ данных
76
Пример 2. На табл.4.1 приведены очень точные и значимые данные,
которые представлены в форме, которая удобна для создателя данных, но не
для пользователя.
И пользователь потратит много времени, чтобы эти данные осмыслить.
(Попросить указать недостатки). Табл.4.5 – это результат применения правил
представления информации. Теперь данные читаются.
76

Часть II. Обработка числовой информации Тема 4. Анализ данных
77
Пример 3. Пример на табл.4.2 показывает, как можно до такой
степени переусложнить таблицу, что станет невозможным извлечь из нее
хоть какую-то информацию. О чем речь? Было опрошено 700 человек в
Великобритании об их пристрастиях в плане просмотра различных передач
по ТВ. По сути, анализировались очень простые данные. Ну что тут
сложного? Но, к сожалению, по данной таблице понять что-либо о
пристрастиях нам невозможно.
Итак, во всех трех примерах закономерности в данных были освещены
очень слабо. Эти данные были созданы бухгалтерами, компьютерщиками и
специалистами в математической статистике. Но как видите, не смотря на то,
что все они были наверняка специалистами, они не смогли нам помочь. Что
нам остается делать? Взять обработку информации в свои руки, больше
делать нечего.
4.3. Руководство по анализу данных
Анализ данных состоит из 5 основных стадий. Человек, следующий
этим стадиям, будет в состоянии понять числовую информацию лучше и
быстрее. Но конечно эти пять шагов, пять стадий не гарантируют, что мы в
итоге достигнем успеха. Это лишь инструмент, но не более чем.
4.3.1. Стадия 1. Уменьшение количества данных Многие таблицы содержат слишком много значений. Данные
включаются часто в таблицы по принципу «возможно, это когда-то кому-
нибудь может пригодиться…».
77

Часть II. Обработка числовой информации Тема 4. Анализ данных
78
И ради этих мифических людей, для которых мы предусмотрительно (в
кавычках) добавляем дополнительные данные, остальные будут тратить
время на то, чтобы отделить реально необходимые, важные данные от
второстепенных, или даже вообще не относящихся к делу.
Немудрено то, что создатель данных должен обеспечить выполнение
многих требований, которые предъявляют пользователи данных. Но, тем не
менее, создатели данных зачастую заблуждаются и перегружают таблицы
данными. Они стараются включить столь много данных, предполагая, что
круг пользователей будет весьма широк. Этот эффект перегрузки данными
может еще возрасти и от того, что сам пользователь может попросить
включить еще «пару столбцов на всякий случай».
Итак, первая стадия анализа – это уменьшение количества числовой
информации. То есть исключение тех данных, которые являются
избыточными или несущественными. Конечно процесс этот сложный и
иногда спорный, но в таком случае важно не полагаться на такой странный
принцип, что если данные были включены в таблицу, то значит, это зачем-то
было нужно. Или что данные важны, раз их уже включили в таблицу.
Создатель данных не всегда знает, что вам нужно, а что нет (да и откуда ему
знать?). Может быть они включены, просто потому, что они были ему легко
доступны и только…
4.3.2. Стадия 2. Изменение представление данных Как мы уже знаем, визуальное представление данных является одним
из ключевых в процессе понимания информации. Мы знаем, что тенденцию
легче заметить, когда данные правильным образом расположены. Если по
таблице не сделано никакого вывода, зачастую мы тратим время на то, чтобы
сделать это самостоятельно.
И вообще, хорошо представленные данные напоминают хорошо
поставленный голос, который использует правильную, литературную речь.
78

Часть II. Обработка числовой информации Тема 4. Анализ данных
79
Само собой, понять такой голос проще, чем невнятный, да еще и
сыплющий жаргоном. Но раз за разом мы наблюдаем, что такой простой
вещью пренебрегают и специалисты и простые люди.
С другой стороны, увлекшись красивым оформлением, можно также
потерять закономерности и тенденции. Поэтому не значит, что
«красивенькая» таблица нас может спасти. Упаси нас бог так думать.
Конечно, красивая таблица предпочтительней неопрятно составленной, но
суть представления данных не красота, а быстрое и правильное восприятие
информации.
Мы уже весьма детально рассмотрели эти рекомендации, напомню их
еще раз:
• Правило 1. Округление чисел до двух наиболее значимых цифр
• Правило 2. Упорядочивание данных (сортировка)
• Правило 3. Перестановка строк и столбцов
• Правило 4. Использование графы «среднее значение»
• Правило 5. Сведение к минимуму пустого места и линий в таблице
• Правило 6. Подписи данных в таблицах должны быть понятными, но не
избыточными
• Правило 7. Написание небольшого словесного вывода.
4.3.3. Стадия 3. Построение модели «Построение модели» звучит как какой-то математический, и, причем
не самый простой термин. Это как раз та стадия, которая может привести
аналитика к излишне сложному техническому и математическому решению
задачи. Цель построения модели – это поиск закономерности в данных и
некий путь резюмирования этого. Модель может быть и словесной, и
арифметическим выражением, также она может быть простой или сложной.
На самом деле, простые модели оказываются наиболее эффективными. И
даже на этой стадии, казалось бы, самой сложной и требующей многих
знаний, можно найти элементы творчества.
79

Часть II. Обработка числовой информации Тема 4. Анализ данных
80
Следующие примеры являются очень разными моделями, но, тем не
менее, они прекрасно подходят для тех процессов, которые они описывают:
• все средние по строкам равны, но имеется вариация в пределах ±20% в
каждой.
• реальная прибыль увеличилась на 5 центов на акцию в период с 1985 и
1990 гг., но снизилась на два цента в период с 1991 по 1996 гг.
• продажи примерно равны у каждого менеджера по северному отделению,
продажи северных и южных менеджеров также примерно равны, но
прибыль северного отделения компании на 25% выше южного.
• колонка 1 (ось y) связана с колонкой 2 (ось x) по закону y=2x+3.
Принципиальная польза от модели заключается в том, что несколько
чисел или слов могут использоваться вместо большого количества числовых
данных. Если модель хороша, то ее вполне можно использовать как
небольшой словесный вывод. Ее можно использовать для поиска
исключений, для сравнений, и даже для принятия решений.
Громадное количество информации, доступное теперь людям (главным
образом из-за широкого применения компьютерной техники) должно
заставлять нас при рассмотрении моделей или закономерностей изменения
данных искать самые простые из них. На сложные модели нам просто может
не хватить времени.
С простыми моделями проще работать. Конечно, тут можно возразить
– простые модели слишком теоретические, и не имеют ничего общего с
нашим весьма непростым миром. Но вспомните – закон Ньютона или закон
Ома. Разве они сложны? Может, они и не учитывают всех нюансов реальной
жизни, но они работают! И при помощи этих законов мы можем предсказать
поведение чего-либо на общем усредненном уровне. Так вот, такой принцип
подходит и здесь. Нам редко нужно вдаваться в детали.
80

Часть II. Обработка числовой информации Тема 4. Анализ данных
81
Но уж если не один из простых подходов не подходит, тогда можно
использовать и более сложные методы. И даже воспользоваться помощью
экспертов. И потом, даже для набора случайных чисел можно построить
модель! Скажем, в любом компьютере есть генератор случайных чисел. Так
что не нужно усложнять! «Все гениально просто».
4.3.4. Стадия 4. Исключения Как только мы установили некую закономерность в данных, имеет
смысл посмотреть, нет ли в наших данных исключений. А в некоторых
ситуациях исключения могут быть даже более важными, чем сама
закономерность.
Например, если рассмотреть продажи какой-то компании в месячный
период, возможно, будет прослеживаться закономерность, что продажи в
каждом из ее подразделений примерно равны, за исключением отделения Х,
в котором продажи значительно ниже. И вот это исключение и имеет смысл
более тщательно изучить.
Почему это случилось? Потому что в этом регионе живет меньше
людей? Просто потому, что руководство отделения плохо работает? Быть
может это ошибка в данных? (Кстати последний вопрос надо задавать себе
всегда, когда мы видим исключение из правил).
Когда исключение замечено, оно может так или иначе быть
скорректировано, игнорировано или на основе этого исключение мы должны
предпринять какие-либо действия.
Главная ошибка, которую допускают многие – это изучение
исключений еще до того, как определена тенденция в данных. Это конечно
неправильно, нелогично. Мы можем какие-то необычные цифры принять за
исключение, тем самым, упустив настоящие исключение. В итоге анализ
данных будет проведен неверно, и опять же, выводы будет сделаны
неправильно.
Также может возникнуть следующая ситуация. Количество
исключений в наборе данных может быть настолько большим, что
81

Часть II. Обработка числовой информации Тема 4. Анализ данных
82
единственное заключение, которое можно сделать будет звучать примерно
так – «данная модель недостаточно хорошо описывает данные». Она не
объясняет такое количество флуктуаций, возникающих в наборе чисел. В
таком случае можно сказать, что большое количество исключений
опровергают выбранную модель, и нам остается лишь вернуться к данным и
попробовать построить новую модель. Такую модель, которая лучше
представляет данные.
Нередко бывает, что требуется сделать несколько итераций: «модель –
много исключений – новая модель». И эти итерации проводятся до тех пор,
пока удовлетворяющая нас модель не будет построена.
4.3.5. Стадия 5. Сравнения Определив закономерности и объяснив или подправив исключения,
имеет смысл сравнить результаты с прочей важной информацией. Ведь редко
анализ проводится в полной изоляции. Практически всегда существуют
другие данные, с которыми мы можем сравнить наши.
Другие результаты могут быть данными прошлого года, другой
компании, другой страны или даже другого аналитика данных. Другими
словами у нас есть весьма широкий выбор информации для сравнения. Как
следствие, мы можем задаться вопросами:
• Почему продажи этого года отличаются от предыдущего?
• Почему конкурирующая компания использует меньшее количество
торговых марок?
• Почему именно в Западной Германии продажи значительно выше?
Делая такие сравнения и задаваясь такими вопросами, мы, тем самым,
оцениваем данные, на основе этих оценок мы также можем делать выводы и
принимать решения.
Если результаты нашего анализа совпадают с другими данными, это
может значить, что наша модель построена верна. Что в будущем нам нет
смысла собирать большое количество данных. Ведь модель работает! Нам
будет достаточно собрать в следующий раз немного данных, лишь для
82

Часть II. Обработка числовой информации Тема 4. Анализ данных
83
подтверждения того, что модель продолжает работать. Это особенно верно в
случае анализа данных информационных систем, откуда менеджеры черпают
информацию на регулярной основе. Конечно, для каждого периода в таком
случае нет нужды с нуля строить модель. Мы можем ей пользоваться, время
от времени подтверждая данными, что модель по-прежнему верна.
4.3.6. Пример: Потребление алкоголя в США Как пример анализа набора чисел можно попробовать взять
информацию о потреблении алкогольных спиртов по штатам США
(табл.4.3). Цель анализа – измерение разброса в потреблении по штатам и
определение областей с заметными отклонениями от среднего значения. Как
мы можем проанализировать эту таблицу? Какая информация можем быть из
нее получена? Давайте пройдем по всем пяти стадиям анализа данных и
попробуем добиться ответов на наши вопросы.
83

Часть II. Обработка числовой информации Тема 4. Анализ данных
84
Стадия 1. Уменьшение количества данных. Большое количество
данных в этой таблице является излишним. На самом ли деле нужны колонки
с процентами? Конечно, люди понимают, что такое проценты и как ими
пользоваться, но эти колонки в нашем случае не являются важнейшими. Мы
можем легко сократить этот столбец и ничуть не потерять в данных.
Стадия 2. Изменение представление данных. Для ускорения
понимания данной таблицы округлим данные до двух значимых цифр. В
нашей таблице мы можем найти числа с восьмью разрядами данных. Если мы
округлим данные, потеряем ли мы что-то? Вряд ли. Конечно, если бы на
основе этой таблице руководителям подразделений выплачивали бы зарплату
– тогда другое дело!
Штаты мы отсортируем в порядке уменьшения размера их населения.
Это позволит нам быстро найти штаты-исключения. То есть если
потребление продукта значительно больше или значительно меньше в
похожем по размеру другом штате.
Претворив наши изменения в жизнь, таблица станет немного другой –
табл.4.4.
Стадия 3. Построение модели. Теперь закономерность в данных легко
прослеживается. Естественно, потребление зависит напрямую от населения
штата. Потребление на душу населения более-менее одинаково во всех
штатах с отклонением ±30%. В прошлом году мы наблюдаем тоже самое, но
потребление по сравнению с прошлым года чуть-чуть возросло. Вернитесь к
табл.4.3 и попробуйте на основе тех данных сделать такое заключение. Это
будет весьма трудно. То есть наша цель достигнута, мы построили модель, и
эта модель работает. Построить модель нам помогло сокращение ненужных
данных и переработка внешнего вида таблицы.
84

Часть II. Обработка числовой информации Тема 4. Анализ данных
85
Стадия 4. Исключения. Мы видим, что потребление на душу
населения во всех штатах примерно одинаковое. И теперь мы можем
приступить к анализу исключений. На табл.4.4 мы видим, что исключения –
это штаты Невада, Аляска и округ Колумбия. Так же и в прошлом году эти
штаты были исключениями. Не так уж и трудно найти объяснение этих
исключений. Итак – Невада. Там много туристов. Они и пьют наверняка.
Округ Колумбия – там тоже много приезжих, в том числе дипломатов и т. п.
И они много пьют. Если говорить об Аляске – возможно, да и скорее всего,
там просто больше нечем заниматься. Нет такого количества мест отдыха,
как скажем в Калифорнии или где-то еще.
В нашем случае неважно, каковы объяснения этих исключений. Важно
другое. Что есть модель, что есть исключения. И то, что исключения можно
объяснить, не разрушая построенную модель. А за объяснениями мы
обратимся к экспертам в данной области.
85

Часть II. Обработка числовой информации Тема 4. Анализ данных
86
Стадия 5. Сравнения. Сравнение с прошлым годом уже имеется в
таблице. Для того, чтобы еще лучше оценить рынок алкоголя в США,
возможно, будут полезны следующие сравнения:
• Данные за прошлые 5, 10 лет.
• Сравнение потребления чистого алкоголя и крепких спиртных напитков –
виски, джин, водка.
• Сравнение с легкими спиртными напитками – пивом, вином.
При сравнении надо всегда помнить, что часто один и тот же термин в
разные годы, и даже разными людьми употребляется по-разному. Даже если
говорить о термине «потребление». Кто знает, что 100 лет назад
подразумевали под этим словом? Может быть не совсем то, что сейчас?
Тогда и сравнивать данные вряд ли можно…
4.4. Выводы
Каждый человек видит задачу по обработке данных несколько иначе,
чем другие. Потому что каждый рассматривает задачу в узком контексте
того, что он знает, что он умеет, с чем он знаком. Один может хорошо
понимать финансовые данные, потому что он бухгалтер, другой хорошо
понимает социологические данные. Те подходы, которые были предложены
Вам, хорошо подходят к анализу деловой информации во многих ситуациях с
большим диапазоном различных требований.
Ключевые моменты таковы:
• В большинстве ситуаций даже без особых знаний в статистике можно
самостоятельно проводить анализ данных
• Простые методы часто более предпочтительны, чем сложные
• Простой зрительный анализ хорошо представленных данных играет
немаловажную роль в понимании сути вопроса
• Анализ данных не так уж и отличается от анализа текстовой информации
Потребность в умении превращать сырой набор данных в реальную
информацию отнюдь не нова.
86

Часть II. Обработка числовой информации Тема 4. Анализ данных
87
Что делает эту потребность весьма насущной, так это стремительное
развитие компьютерной техники и связанных с ними разного рода
информационных систем. Возможность получать громадные объемы
информации чрезвычайно возросла. И эта возможность сильно опережает
возможности людей эту информацию обрабатывать. Результатом этого
является то, что люди просто начинают погрязать в этом болоте чисел и
цифр. И посему проблема анализа данных становится все более важной.
Когда компании тратят время и деньги на получение информации, то вопрос
превращения данных в полезную информацию и принятия на основе данных
решений встает очень остро.
Несоответствие возможностей классической статистики требованиям
многих людей становится очевидным. В итоге разрабатываются новые
методы и техники. Например, в Турции разработана альтернативная
статистика, которая называется «исследовательский анализ данных». Эта
альтернативная статистика как раз больше подходит для современных
повседневных задач. Такие изменения в статистике являются своеобразным
индикатором того, что обстоятельства заставляют организации использовать
количественные методики анализа данных.
87

Часть II. Обработка числовой информации Тема 5. Сводные измерения
88
Тема 5. Сводные измерения
5.1. Введение
По ходу лекции мы научимся превращать большие наборы чисел в
сводные, итоговые значения, с которыми проще и быстрее работать.
Для того чтобы понять содержимое книги люди обычно читают
аннотацию, резюме. Чтобы не смотреть фильм, или перед тем, как его
смотреть люди читают аннотацию к нему. В аннотации изложены в
нескольких словах, в ключевых фразах все содержание фильма, книги,
отчета. Этот процесс интуитивный, все люди, так или иначе, им занимаются.
Так проще хранить информацию в памяти. Если же необходимо вернуться к
деталям, тонкостям, тогда уж пересматривают фильм, перечитывают книгу –
то есть возвращаются к первоисточнику.
Точно такая же ситуация с числами, с которыми мы работаем. Также
проще работать с меньшим количеством чисел, которые предоставляют ту
или иную совокупность данных. Резюме данных может быть
закономерностью, простой или сложной, или может быть описано в виде
одного или нескольких сводных измерений, о которых сегодня пойдет речь.
Естественно, при сокращении набора чисел неизбежно снижается
точность данных. Более того, если использовано неподходящее сводное
измерение, то данные могут стать вообще ошибочными. Сегодня мы
рассмотрим такие примеры.
Весьма важно не забывать о здравом смысле при сокращении набора
данных, и при использовании статистики вообще. Не стоит также сразу
принимать на веру значения, которые выглядят правильными (сравните
средняя зарплата 5000р. или 5213,23р.). Неровное число совсем не говорит о
том, что оно правильное. В большинстве случаев мы встречаемся с
ошибками в статистике не потому, что плохо знаем арифметику или саму
статистику, а просто потому, что используем ее вопреки здравому смыслу.
88

Часть II. Обработка числовой информации Тема 5. Сводные измерения
89
Нашей целью сегодня является не только узнать какие методы мы
можем использовать для сокращения рядов данных, но также узнать о
допустимых рамках их использования, об их ограничениях и
неоднозначностях.
5.2. Пригодность сводных измерений
Существует несколько видов сводных измерений. Каждый из видов
сводных измерений подчеркивает тот или иной аспект в данных. В бизнесе
вполне достаточно лишь двух-трех сводных значений, чтобы адекватно
представить набор данных.
Давайте рассмотрим небольшой пример на рис.1.
Рис.1.
Такого рода отчет получает менеджер компании, которая занимается
сборкой автомобилей. В отчете представлены данные за каждый день
прошедшего месяца и предшествующему ему.
89

Часть II. Обработка числовой информации Тема 5. Сводные измерения
90
Данные в таблице представлены больше для справочной информации.
Из таблицы можно узнать сколько машин и в какой день месяца было
изготовлено (легко можно найти ответы на вопросы – «сколько машин было
сделано 15 мая и прочее»). Для более общих вопросов типа «хорошо ли
поработала фирма в мае», «каковы тенденции увеличения/уменьшения
продукции в этом году» количество данных в таблице слишком велико и
сама таблица слишком громоздка для получения ответов на такие вопросы.
Для ответов на такие общие вопросы таблица немного переработана и
представлена на рис.2.
Рис.2
Теперь мы в состоянии быстро резюмировать положение дел на фирме.
Также много легче сравнить два прошедших месяца и оценить, когда же дела
шли лучше.
В данной таблице использовано три вида резюмирования информации,
или использовано три различных сводных параметра. Указано среднее
значение производства автомобилей в день. Указан также диапазон
колебаний производства в течение месяца. Третий параметр указывает, что
данные распределены симметрично в обе стороны от среднего значения.
Эти три параметра отражают все наиболее важные свойства изучаемых
данных. А самое главное, они не упускают основных особенностей в данных.
Конечно, сводные измерения применяются не только в статистике, и не
только для уменьшения набора данных. Скажем, такие переменные весьма
важны в финансах, а точнее в финансовой теории (например, дисперсия).
5.3. Средние значения
Средние значения также известны под названием «центральная
тенденция». Их назначение – определение размера данных.
90

Часть II. Обработка числовой информации Тема 5. Сводные измерения
91
5.3.1. Среднее арифметическое Самый известный и полезный параметр – это хорошо знакомое всем
«среднее арифметическое».
значенийКоличествозначенийвсехСуммаскоеарифметичеСреднее = .
В математическом виде формула выглядит так:
nx
x ∑= .
Пример: среднее из 1, 2, 3, 4, 5 равно 35
54321=
++++=x .
5.3.2. Медиана Медиана – это серединное значение из ряда чисел. Не существует
математической формулы для ее расчета. Медиану получают путем
построения отсортированного в возрастающем порядке набора чисел, и,
затем выбора значения строго посередине списка.
Например, медиана для значений 1, 2, 3, 4, 5 будет 3.
В случае, если количество чисел в наборе четное, то тогда вычисляют
среднее арифметическое из двух средних чисел – медиана для набора 1, 2, 3,
4, 5, 6 = 3,5.
5.3.3. Мода Мода – это наиболее часто встречающееся в последовательности
значение. Математической формулы не существует. При расчете моды для
каждого из значений последовательности записывают его частоту появления,
и значение, которое появляется чаще других и является модой.
Например, для последовательности (см.рис.3) 3, 3, 4, 5, 5, 6, 6, 6, 7 мода
будет равна 6.
Число Частота 3 2 4 1 5 2 6 3 7 1 Рис.3.
91
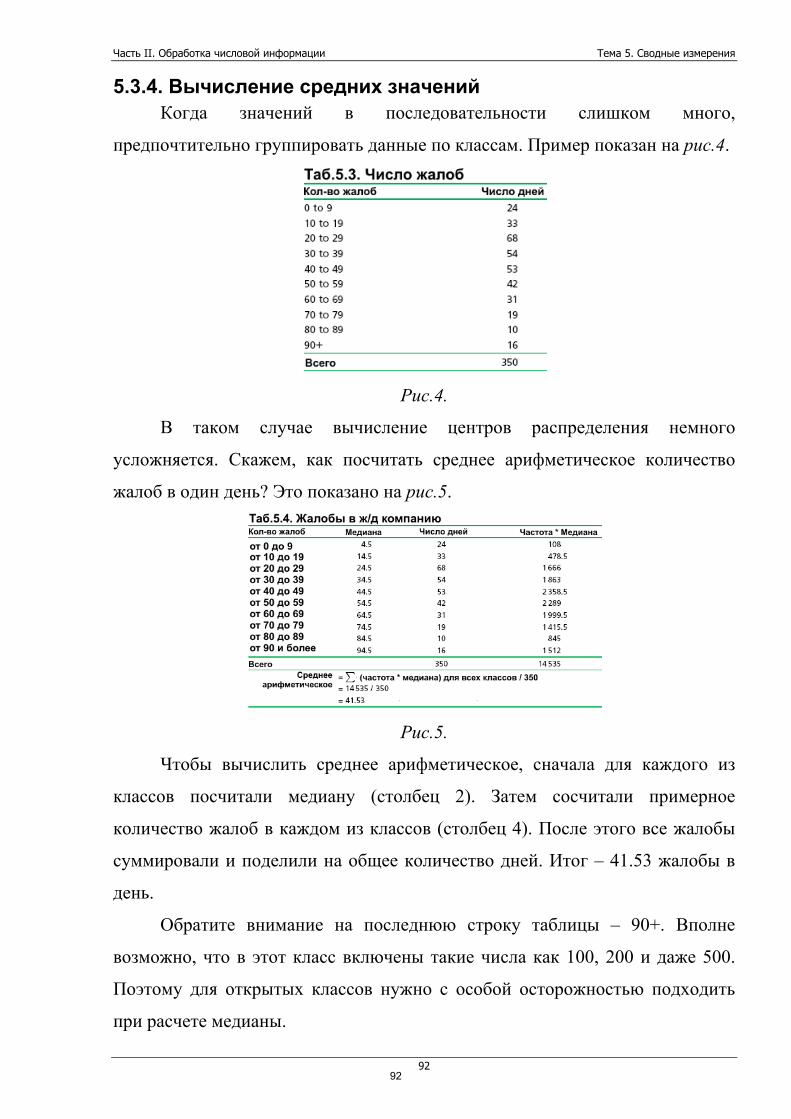
Часть II. Обработка числовой информации Тема 5. Сводные измерения
92
5.3.4. Вычисление средних значений Когда значений в последовательности слишком много,
предпочтительно группировать данные по классам. Пример показан на рис.4.
Рис.4.
В таком случае вычисление центров распределения немного
усложняется. Скажем, как посчитать среднее арифметическое количество
жалоб в один день? Это показано на рис.5.
Рис.5.
Чтобы вычислить среднее арифметическое, сначала для каждого из
классов посчитали медиану (столбец 2). Затем сосчитали примерное
количество жалоб в каждом из классов (столбец 4). После этого все жалобы
суммировали и поделили на общее количество дней. Итог – 41.53 жалобы в
день.
Обратите внимание на последнюю строку таблицы – 90+. Вполне
возможно, что в этот класс включены такие числа как 100, 200 и даже 500.
Поэтому для открытых классов нужно с особой осторожностью подходить
при расчете медианы.
92
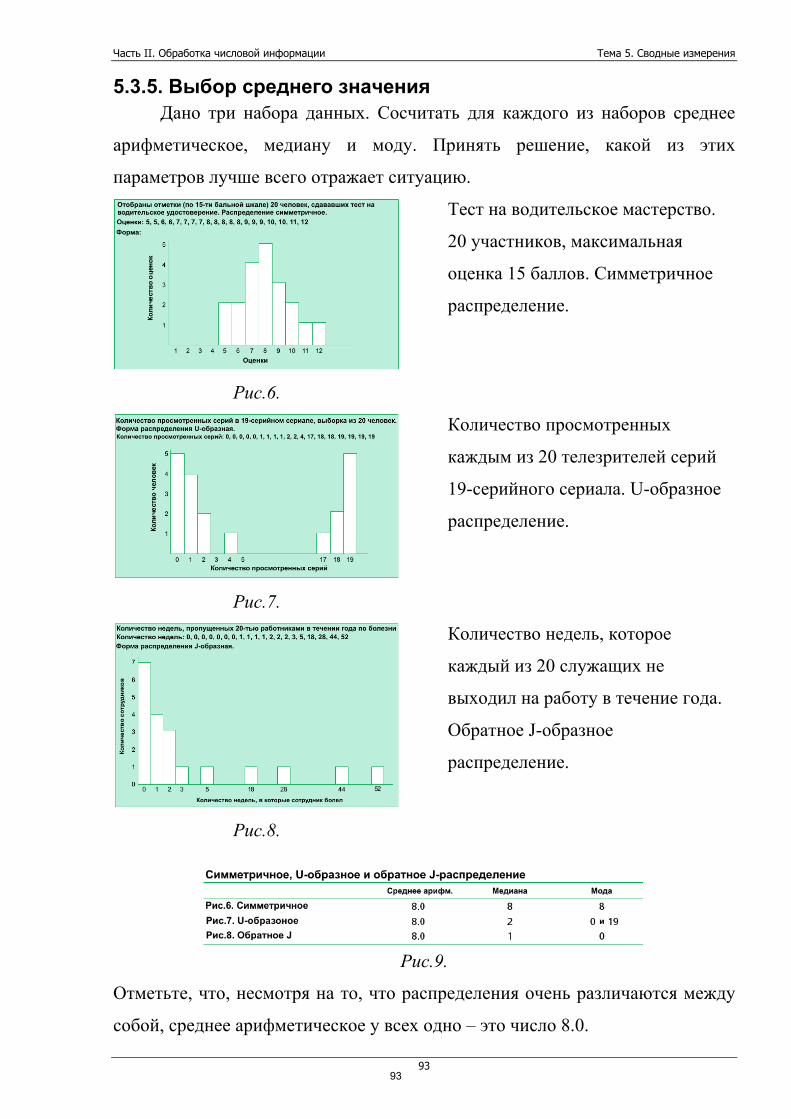
Часть II. Обработка числовой информации Тема 5. Сводные измерения
93
5.3.5. Выбор среднего значения Дано три набора данных. Сосчитать для каждого из наборов среднее
арифметическое, медиану и моду. Принять решение, какой из этих
параметров лучше всего отражает ситуацию.
Рис.6.
Тест на водительское мастерство.
20 участников, максимальная
оценка 15 баллов. Симметричное
распределение.
Рис.7.
Количество просмотренных
каждым из 20 телезрителей серий
19-серийного сериала. U-образное
распределение.
Рис.8.
Количество недель, которое
каждый из 20 служащих не
выходил на работу в течение года.
Обратное J-образное
распределение.
Рис.9.
Отметьте, что, несмотря на то, что распределения очень различаются между
собой, среднее арифметическое у всех одно – это число 8.0.
93

Часть II. Обработка числовой информации Тема 5. Сводные измерения
94
Для симметричного распределения (рис.9), кроме этого, и мода и
медиана тоже равны 8. Это очень часто бывает в симметричных
распределениях, когда все три центра распределения равны или очень близки
друг к другу. Следовательно, для анализа распределения такого типа лучше
всего использовать наиболее простое и известное – арифметическое среднее.
«U»-образное распределение часто встречается, когда мы описываем
такие вещи, как просмотр телепрограмм, чтение журналов и прочее. Люди
либо смотрят почти все серии (кому это интересно), либо совсем не смотрят.
То есть присутствует два экстремума, который расположены далеко друг от
друга. В данном случае среднее арифметическое мало чем поможет. И
использовать среднее арифметическое для заключения о тенденциях в этом
наборе не следует.
Медиана также мало пригодна здесь. Данные, в которых числа близко
сгруппированы около одного или двух экстремумов, очень чувствительны к
значениям в наборе. И их трудно сократить до одного значения, которое бы
говорило обо всем наборе.
Будь сериал лишь чуть более популярным, то вполне возможно
медиана равнялась бы уже 18. Но ведь в данных полно очень маленьких
чисел. А число 18 ввело бы нас в недоразумение.
Лучше всего для такого случая подходит мода. Здесь моды две – 0 и 19.
Обычно мода в данных одна, но когда в данных несколько ярко выраженных
экстремума, то вполне возможно говорить о нескольких модах. На самом
деле, согласно правилам мода равняется тут 0. Но так как второй экстремум
тоже не мал, то 19 мы тоже можем назвать модой.
Обратное J-распределение встречается там, где данные как бы
обрезаны с одной стороны (нет значений меньше 0). Для такого типа
распределений лучше всего подходит медиана. Она будет говорить в нашем
случае сколько недель проболел «среднестатистический» служащий. Два
других средних плохо работают в таком случае. Представьте, что стало бы со
средней арифметической, не будь всего одного служащего, проболевшего
94

Часть II. Обработка числовой информации Тема 5. Сводные измерения
95
весь год. Среднее упало бы сразу с 8.0 до 5.7. Мода тоже не подходит. Мода
здесь равна 0 и вводит нас в заблуждение. Она не дает никакой информации.
Итак, для резюмирования данных используются эти три переменные.
Конечно, они отнюдь не все говорят нам о данных, зачастую необходимо
использовать и более сложные методы анализа данных. Но, учитывая их
простоту, они находят весьма широкое применение в статистике.
5.3.6. Прочее использование средних значений 5.3.6.1. Для сосредоточения внимания:
.
Рис.10.
В первом ряду мы видим, что все значения находятся вблизи среднего.
Во втором – что большинство значений значительно меньше среднего,
а всего несколько – значительно больше среднего.
5.3.6.2. Для сравнения
Рис.11.
Даже не смотря на то, что само по себе среднее арифметическое может
не очень подходить для наборов данных, даже когда наборы данных имеют
разное количество значений, мы, тем не менее, можем использовать среднее
для сравнения наборов между собой.
5.3.7. Проблемы использования средних Давайте еще немного поговорим о слабых и сильных сторонах
среднего арифметического, медианы и моды. Выбор, какой же из методов
использовать, обычно очевиден. Хотя, несмотря на это, люди практически
всегда используют лишь среднее арифметическое, и тем самым, допускают
досадные просчеты.
95

Часть II. Обработка числовой информации Тема 5. Сводные измерения
96
5.3.7.1. Искажение среднего выбросами
Среднее арифметическое очень чувствительно к выбросам. Как это,
например, было в случае обратного J-распределения. Поэтому при больших
выбросах рекомендуется пользоваться медианой.
Другой пример вы помните – это расчет средней зарплаты в какой-либо
организации.
Рис.12.
Среднее арифметическое тут «портится» высокой зарплатой директора.
Медиана тут равна 14000 и она более представительно говорит о реальном
положении дел с заработной платой.
5.3.7.2. Искажение среднего из-за локальных скоплений данных
Арифметическое среднее также может быть непредставительным,
когда данные в наборе группируются около нескольких отличающихся
экстремумов. Как это было на примере U-образного распределения. В случае
наличия нескольких экстремумов (или кластеров в данных) лучше
использовать моду.
5.3.7.3. Ошибки при вычислении среднего от среднего
Когда рассчитывается среднее от среднего, необходимо помнить, что в
таких вычислениях часто кроется ошибка. Например, у нас есть два потока
студентов, сдающих экзамены: Поток А: 50 человек, средняя оценка 74%
Поток В: 30 человек, средняя оценка 50%
(74+50)/2=62%. ( ) ( ) %65
805200
305050307450
==+
×+×
Рис.13.
96

Часть II. Обработка числовой информации Тема 5. Сводные измерения
97
Какова же средняя оценка для всех студентов обоих потоков, вроде бы
(74+50)/2=62%. На самом деле это не так. Вспомните формулу расчета
среднего арифметического. Тогда на самом деле средняя оценка будет
такова: ( ) ( ) %65
805200
305050307450
==+
×+× .
Урок таков – когда мы рассчитываем среднее от среднего и когда
группы имеют разное количество данных, нужно вернуться к основному
определению среднего.
5.4. Показатели разброса
Эти измерения необходимы, когда мы хотим знать насколько близко
или далеко сгруппированы данные в наборе чисел.
5.4.1. Размах вариации Общий интервал, в котором находятся все числа последовательности:
значениеНаименьшеезначениеНаибольшеевариацииРазмах −= .
5.4.2. Интерквартильный размах вариации Для снижения влияния экстремумов в наборе данных, из
последовательности убирают 25% наибольших и наименьших значений и
потом считают размах, как ранее. Или иначе, интерквартильный размах
вариации – это диапазон средних 50% значений выборки.
5.4.3. Среднее линейное отклонение Оно показывает, насколько в среднем значения ряда отличаются от
среднего арифметического этого ряда.
значенийЧислосреднимизначениемкаждыммеждуразницаСуммаотклонениелинейноеСреднее )(
=
nxx
d ∑ −= .
97

Часть II. Обработка числовой информации Тема 5. Сводные измерения
98
.
Рис.14.
Обратите внимание, что разница между всеми значениями ряда и
средним взята по модулю. То сделано потому, что иногда эта разница
положительна, иногда отрицательна. Модуль позволяет избавиться от этой
проблемы.
5.4.4. Дисперсия Альтернативным путем избавления от знака при расчете отклонений от
среднего – это возвести разницу между средним значением и текущим
значением ряда в квадрат.
Существует две формулы для подсчета дисперсии:
( )n
xx∑ −=
22σ и
( )1
22
−
−= ∑
nxx
σ .
Первая формула используется для расчета дисперсии для генеральной
совокупности, вторая – для выборки из нее. Если вы сомневаетесь, с каким
набором данных имеете дело – то используйте вторую формулу. Во всех
калькуляторах практически всегда используется именно она.
Дисперсия имеет очень широкое распространение, особенно в
финансовой теории, и вообще в научных расчетах.
5.4.5. Среднее квадратическое отклонение Вычисляется по формуле
( )1
2
−
−= ∑
nxx
σ или Дисперсия=σ .
98

Часть II. Обработка числовой информации Тема 5. Сводные измерения
99
5.4.6. Сравнение показателей вариации В случае определения центра распределения люди интуитивно
выбирают среднее арифметическое, при выборе показателей вариации не все
так очевидно, поэтому приведем таблицу (рис.15), показывающую слабые и
сильные стороны каждого из измерений.
Измерение Преимущества Недостатки
Размах вариации Легко понять смысл;
Оно нам знакомо
Искажается выбросами;
Используется лишь для
описательных целей
Интерквартильный
размах вариации
Легко понять смысл Не так широко известно;
Используется лишь для
описательных целей
Среднее линейное
отклонение
Ощущается
интуитивно
Оно нам малознакомо;
Трудно обращаться с ним
математически (мешает модуль)
Дисперсия Легко обращаться с
ним математически;
Используется во
многих теориях
Неверные единицы измерения
(квадрат);
Не ощущается интуитивно
Среднее
квадратическое
отклонение
Легко обращаться с
ним математически;
Используется во
многих теориях
Слишком сложно для
описательных целей
Рис.15.
Все эти измерения имеют свои области применения. Здесь нет самого
часто употребляемого измерения, все они равны между собой. Для
описательных целей лучше использовать среднее линейное отклонение, не
смотря на то, что может быть вы не так хорошо с ним знакомы. Когда же
нужно провести более детальный анализ, тогда лучше использовать
дисперсию или среднее квадратическое отклонение.
99

Часть II. Обработка числовой информации Тема 5. Сводные измерения
100
5.4.7. Коэффициент вариации При сравнении разброса в двух рядах с разными средними значениями
необходимо эти ряды перед сравнением стандартизовать. Для этого
используется такой параметр, как коэффициент вариации.
скоеарифметичеСреднееотклонениескоеквадратичеСреднеевариациитКоэффициен = или
xV σ= .
Использование такого коэффициента очень удобно, когда
сравниваются наборы данных с разными характеристиками.
Например, представим, что мы рассчитываем число пассажиров в день,
пользующихся услугами двух аэропортов города. На рис.16 показаны среднее
арифметическое для каждого аэропорта, среднее квадратическое отклонение
и коэффициент вариации.
среднее арифметическое
среднее квадратическое отклонение
коэффициент вариации
Аэропорт 1 4200 1050 0.25
Аэропорт 2 15600 2250 0.14
Рис.16.
Не сосчитай мы коэффициента вариации, можно было бы заключить,
что разброс по дням во втором аэропорту больше, чем в первом. Но если
учесть, количество пассажиров второго аэропорта (а там их больше) то
станет ясно, что разброс по дням во втором аэропорту меньше.
5.5. Прочие сводные измерения
Чаще всего в сводных измерениях применяют переменные,
характеризующие разброс и разного рода средние значения. Однако есть еще
две переменных, которые время от времени используются в статистике.
5.5.1. Коэффициент ассиметрии Коэффициент ассиметрии показывает нам насколько то или иное
распределение является несимметричным. На рис.17 представлены три
распределения. Первое – с левой (отрицательной) ассиметрией, второе – без
ассиметрии, третье – с правой (положительной) ассиметрией.
100
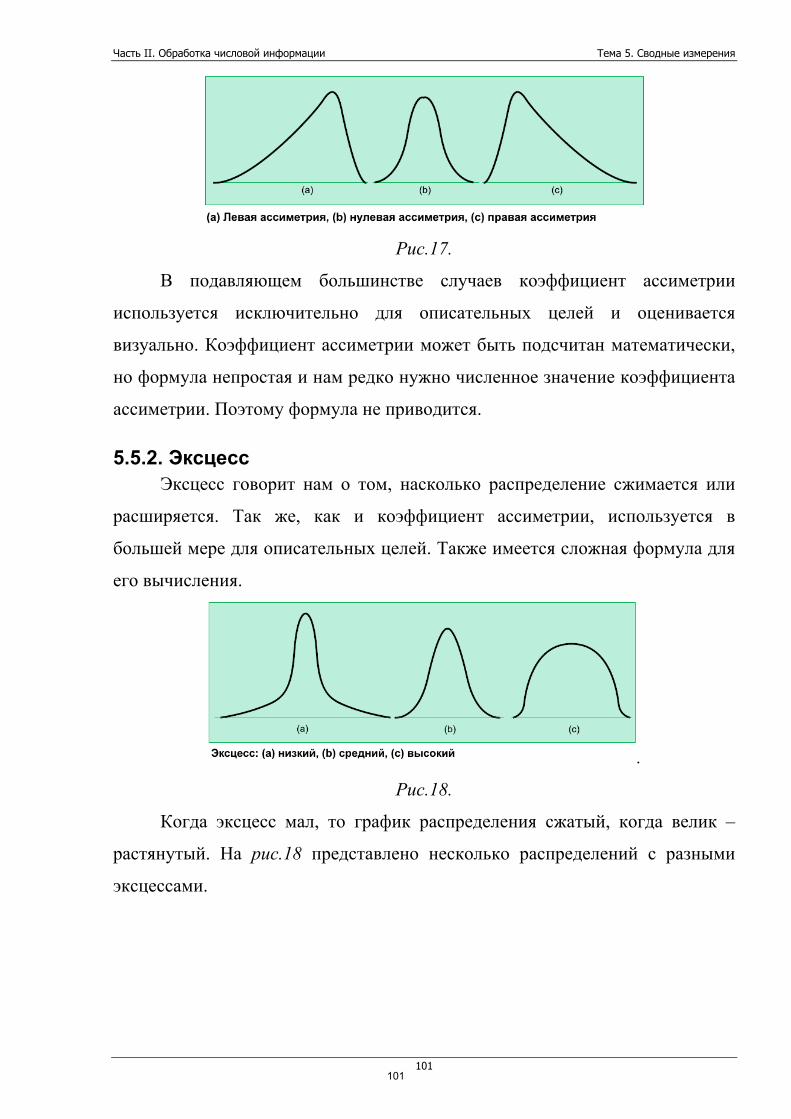
Часть II. Обработка числовой информации Тема 5. Сводные измерения
101
Рис.17.
В подавляющем большинстве случаев коэффициент ассиметрии
используется исключительно для описательных целей и оценивается
визуально. Коэффициент ассиметрии может быть подсчитан математически,
но формула непростая и нам редко нужно численное значение коэффициента
ассиметрии. Поэтому формула не приводится.
5.5.2. Эксцесс Эксцесс говорит нам о том, насколько распределение сжимается или
расширяется. Так же, как и коэффициент ассиметрии, используется в
большей мере для описательных целей. Также имеется сложная формула для
его вычисления.
.
Рис.18.
Когда эксцесс мал, то график распределения сжатый, когда велик –
растянутый. На рис.18 представлено несколько распределений с разными
эксцессами.
101

Часть II. Обработка числовой информации Тема 5. Сводные измерения
102
5.6. Что делать с выбросами
При выполнении сводных измерений и вычислений выбросы могут
сыграть неприятную роль и значительно исказить результаты исследований.
Это касается особенно среднего квадратического отклонения и дисперсии.
Включать ли выбросы при анализе данных? И как с ними бороться?
5.6.1. Закон Твимана Этот наполовину шутливый закон гласит, что любой из элементов
данных, который выглядит интересно или необычно неверен. Перовое,
почему возникают выбросы – это ошибки на этапе сбора информации. Или
ошибки при наборе информации на компьютере (пропущен ноль, пропущена
запятая и пр.). Скажем, согласно закону Твимана из набора данных 1.11, 1.12,
113, 1.14 число 113 необходимо исключить.
5.6.2. Часть закономерности Выброс может также быть определенной и регулярной частью набора
данных и не должен исключаться или исправляться. Вспомните пример о
том, как один из служащих проболел весь год. Это выброс, но его
необходимо учитывать в расчетах и исключать его нельзя. Ведь этот
служащий – часть коллектива и его болезнь наверняка, так или иначе,
повлияла на результаты работы компании. Причем такие выбросы мы можем
время от времени наблюдать – этот выброс является частью закономерности.
Он может повториться, ведь люди иногда болеют…
5.6.3. Изолированные события Также случаются выбросы, которые сами по себе не являются
ошибками, но не повторяются, как в прошлом случае. Их обычно удаляют из
ряда данных, но при этом делается замечание «данное удалено потому и
потому». Например, может быть представлен такой ряд данных, который
показывает, сколько машин заправилось в течение дня на заправочной
станции. Число для любого из дней будет более-менее одинаковым за одним
исключением. Это Новый год. 1 января не так уж много водителей посетят
102

Часть II. Обработка числовой информации Тема 5. Сводные измерения
103
АЗС. Это изолированное событие, оно повторяется 1 раз в год, оно не так
важно для расчетов и его проще выбросить из данных, подлежащих анализу.
Но при расчете среднего за год значения указать, что 1 января исключено из
списка.
Итак, при наличии выбросов мы анализируем причину их появления, и
затем принимаем решение, удалить их из ряда данных или учитывать.
5.7. Индексы
Индекс – это относительная величина, характеризующая изменение
переменной во времени. Если преобразовать ряд чисел в индексы, то
становится значительно легче сравнивать этот ряд с каким-то другим.
Самый известный индекс – это индекс стоимости жизни. Стоимость
жизни складывается из многих вещей – цены на пищу, топливо, транспорт и
т. п. Вместо использования абсолютных значений цены на эти продукты
попробуем воспользоваться индексом. Скажем, если индекс прожиточного
минимума в 2002 году составил 182.1, то, сравнивая его с индексом 2001 года
– 165.3 мы можем сказать, что прожиточный минимум вырос на 10%. Это
ведь значительно проще, чем копаться с большим количеством цен на товары
в этом и прошлом году.
Каждый индекс имеет базовый год, тот год, когда индекс равнялся 100,
то есть как бы начальная точка отсчета. И если точкой отсчета был 1992 год,
то прожиточный минимум вырос за последние 10 лет на 82.1%.
Как видите, индекс дает нам очень быстро почувствовать данные и
сравнить их с другими. Например, индекс зарплаты с 1992 по 2002 годы
вырос со 100% до 193.4%. Сравнивая два индекса – индекс прожиточного
минимума (82.1%) и зарплаты (93.4), видим, что люди стали жить лучше,
ведь рост зарплаты превышает рост уровня цен.
В рамках нашей сегодняшней лекции мы не будем изучать, как
рассчитать индекс прожиточного минимума, это не просто. Вместо этого
рассмотрим более простые индексы.
103

Часть II. Обработка числовой информации Тема 5. Сводные измерения
104
5.7.1. Простой индекс На самом примитивном уровне индекс – это результат преобразования
ряда чисел в другой ряд, с основанием 100. Представим себе числа, которые
показывают нам стоимость квартиры за десятилетний промежуток времени
по годам. За основу произвольно возьмем 1992 год.
Рис.19.
На рис.19 видно оба ряда – исходный, и преобразованный в индексы.
Как видите, получение индексов из исходного набора происходит очень
просто – считается он по элементарной пропорции.
Важным моментом является выбор базового года. Идея такова. Нужно
стремиться выбирать базовый год так, чтобы в ряду все индексы отличались
от базового индекса (равному 100) как можно меньше. Не рекомендуется
выбирать базовый год так, чтобы в последовательности индексы принимали
значения более 300. Скажем, прими мы за базовый год 1987, то индекс 1996
годы был бы равен 318.
В случае очень длинных рядов данных возможно использование
нескольких базовых лет. Посмотрите на рис.20.
Рис.20
Сначала 1964 год был выбран базовым, потом, когда индекс
подобрался к 291 (в 1983 году), то этот год в свою очередь приняли за
базовый и пошли дальше.
Само собой, что в таком случае нужно особенно внимательно
относиться к данным такого ряда. И конечно нельзя сказать, что 1964 и 1996
годы отличаются на 113%. Это не верно. А верно будет так: 213×2.91=620.
Следовательно, 1964 и 1996 годы отличаются на 520%.
104

Часть II. Обработка числовой информации Тема 5. Сводные измерения
105
5.7.2. Простой агрегатный индекс Полезность индексов еще больше усиливается, когда они подводят
итог по нескольким факторам. Месячный индекс цен на мясо вряд ли может
основываться лишь на ценах говядины. Также необходимо видимо учитывать
и другие виды мяса – птица, свинина, прочее.
Рис.21.
Пример про мясо показан на рис.21. В таблицу занесены цены на
говядину, свинину и баранину. Сложим цены всех типов мяса в каждом
месяце. Для января это будет 148+76+156=380 и т. д. Затем возьмем январь за
основу, т. е. за 100. В итоге получится новая таблица – рис.22.
Рис.22.
Единственным недостатком такого метода является то, что мясо с
низкой ценой влияет на показатель индекса значительно меньше, чем дорогое
мясо (см.рис.23). Например, увеличение в феврале цены на говядину на 20
105

Часть II. Обработка числовой информации Тема 5. Сводные измерения
106
процентов изменит индекс с 104,5 до 112,4. А изменение стоимости свинины
на те же 20% изменит индекс лишь до 108,7.
Рис.23.
Тем не менее, возможно в некоторых случаях это вполне желательная
особенность простого агрегатного индекса. Если цена каждого из элементов
(скажем тех же видов мяса) отражает его важность, то, естественно, эта
важность должна соответственно отражаться в индексе.
С другой стороны, этот эффект может быть вредным. В таком случае от
этого эффекта можно избавиться, если сначала рассчитать простые индексы
для каждого вида мяса, а потом найти среднее по трем индексам, и получить
тем самым уже усредненный индекс.
5.7.3. Взвешенный агрегатный индекс Вспомним о примере, где говорилось об индексе стоимости жизни. Не
всегда можно складывать цены на разнородные продукты – молоко, хлеб,
фрукты, сигареты, электричество и прочее. В таком случае простой индекс не
очень подходит. А вот новый вид индекса, взвешенный агрегатный индекс,
позволяет назначать различные веса для различных товаров. Часто в виде
веса, особенно где говорится о ценах на разные товары, используется
количество проданного товара.
Если мы вернемся к нашему мясу, предположим, что у нас существует
информация не только о ценах на мясо, но мы также знаем и количество
проданного мяса (см.рис.24).
Рис.24.
106

Часть II. Обработка числовой информации Тема 5. Сводные измерения
107
Теперь для каждого месяца мы знаем не только цену мяса, но и то,
сколько его продано в течение месяца. Посмотрите на рис.25, как был
посчитан агрегатный индекс.
Рис.25.
Обратите особое внимание, что все цены каждого месяца мы умножаем
на количество мяса, проданного в январе. Это сделано для того, чтобы в
индексе одновременно не содержалась информация как об изменении цен,
так и об изменении количества проданного мяса. И если количества,
используемые для взвешивания мяса, берутся из того же месяца, который
взят за основу, то такой индекс еще называется индексом Ласпейреса.
Индекс Ласпейреса может быть использован как для количеств, так и
для цен товаров, услуг и прочее. То есть можно также за веса принять и
цены, и ими взвешивать количество проданного товара.
Главный недостаток индекса Ласпейреса это то, что веса, которые
берутся из базового года (в нашем случае это было количество проданного
товара) могут скоро стать неактуальными и уже не являться допустимыми к
использованию.
Как альтернативу можно использовать индекс Пааше, который берет
веса из самого последнего периода времени – в нашем случае из декабря. В
этом индексе тоже есть недостаток – ведь при появлении следующего набора
данных (например, при наступлении следующего месяца) нам нужно будет
пересчитать все предыдущие индексы, то есть потратить на это время.
Правда этот недостаток может быть сведен компьютером к минимуму.
Имеется и третий вариант индексов. Это индекс с фиксированным
весом. В этом случае веса берутся не из начала таблицы, не из конца, а из
середины или считается среднее значение по нескольким или даже всем
значениям таблицы и используется в виде индекса.
107

Часть II. Обработка числовой информации Тема 5. Сводные измерения
108
Ну а теперь давайте вернемся к примеру об индексе жизни. Он
содержит информацию о том, как изменяется стоимость жизни типичного
жителя с течением времени. Например, по нему можно отследить такой
интересный факт. Все мы знаем, что цена на продукты постоянно растет.
Растет также и зарплата. Соответственно для сохранения прежнего индекса
жизни необходим вполне определенный рост зарплаты. И если рост зарплаты
не успевает (а так в России и происходит) за уровнем цен, то говорят, что
индекс стоимости жизни или уровень жизни снижается. Или другими
словами, снижается уровень доходов.
Какой же тип индекса использовать в данном случае? Давайте возьмем
два периода времени и выберем несколько товаров. И посчитаем для них
индекс Ласпейреса. Расчеты показаны на рис.26.
Рис.26.
Если за основу мы примем период времени t, то его индекс будет равен
100. Тогда для периода t+1 индекс будет равен 33/30*100=110. На сколько же
возрос индекс жизни для этого случая. Считаем – (110-100)/100%=10%.
Индекс стоимости жизни вырос на 10%.
Но, к сожалению, индекс Ласпейреса не учитывает многое – например
то, что в ответ на изменение цен, уровней доходов, моды, технологии и
прочего изменяется и покупательское поведение потребителей. Например,
мода на короткие стрижки заставит потребителей тратить больше денег на
парикмахера и т. д. Следовательно, индекс стоимости жизни должен
отражать такого рода изменения для того, чтобы показать типичную
стоимость жизни.
Лучше всего использовать в этом случае индекс Пааше, который
включает в себя изменения как цен, так и весов. Упрощенная таблица
потребления показана на рис.27.
108

Часть II. Обработка числовой информации Тема 5. Сводные измерения
109
Веса также как и в примере про мясо умножаются на цены, чтобы
получить индекс. Веса регулярно изменяются по результатам различных
опросов общественного мнения.
Рис.27.
Для индекса стоимости жизни важно и то, что сосчитанные индексы
для прошлых периодов остаются неизменными, их больше не пересчитывают
с новыми весами. Соответственно, сравнивая индекс двадцатилетней
давности и современный, можно отследить одновременно изменения
покупательских пристрастий и неизбежно растущие цены.
Такой индекс, как индекс цен, может быть использован для вычисления
приведенных экономических данных. Скажем, мы знаем, что для нормально
развивающейся страны валовой национальный продукт постоянно растет. Но
в любой экономической системе имеется инфляция. Соответственно она
также привносит свое влияние на величину валового продукта. Чтобы
исключить влияние инфляции на ВНП можно использовать известный нам
заранее индекс стоимости жизни. Посмотрите на рис.28.
109

Часть II. Обработка числовой информации Тема 5. Сводные измерения
110
В первой колонке мы видим для каждого года ВНП. Он постоянно
растет не только из-за экономического роста страны, но и из-за инфляции. Во
второй колонке индекс цен в эти годы. Он был посчитан заранее. Приняв за
основу 1990 год, мы можем теперь сосчитать реальный рост ВНП с учетом
инфляции.
Рис.28.
Как видите, рост ВНП остался, но он уже не такой большой, как
раньше казалось. Этим, между прочим, часто пользуются политики, чтобы
ввести население в заблуждение.
Кстати, очень важно в данном случае использовать верный ценовой
индекс. Индекс стоимости жизни тут не подойдет, так как он учитывает лишь
потребительские товары, а в ВНП включено и много всего прочего.
5.8. Заключение
В процессе анализа данных аналитик пытается построить модель
данных, о чем мы уже говорили с вами. Часто для построения модели
требуется наличие некоторой интуиции и воображения. Зачастую все, что мы
знаем о данных, это:
(а) количество данных в последовательности
(б) средние значения
(в) величина разброса данных
(г) форма распределения
110

Часть II. Обработка числовой информации Тема 5. Сводные измерения
111
Даже при отсутствии другой информации, эти четыре пункта
обеспечивают успешное построение модели данных. Значение по пункту (а)
получить очень легко, оно обычно известно. Средние значения и разброс мы
уже обсудили с вами. Форма распределения легко может быть получена при
помощи построения гистограммы (U, J или симметричная). Короткое
замечание о форме распределения – важный фактор резюмирования данных
и построения модели данных.
Словесные выводы играют более общую роль в резюмировании
данных. Они должны быть очень коротки, максимум несколько
предложений, и использоваться только тогда, когда это имеет очевидный
смысл. Первое, они используются тогда, когда сводные значения
оказываются неожиданными, неадекватными, второе – они указывают на
важные особенности данных. Например, можно указать в выводе, что
прибыли компании удвоились. Или говорить о том, что продукция в январе
была в три раза ниже среднегодовой из-за забастовки.
Весьма важным является использование словесных выводов для того,
чтобы разделить полезную информацию, указывающую на основные
особенности данных и бесполезную, в которой содержаться тривиальные
исключение и незначительные детали. Словесный вывод должен в первую
очередь способствовать простоте и скорости обработки изучаемых данных.
111

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
112
Тема 6. Методы выборочного обследования
6.1. Введение
После изучения материалов этого занятия мы узнаем основные
принципы, которые лежат в основе методов выборочного обследования.
Менеджеры достаточно часто используют такие методы. Это может быть
непосредственно проведение опроса или косвенное использование
информации, полученной выборочным путем. В обоих случаях имеется
необходимость в некоторых знаниях и приемах, применяющихся в этих
методах, и, что наиболее важно, факторах, влияющих на успешное их
использование.
Статистическую информацию в менеджменте получают обычно из
выборок. Вообще, полное множество всех возможных наблюдений какой-
либо переменной называется генеральной совокупностью, а подмножество –
выборкой. Очень редко имеется возможность изучать всю генеральную
совокупность. Часто, если не всегда, получение выборки значительно
дешевле, чем генеральной совокупности. При этом в большинстве случаев
выборка может обеспечивать вполне достаточную точность для принятий
решений, решения проблем и ответов на вопросы.
Например, очень трудно опросить всё население страны о том, что оно
думает о какой-то конкретной марке стирального порошка. Проще провести
опрос выборочно. Например, проинтервьюировать несколько сот человек и
по их ответам оценить, что же думает все остальное население страны. В
данном случае все население страны – это генеральная совокупность,
несколько сотен людей – выборка. Выборка – это не всегда люди, выборкой
также может быть, например, несколько гектаров земли из тысяч и тысяч
гектаров. Или это может быть 10 деталей из 1000 и т. д.
На практике информация практически всегда собирается из выборок, а
не из генеральной совокупности по большому количеству причин:
112

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
113
• ЭКОНОМИЧЕСКАЯ ВЫГОДА. Сбор информации часто недешев.
Подготовка вопросников, рассылка их, командировки, анализ данных –
все это лишь несколько примеров расходов на сбор информации.
Использование выборки много дешевле, чем сбор всей информации.
• СВОЕВРЕМЕННОСТЬ. Сбор информации из всей генеральной
совокупности может быть долог, особенно если приходится ждать
заполненных анкет или встреч с опрашиваемыми людьми. Выборочная
информация может быть получена быстрее, а иногда это жизненно
необходимо. Например, сбор мнения электората. Ведь мнение в
результате течения времени может меняться по мере приближения
выборов!
• РАЗМЕР И ДОСТУПНОСТЬ. Некоторые генеральные совокупности
настолько велики, что информация просто физически не может быть
собрана полностью. Например, какое-то маркетинговое исследование
может касаться всех тинэйджеров страны. Попробуйте их всех отловить!
И даже в не таких больших совокупностях не всегда все части ее могут
быть доступны. Например, информация о частных предпринимателях.
Они появляются и исчезают с такой быстротой, что опрос может не
посметь за ними.
• НАБЛЮДЕНИЕ И РАЗРУШЕНИЕ. Обследование чего-либо может и
разрушить то, что обследуется. Например, тест на качество электрических
предохранителей построен так, что в результате предохранитель должен
сгореть. И конечно не имеет смысла сжигать все предохранители для того,
чтобы проверить их качество.
Теория, связанная с выборками состоит из двух частей. Это показано на
рис.6.1.
113

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
114
На примере маркетингового исследования по поводу стиральных
порошков, о котором мы говорили ранее, первая часть теории показывает,
как выбирать несколько сотен человек из всего населения страны
Вторая часть теории покажет, как использовать выборочную
информацию для того, чтобы составить заключение обо всей генеральной
совокупности.
В этой лекции мы рассматриваем только первую часть этой теории –
создание, получение выборок. Мы рассмотрим специальные методы для
этого, некоторые применения выборок и технические аспекты. Вторая
область теории будет подробно описана позднее, в теме №8.
6.2. Применение выборок
Области применения выборочных методов достаточно общие,
понятные. Приведем лишь несколько общих примеров:
• Опросы общественного мнения. Газеты регулярно публикуют
результаты опросов общественного мнения. Вопросы могут быть такими:
«За какую партию вы собираетесь голосовать на следующих выборах?»,
«Удовлетворены ли Вы тем, как правительство проводит экономические
реформы?». Эти вопросы обращены ко всему населению страны.
Например, в нашей стране живет около 150 миллионов человек. Опрос
всего населения будет длительным, дорогим и практически
нереализуемым мероприятием. Компании по опросу общественного
114

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
115
мнения основываются на выборке, обычно это 1000-2000 человек.
Поэтому опрос становится дешевле и результат может быть получен
относительно быстро. И данные не устареют до их опубликования. Но,
несомненно и то, что результаты такого опроса будут слегка неточными,
чем опрос всего населения.
• Контроль качества. Комбинат по производству пищевых продуктов
получает каждый день тонны сырья. И в данном случае будет не только
дорого, но и невозможно проверить все то, что поступает в виде сырья.
Вместо этого сырье проверяется выборочно. Когда прибывает новая
партия сырья, то проверяется лишь часть его. На основе результатов вся
партия в итоге может быть использована, либо забракована. Правила, на
основе которых руководствуются при этом, основаны на статистической
теории.
• Проверка счетов. Крупные организации выписывают и оплачивают
тысячи счетов в течение года. Когда проводится аудиторская проверка, то
не имеет особого смысла проверять все счета. Создается выборка, и на
основе результатов ее анализа рассчитывается средняя ошибка, которая
происходила при выписке счетов в течение этого года.
6.3. Идеи, лежащие в основе выборочного обследования
В этих трех примерах мы ничего не сказали о методах, на основе
которых строятся выборки. Для того чтобы получить корректное заключение
обо всей совокупности данных, выборка должна быть репрезентативной
(представительной), то есть выборка должна быть как бы этой же
генеральной совокупностью, но в миниатюре.
Не существует методов, которые позволили бы строить гарантированно
репрезентативные выборки. Все известные методы могут подчас
генерировать непредставительные выборки, но в то же время
представительность – это главная цель. Когда выборка получена таким
115

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
116
путем, что она не может быть представительной, то говорят о таком понятии,
как тенденциозность выборки.
Фундаментальный метод получения репрезентативной выборки
называется простой случайный отбор, когда выборка получается из
генеральной совокупности таким методом, что каждый ее генеральной
совокупности имеет равный шанс быть выбранным.
Представьте, что каждый элемент пронумерован, номера написаны на
клочках бумаги, и все они помещены в большую шляпу. И человек с
завязанными глазами выбирает бумажки с числами. Простой случайный
отбор очень похож на такую процедуру. Другими словами, каждый из
элементов генеральной совокупности имеет равный шанс попасть в выборку.
Обычно (но не всегда) такая выборка может быть удовлетворительно
представительной.
Главный недостаток такого метода – это то, что он может иногда
оказаться недешевым. Скажем, если идет речь об общественном мнении
электората накануне выборов, то должен существовать какой-то список всего
населения страны, потом всех выбранных случайным образом персон нужно
найти и проинтервьюировать (одного из Якутии, другого с Сахалина и т. п.).
В итоге, как выбор, так и опрос людей может оказаться дорогим.
В данном случае подойдет лучше многоступенчатый отбор. Лучше
сначала отобрать несколько регионов страны, тем самым значительно
сократив время на командировку специалиста, который будет опрашивать
население.
Иногда, чтобы сделать выборку более представительной, необходимо
использовать дополнительную информацию. В примере про стиральный
порошок человеку, который создает выборку, неплохо было бы знать
процент семей, которые используют ручную, полуавтоматическую или
автоматическую стирку. Такая выборка называется расслоенной выборкой.
В некоторых ситуациях случайные методы вообще не подходят или
попросту не нужны. Тогда используются так называемые не вполне
116

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
117
случайные выборки. В таких выборках большую роль играет персональное
мнение человека, создающего выборку. Тем не менее, и такой метод может
быть применим в некоторых обстоятельствах и выборки могут получаться
вполне представительными.
На рис.6.2 показаны основные методы выборочного обследования и то,
как они связаны. Далее мы рассмотрим эти методы более подробно.
Рис.6.2. Связь между основными методами выборочного обследования
6.4. Случайные выборки
6.4.1. Простая случайная выборка
Построение простой случайной выборки – это такая процедура
создания выборки, когда каждый элемент генеральной совокупности имеет
равный шанс попасть в выборку. Клочки бумажки с номерами и помещение
их в шляпу – это как раз такой процесс. Чаще всего, выбором занимается не
владелец этой шляпы, а компьютер или люди, использующие специальные
таблицы случайных чисел.
Все методы выборочного обследования
Случайные выборки
Простая случайная выборка
Разновидности простой случайной выборки:
- многоступенчатая - групповая - расслоенная - взвешенная - вероятностная - переменного объема
Не вполне случайные выборки
Систематическая выборка
Нерепрезентативная выборка
Квотированная выборка
117

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
118
На табл.6.1 показаны 28 случайных чисел в диапазоне от 0 до 99. Они
сгенерированы компьютерной программой, которая была написана таким
образом, что у каждого числа был одинаковый шанс попасть в таблицу.
Раньше, при отсутствии компьютеров пользовались специальными
заранее сгенерированными таблицами случайных чисел.
Представьте, что необходимо найти пять случайных из 90 рабочих
завода. Они нужны для того, чтобы опросить их детально об их отношении к
работе.
Из ведомости по выдаче заработной платы составлен список всех 90
рабочих в алфавитном порядке, и все они пронумерованы (см.табл.6.2).
Чтобы теперь случайным образом найти 5 рабочих из этого списка,
берется таблица случайных чисел (например, табл.6.1), и из нее берется
подряд 5 значений. И эти значения и будут номерами работников из табл.6.2.
В итоге выборка будет выглядеть вот так (см.табл.6.3).
118

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
119
Недостатком простой случайной выборки является то, что на
подготовительном этапе мы должны составить пронумерованный список
всей генеральной совокупности. Это дорого, долго или даже невозможно.
Для того чтобы обойти эту проблему были разработаны некоторые
разновидности методов случайной выборки.
6.4.2. Разновидности простой случайной выборки
6.4.2.1. Многоступенчатая выборка
В многоступенчатом отборе вся генеральная совокупность разбивается
на группы, каждая группа разбивается на подгруппы, каждая подгруппа на
подподгруппы и т. д. На каждом шаге берется простая случайная выборка –
сначала выборка группы, потом выборка подгрупп и т. д. У компании
имеется 15 отделений. Например, представьте выборку из 2000 рабочих этой
компании, в которой работает 250000 человек, расположенных в разных
отделениях, офисах и т. д. Цель исследования – узнать о причинах прогулов
работы.
Каждое из отделений имеет в среднем 10 офисов. В каждом из офисов
имеется компьютер, который печатает ведомости по выплате заработной
платы. Общего списка работников компании не существует, то есть
компания весьма децентрализованная. На рис.6.3 показано, как устроена
фирма.
119

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
120
Если проводить отбор методом простой случайной выборки, может
возникнуть две сложности. Во-первых, нет общего списка всех работников
компании – это не простая задача – составить его, учитывая количество
отделений и офисов в компании. Во-вторых, будет необходимо посетить
каждый из офисов компании для проведения опроса – это долго и дорого. В
данном случае многоступенчатый отбор может помочь.
Сначала случайным образом будет выбрано скажем 4 отделения из всех
15 отделений фирмы. Этот отбор будет осуществлен методом простого
случайного отбора. После этого будет создан список всех офисов этих 4
отделений. Потом для каждого из 4 отделений будет случайным образом
выбрано по 2 офиса. Потом для этих для каждого из этих 8 офисов будет
получена выборка из 250 рабочих, которые там работают (списки такие есть).
В итоге 8×250=2000, то есть мы получили желаемую выборку. И при этом
нам не пришлось создавать список всех работников компании, и работа по
созданию выборки была значительно дешевле – мы работали лишь с 8-мью
офисами вместо 150.
Не существует каких-то строгих правил, которыми стоит
руководствоваться при определении размера выборки на каждом из шагов.
Обычно достаточно чувства здравого смысла и знание различных
обстоятельств. Например, выбор 1 подразделения из 15 существующих
наверняка сделает выборку нерепрезентативной. Если же выбрать 10
подразделений из 15, то выборка станет уже слишком дорогой и т. д. Выбор
же 4-5 подразделений – это как раз тот самый разумный компромисс между
точностью и ценой.
6.4.2.2. Групповая выборка
Групповой отбор весьма схож с многоступенчатым отбором.
Рассмотрим отличия на примере.
Так, например, 10000 студентов (400 групп) института занимаются
группами по 25 человек. Для проведения 15% (1500 человек) выборочного
120

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
121
наблюдения групповым способом необходимо в случайном порядке отобрать
60 групп (1500 : 25 = 60) из 400 (10000 : 25 = 400) и результаты наблюдения
перенести на совокупность.
Или наш прошлый пример. Можно также выбрать четыре
подразделения компании и по два офиса из каждого подразделения. Но
выборка среди работников офисов уже не производится, а все работники
офиса участвуют в опросе. Если в каждом офисе работает по 6 человек, то
общий размер выборки будет 4×2×6=48. Это двухстадийная групповая
выборка. Так как было две стадии отбора – сначала подразделения, а потом
офисы. Если бы сначала был составлен список всех офисов компании, а
потом из них выбрали бы персонал нескольких офисов, то тогда бы выборка
была бы одностадийная, и называлась бы она простая групповая выборка.
Если же размер выборки в 48 человек слишком мал, то тогда можно
увеличить либо число подразделений компании, или большее число офисов
из каждого подразделения требовалось бы включить в выборку.
6.4.2.3. Расслоенная выборка
В расслоенном отборе используются определенные знания о
конкретной генеральной совокупности, которая изучается. В результате
точность выборки будет выше. Если генеральную совокупность можно
разбить на определенные подсовокупности известного размера и известных
характеристик, то это делается. Затем проводится случайный отбор из
каждой подсовокупности в той же пропорции, в которых подсовокупности
соотносятся с совокупностью.
Вернемся к нашему примеру. Допустим, мы знаем, что весь персонал
состоит из 9% руководства, 34% - клерки разных уровней, 21% -
высококвалифицированные рабочие и 36% - неквалифицированные.
Желательно, чтобы в выборке они были представлены в такой же пропорции.
Следовательно, при подготовке выборки мы должны опросить 180
121

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
122
управленцев (9% от 2000), 680 клерков, 420 квалифицированных рабочих и
720 неквалифицированных.
Интересно то, что расслоенная выборка не мешает использовать
методы групповой выборки. То есть эти два метода могут использоваться
одновременно. Вспомните, что в итоге мы пришли к 8 офисам. В этих офисах
работало 250 сотрудников. Так вот, в каждом из этих офисов мы должны
опросить по 22 руководителя (9% от 250) и т. д.
6.4.2.4. Взвешенная выборка
Рассмотрим принцип такой выборки на примере табл.6.4.
Не всегда имеется возможность составить выборку так, чтобы четыре
категории работников попали в выборку в той же пропорции, в которой они
существуют в компании. В таком случае после получения выборки
результаты ее взвешиваются. И только после этого производится расчет, в
данном случае расчет количества пропущенных дней средним работником
компании.
6.4.2.5. Вероятностная выборка
В простой случайной выборке каждый элемент совокупности имеет
равный шанс попасть в выборку. Иногда имеются обстоятельства, согласно
которым имеется необходимость, чтобы элементы имели разную вероятность
попадания в выборку. Такая выборка и называется вероятностной.
В ходе проведения опроса о качестве школьных завтраков, строится
случайная выборка школ, меню которых затем проверяется. В таком случае
качество питания в больших школах будет затронуто меньше, чем качество
пищи в средних по размеру школах. Ведь средних школ значительно больше,
122

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
123
чем больших. И в данном случае это важно – ведь если в большой школе
плохо готовят, то от этого страдает большое количество детей.
Вероятностная выборка дает разным школам разные шансы попасть в
такую выборку. И зависеть вероятность попадания в выборку каждой школы
в данном случае будет от ее размера. В итоге, качество завтраков вне
зависимости от размера школы будет проверено. То есть у каждого ребенка
появится равный шанс кушать качественную еду.
6.4.2.6. Выборка переменного объема
В выборке переменного объема часть генеральной совокупности
нарочно представляется слишком большим количеством элементов. Это
может делаться в том случае, когда это часть совокупности имеет очень
важное значение и обычная выборка будет слишком мала для построения
объективной картины обо всей генеральной совокупности.
Представим себе некое медицинское обследование детей, которые
недавно перенесли корь. В данном случае генеральная совокупность – это все
дети указанной возрастной группы, кто болел корью. Небольшая часть этой
совокупности (может быть 1%) – это те дети, у которых после кори возникли
осложнения, связанные с умственными способностями. Даже большая
выборка из 500 человек будет содержать лишь 5 таких осложненных детей.
Конечно, всего по 5 детям нельзя делать какие-либо заключения об
осложнениях после кори. Более того, изучение этих осложнений как раз и
есть цель медицинского обследования. В таком случае нужно нарочно
включить больше детей в выборку, которые получили после кори
осложнения.
6.5. Не вполне случайные выборки
В таких выборках значительное влияние на построении ее привносит
личное мнение человека, который эту выборку создает. Такие методы
используются, когда невозможно использовать ту или иную случайную
выборку. Или в тех случаях, когда случайная выборка оказывается слишком
123

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
124
дорогой, и в таком случае не вполне случайная выборка может оказаться
более выгодной альтернативой.
Вот основные методы, по которым строятся не вполне случайные
выборки:
• СИСТЕМАТИЧЕСКАЯ ВЫБОРКА. В таком случае данные из
генеральной совокупности берутся через ровный интервал. Например,
если совокупность состоит из 50000, а требуется выборка в размере 1000,
то каждое 50-е значение должно попасть в эту выборку. Для того, чтобы
не брать первый элемент из списка, среди первых 50-ти значений
выбирается случайное, а затем берут каждое 50-е значение, начиная с
выбранного.
Проводя некую аналогию, мы можем заметить, что такая выборка весьма
похожа на случайную. Разница лишь в том, что нам нет необходимости
получать случайные значения, пользоваться таблицами случайных чисел и
т. д. Очень хорошие результаты могут быть получены, если изначально
список всех элементов будет алфавитный, вне зависимости от положения
человека в организации, его зарплаты и т. д.
Тем не менее, существуют и некоторые особенности в такой выборке.
Скажем, если список составлен так, что он разбит по бригадам из шести
человек и седьмой – бригадир, то, делая выборку, неправильным образом,
можно либо вообще исключить бригадиров из выборки, либо, наоборот, в
выборке окажутся одни бригадиры.
В итоге систематическая выборка может обладать эффектом случайной,
но быть при этом быстрее и дешевле. С другой стороны, могут быть
получены большие ошибки при составлении такой выборки, и она в итоге
окажется репрезентативной.
• НЕРЕПРЕЗЕНТАТИВНАЯ ВЫБОРКА (ВЗЯТАЯ ИЗ
СООБРАЖЕНИЯ УДОБСТВА ИССЛЕДОВАНИЯ). Это значит, что
выборка получается простейшим из имеющихся путей. Такие выборки
124

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
125
делаются в том случае, если никакая другая выборка сделана быть не
может.
В медицине образец крови берут обычно из пальца. Это как раз пример
нерепрезентативной выборки. Так как известно, что кровь циркулирует по
организму, то в данном случае результат будет вполне случаен, не так ли?
Или другой пример. Рассмотрим исследование. В котором изучается
поведение членов семьи, когда один из ее членов болен серьезной
болезнью. Ясное дело, что выборка в данном случае совсем не случайна,
ведь не каждая семья согласится дать ответы на вопросы. И результат
такого исследования может быть совсем неправильный. Ведь та семья,
которая решила ответить на его вопросы, наверняка имеет не такое
отношение к болезни, как та семья, которая отказалась отвечать.
• КВОТИРОВАННАЯ ВЫБОРКА. Например, если молодой человек
послан интервьюировать покупателей магазина, то ему легче и приятнее
всего будет обращаться с вопросами к молодым девушкам.
В таком случае результаты опроса могут быть неточными. Для того,
чтобы избежать таких ошибок перед опросом составляется таблица, в
которой указывается количество, возраст и пол людей, которых надо
опросить. Другими словами каждый из слоев населения будет опрошен
согласно установленным квотам.
Важно не путать расслоенную и квотированную выборки. В первой мы
знаем пропорцию распределения чего-либо в генеральной совокупности,
во второй – нет.
6.6. Типичные сложности при работе с выборками
6.6.1. Основа выборки
Основа выборки – это полный список элементов, из которых делается
выборка. Это звучит также как и генеральная совокупность, но на практике
эти два понятия слегка отличаются. Разница в этих двух понятия может в
итоге привести к тому, что выборка станет слишком неточной.
125

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
126
Если вернуться к нашему примеру с офисами, подразделениями и т. п.,
то генеральная совокупность – это все работники компании. Тем не менее,
компьютерные записи о сотрудниках компании могут быть не совсем точны
– они не всегда самые свежие и не учитывают тех работников, которые
недавно устроились на работу, или уволились с нее. Более того, в ведомостях
по выплате заработной платы могут не быть включены полставочники и
прочие временные работники. В результате основа выборки слегка
отличается от генеральной совокупности. И эти отличия иногда могут быть
серьезными.
6.6.2. Недополучение данных
Представьте себе, что проводится опрос, при котором интервьюер
должен задавать вопросы касательно потребления, скажем, кондитерской
выпечки населением. Если кого-то не было дома в тот момент, когда он
приходил, то случается как раз это - недополучение данных.
Если же человеку придется навестить этот дом еще раз, то создание
выборки может стать дорогим мероприятием, если дом не посетили повторно
– то данные будут пропущены и возможно в выборке возникнет некая
тенденциозность. Возникнуть она может потому, что в тех домах, в которых
никого не оказалось, жили не совсем типичные жители, и они могли бы дать
не совсем типичные ответы.
Недополучение данных возникает не только тогда, когда мы могли не
застать кого-то дома, но и тогда, когда какие-то измерения не могут быть
проведены для некоторых элементов выборки. Например, в нашем примере
про офисы и подразделения, отсутствие каких-то записей о некоторых из
работников фирмы, которые включены в выборку, также приведут к
проблеме недополучения данных.
Если для получения этих данных требуются дополнительные усилия,
то выборка становится дороже. Если данные не стали восстанавливать – то
выборка уже не будет такой репрезентативной, какой она могла бы быть.
126

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
127
6.6.3. Тенденциозность
Тенденциозность – это создание таких выборок, в которых некоторые
элементы генеральной совокупности либо недопредставлены, либо
перепредставлены. Это может быть и из-за недополучения данных, и из-за
проблемы с основой выборки. Также существуют и другие пути создания
тенденциозных выборок:
• НЕТОЧНОЕ ИЗМЕРЕНИЕ. Это может быть и физическая неточность,
скажем термометр превышал показания градусов; может быть и
концептуальная неточность, когда при опросе об уровне зарплаты не
учитываются премии и прочие доплаты.
• НЕОБЪЕКТИВНОСТЬ ИНТЕРВЬЮЕРА. Это происходит тогда, когда
сам создатель выборки создает ошибки. Ведь можно задать вопрос либо в
мягкой, либо в агрессивной форме. Ответы будут разными, это
несомненно.
• НЕОБЪЕКТИВНОСТЬ ИНТЕРВЬЮИРУЕМОГО. Возможность
человек, которого опрашивают, захочет произвести хорошее впечатление,
и тогда он ответит не совсем честно. Зачастую люди всех возрастов не
совсем честно отвечают об их возрасте, доходе, вредных привычках и так
далее.
• НЕОБЪЕКТИВНОСТЬ ВОПРОСОВ. Сами вопросы могут быть
построены по-разному. Можно так хитро поставить вопрос, что человек на
него вполне предсказуемо ответит.
Тенденциозность особенно страшна тогда, когда она существует, но ее
не замечают. Ведь в итоге по полученной выборке будет сделано заключение
обо всей совокупности данных, и это заключение будет неверным.
В то время как тенденциозность обнаружена, это отнюдь не значит, что
такая выборка абсолютно бесполезна. Просто нужно с особой
осторожностью относиться к тем заключениям, которые могут быть сделаны
на основе такой выборки. Например, вспомните о том примере, где мы
говорили о больном человеке в семье. Та выборка наверняка была
127

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
128
тенденциозной. Но если указать при этом, что 20% людей отказались
отвечать на вопросы, то такой выборкой вполне моно пользоваться, помня об
этих 20%, и понимая, что ответь все – результат бы мог быть иной.
В другой ситуации такую неточную выборку можно считать как бы
пилотной, пробной попыткой перед созданием хорошей, представительной
выборкой.
6.7. Что такое размер выборки?
Один из самых важных вопросов при выборочных обследованиях – это
вопрос размера выборки. Почему в нашем примере мы остановились на
числе 2000 работников? И почему не на 1000 или 5000? Есть два подхода к
этому вопросу.
ПЕРВЫЙ ПОДХОД – это задаться вопросом, какая точность в итоге
требуется. Скажем, при опросе общественного мнения касательно поддержки
какой-то политической партии мог быть получен результат, что 53%
населения поддержат эту партию. Если точность опроса будет 53±20%, то
вряд ли этот результат будет полезен для руководителей партии. А вот
точность 53±1% будет очень даже удовлетворительной. Или такой пример,
семья тратит на продукты питания 3000±300 руб. в месяц – это совсем
неплохая точность, а 3000±1000 руб. – уже совсем не то!
Зная требуемую точность, мы можем использовать статистическую
теорию для оценки требуемого размера выборки, ведь именно размер
выборки и влияет на точность. Такая теория будет описана позднее, но мы
можем воспользоваться ей уже сейчас.
При случайной выборке несложно сосчитать точность полученных
результатов. Вполне допустимо сказать, что при увеличении числа значений
в выборке в четыре раза (со 100 до 400) мы увеличиваем точность в два раза,
и, соответственно снижаем ошибку в два раза. Увеличивая число элементов с
4000 до 1600, точность опять удваивается и т. д. Следовательно, мы
128

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
129
изначально должны для себя решить, какая точность нам нужна. Зная
точность, мы легко можем определить размер выборки.
ВТОРОЙ ПОДХОД. Этот подход не такой теоретический, но более
часто используется на практике. Суть в том, чтобы строить настолько
большую выборку, насколько позволяют нам наши возможности и финансы.
А затем уже посчитать точность, которую мы достигли в результате.
Есть такой интересный момент. Представьте себе генеральную
совокупность из всего лишь 50 элементов. Используя метод случайной
выборки, мы будем случайным образом выбирать элементы из совокупности.
Первый элемент будет иметь вероятность попасть в выборку, равную 1/50.
Второй – уже 1/49. Третий – 1/48 и т. д. В больших совокупностях этим
обычно пренебрегают.
А для малых совокупностей есть два пути.
Первый – когда взятый из совокупности элемент как бы возвращается в
совокупность и может быть выбран снова. Тогда вероятность попадания
всегда будет 1/50. Правда, тогда некоторые элементы попадут туда дважды
или даже большее количество раз.
Второй путь – это использование несколько иных методов для расчета
точности и размера выборки. На этом в данный момент мы останавливаться
не будем. Но, тем не менее, следует помнить, что и малые совокупности
данных могут создать некоторые проблемы для исследователя.
6.8. Заключение
Одним из интересных моментов является то, что сбор информации
зачастую проводится с явным игнорированием концепций выборочных
методов. Скажем если какая-то компания нуждается в информации о своих
счетах, то она наверняка проверит все счета до единого за последний квартал.
И это будет та еще задача для нее. Даже самой простой метод выборки
можем снизить цену такого исследования раз в 100, причем точность
практически не снизится.
129

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
130
Даже после того, как выбран метод создания выборки, требуется
провести некоторое планирование. Например, задаться такими вопросами:
«Какие точно цели в итоге преследуются?», «Можно ли получить эту
информацию из других источников?». Не задав себе таки вопросов, можно
потратить уйму времени на получение выборки и в итоге не ответить на
поставленные вопросы.
Например, проведя выборку из 2000 рабочих можно в итоге выяснить,
что статистика невыходов на работу вообще не велась. Или что такой
обследование уже проводилось полгода назад и его результаты вполне еще
современны.
Области применения выборок очень широки. Везде, где собирается
информация, можно и нужно использовать выборки. Вот несколько из
областей применения выборок:
• Опросы общественного мнения
• Исследования рынка
• Медицинские обследования
• Бухучет и аудит
• Контроль качества
• Информационные системы
Во всех случаях, выборка – это разумный компромисс между
точностью и стоимостью. Чем меньше выборка, тем меньше точность, но тем
больше денег мы экономим. Этот компромисс достигается путем выяснения
требуемой точности и доступным бюджетом. Но следует помнить, что даже
исследовав все совокупность данных, не всегда точность может быть 100%-
ной. Могут возникнуть те же самые проблемы, что возникают и в выборках –
тенденциозность, недополучение данных и прочее.
130

Часть III. Статистические методы Тема 7. Распределения
131
Часть III. Статистические методы
Тема 7. Распределения
7.1. Введение
После изучения этой темы мы узнаем, как и почему распределения,
особенно стандартные, могут быть нам полезны. Представление чисел в
форме распределений помогает одновременно в их описании, и в их анализе.
Распределения могут быть получены из собранных данных, или извлечены
математически зная ситуацию, при которой эти данные были сгенерированы.
Распределения, полученные математическим путем, называются
стандартными распределениями. Будут рассмотренные два стандартных
распределения: биноминальное и нормальное.
Некоторые положения данной темы требуют математического
доказательства и некоторых знаний в области высшей математики. Где
возможно, математические выражения не используются – ведь цель нашего
курса – это рассмотрение практического применения распределений.
Мы уже встречались с некоторыми применениями распределений. В
теме №5 о сводных измерениях мы рассмотрели симметричное
распределение (оценки за вождение), U-распределение (просмотр сериала),
обратное J-распределение (больные в фирме). Эти распределения, а особенно
их графические представления, явились тогда описательной частью данных.
Сегодня же мы обратим более пристальное внимание на то, как
распределения могут быть использованы при анализе данных.
Существует два общих вида распределений – наблюдаемое и
стандартное. Последнее также известно как теоретическое или
вероятностное распределение.
131

Часть III. Статистические методы Тема 7. Распределения
132
Наблюдаемое же распределение получают из собранных в какой-то
конкретной ситуации данных, и это распределение характеризует именно эту
ситуацию.
Стандартное распределение получают математическим путем и оно
теоретически применимо ко всем ситуациям, представленным
соответствующими характеристиками. Стандартные распределения имеют
преимущества перед наблюдаемыми в том, что не тратится время на сбор
информации.
7.2. Наблюдаемые распределения
Наблюдаемые распределения начинаются со сбора числовой
информации. Числа в данном случае – это значения той или иной
переменной, которую мы изучаем. То есть это что-либо, что может быть
измерено и для чего одно измерение к другому с течением времени
изменяется. Например, переменной может быть доля рынка какого-нибудь
известного безалкогольного напитка в 100 торговых центрах Европы, как это
показано на рис.1.
Рис.1
132

Часть III. Статистические методы Тема 7. Распределения
133
На рис.1 числа представлены очень беспорядочно. Как обычно и
обстоит дело с полученными откуда-то данными. Данные эти могут быть
откуда угодно – из какого-либо отчета, из компьютерной распечатки, они
могут быть результатом анализа оплаченных счетов и т. п. В первую очередь,
как обычно, отсортируем эти данные. После сортировки мы получим что-то
вроде рис.2.
Рис.2
Конечно, числа – вещь весьма понятная, но не так просто сразу сказать
о среднем значении, о разбросе данных. Другими словами, не так просто
«почувствовать» данные. Итак, следующий шаг – классификация данных.
Классификация, как вы помните, это группировка чисел в диапазоны, такие
как 20-25, для того, чтобы с данными стало легче управляться. Каждый
диапазон, класс имеет свою частоту, которая есть количество наблюдений
(точек данных), которые в этот класс попадают. Таблица частот представлена
на рис.3.
Рис.3
133

Часть III. Статистические методы Тема 7. Распределения
134
Эта таблица показывает, что 12 точек данных (или другими словами
доли рынка в 12 торговых центрах) больше 10, но меньше или равны 15; 31
точка больше 15, но меньше или равна 20 и т. д. Точки данных еще называют
наблюдениями или отсчетами. По такой таблице мы уже легко узнаем
среднее значение и пределы изменения переменной. Большая часть чисел
лежит в пределах 15 и 25 с экстремумами чуть больше 0 и чуть меньше 40.
Далее, как помните, строится частотная диаграмма (см.рис.4).
Рис.4
Эта диаграмма показывает нам, что данные распределены весьма
симметрично, и большинство данных находится посередине всего диапазона.
Для описательных целей, таким образом, частотная диаграмма подходит как
нельзя лучше. И нет смысла добавлять в нее что-то еще, или как-то её
видоизменять.
Если же данные требуется анализировать далее, то следующим шагом
будет построение вероятностной гистограммы на основе частотной. Так как
общая частота равна 100 (всего 100 торговых центров), то частота 2 станет
вероятностью 0.02, 4 станет 0.04, 12 превратится в 0.12 и т. д. Форма
гистограммы, несомненно, останется неизменной. А раз гистограмма теперь
представлена вероятностями, то мы имеем полное право назвать ее
распределением.
Далее мы можем заняться анализом данных. Например, чему равна
вероятность доли рынка между 10 и 20 (процентами)? Согласно рис.3 (и
рис.4) это будет 0.12+0.31=0.43.
134

Часть III. Статистические методы Тема 7. Распределения
135
На другой вопрос мы также без труда сможем ответить. Какова
вероятность того, что доля рынка окажется меньше 15%? Ответ таков –
0.02+0.05+0.12=0.19.
Я думаю, что процесс анализа наблюдаемых распределений Вам
понятен. И для закрепления материала выполним такое задание.
На рис.5 показано количество доставок продуктов питания в магазин в
течение года – 300 рабочих дней (количество доставок в данном случае это
количество рейсов грузовиков на склад магазина). Частоты были превращены
в проценты, а затем проценты – в вероятности.
Рис.5
На рис.6 показана вероятностная диаграмма, полученная на основе этой
таблицы.
Рис.6
Задание (а): технические возможности магазина позволяют обслуживать не
более 29 грузовиков в день. Иначе рабочим придется работать сверхурочно.
Какова вероятность того, что возникнет такая ситуация?
Ответ:
135

Часть III. Статистические методы Тема 7. Распределения
136
С вероятностью 0.30 может возникнуть ситуация, связанная со сверхурочной
работой.
Задание (б): технические возможности по разгрузке грузовиков с товарами
могут быть увеличены с 29 грузовиков в день путем приобретения более
мощного оборудования или найма новых работников. Какого значения
достигнет пропусканная способность магазина, что если после покупки
нового разгрузочного оборудования вероятность переработки составила 0.10?
Ответ: P(доставок больше чем X)=0.10
Мы знаем, что P(50+)=0.06, P(40-49)=0.10
Разбиваем P(40-49) на части P(40-45)=0.06, P(46-49)=0.04
Следовательно P(доставок больше чем 45)= P(46-49)+P(50+)=0.04+0.06=0.10. Поэтому Х=45. Следовательно, пропускная способность магазина увеличена
до 45 машин в день.
Альтернативное представление частотного распределения – это
кумулятивное частотное распределение. Вместо того, чтобы показывать
частоту для каждого класса, кумулятивное частотное распределение
показывает частоту для текущего класса плюс частота всех предыдущих
классов. Посмотрите на рис.7.
Рис.7
Вместо записи в таблицу диапазонов 0-9, 10-19 и т. д. мы видим в
таблице записи <9, <19 и т. д. Как вариант, кумулятивное частотное
распределение может быть записано и с обратным знаком неравенства как
это сделано в рис.8.
136
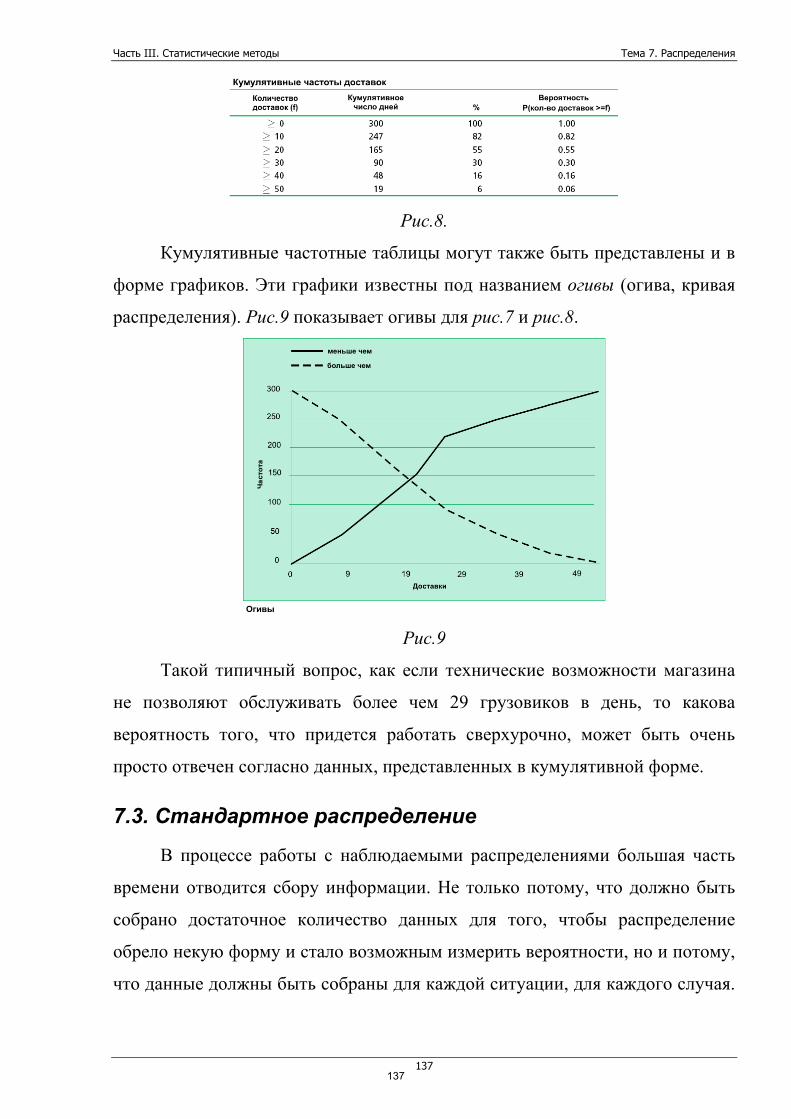
Часть III. Статистические методы Тема 7. Распределения
137
Рис.8.
Кумулятивные частотные таблицы могут также быть представлены и в
форме графиков. Эти графики известны под названием огивы (огива, кривая
распределения). Рис.9 показывает огивы для рис.7 и рис.8.
Рис.9
Такой типичный вопрос, как если технические возможности магазина
не позволяют обслуживать более чем 29 грузовиков в день, то какова
вероятность того, что придется работать сверхурочно, может быть очень
просто отвечен согласно данных, представленных в кумулятивной форме.
7.3. Стандартное распределение
В процессе работы с наблюдаемыми распределениями большая часть
времени отводится сбору информации. Не только потому, что должно быть
собрано достаточное количество данных для того, чтобы распределение
обрело некую форму и стало возможным измерить вероятности, но и потому,
что данные должны быть собраны для каждой ситуации, для каждого случая.
137

Часть III. Статистические методы Тема 7. Распределения
138
Стандартные распределения призваны ликвидировать эту проблему –
проблему сбора данных.
Стандартные распределения – это такие распределения, которые
получены математическим путем из теоретической ситуации.
Характеристики такой ситуации выражаются математически и
результирующее распределение рассчитывается по формуле (то есть
рассчитываются вероятности того, что переменная примет то или иное
значение). Другими словами, вероятности измеряются не методом
относительных частот (как в наблюдаемых распределениях) а методом
априори. И когда реальная ситуация напоминает нам теоретическую, то мы
применяем стандартное распределение и избавляемся от сбора данных.
Например, какое распределение получится, если мы будем бросать
монету? Если говорить о переменной, то она будет принимать значения
«орел» или «решка». Получить стандартное распределение в этой ситуации
совсем просто. Орел и решка в этой ситуации равны. Поэтому
распределением будет таким:
Р(Решка)=0.5 и Р(Орел)=0.5
Наблюдаемое распределение в данном случае могло бы быть получено
бросанием монеты большое количество раз, подсчетом количества
выпадений орла и решки, и затем вычислением вероятности того или иного
события.
В данном случае стандартное и наблюдаемое распределения будут
примерно равны (хотя может быть и не совсем точно равны).
Одно из наиболее часто используемых стандартных распределений
называется нормальным. Оно получено из теоретической ситуации, при
которой значение переменной, генерируемой в ходе какого-то процесса,
должно быть постоянным. Но значение этой переменной не совсем
постоянно из-за некоторых небольших возмущений. В результате значения
переменной сгруппированы вокруг (вблизи) некоего постоянного значения.
Математическое выражение такой ситуации может быть использовано для
138

Часть III. Статистические методы Тема 7. Распределения
139
подсчета вероятности того, что переменная примет отличное от константы
значение.
Как Вы помните – типичный случай нормального распределения – это
результат работы хлебобулочного станка, который должен изготавливать
буханки хлеба строго определенной массы. Или другой пример – станок
должен нарезать прутки металла одинаковой толщины. Но прутки слегка
отличаются друг от друга длинной – это связано и с человеческим фактором
(ошибки оператора), с вибрацией станка, загрязнения измерительного
устройства станка и т. п. Знания параметров нормального распределения
позволяют предсказывать процент деталей, которые попадут в разрешенный
(заданный) интервал длин. Нормальное распределение используется во
многих сходных ситуациях. Мы поговорим о нем чуть позже.
Также существуют и другие стандартные распределения, которые
исходят из ситуаций с другими характеристиками.
В заключение этого раздела отметим, что использование наблюдаемых
распределений подразумевает сбор данных, расчет вероятностей и
построение гистограмм; использование стандартных распределений
подразумевает то, что сгенерированные математически теоретические
данные весьма напоминают ту или иную реальную ситуацию и те или иные
реальные данные.
7.4. Биноминальное распределение
Одно из самых первых стандартных распределений, которое начала
изучать статистика, было биноминальное распределение.
7.4.1. Характеристики биноминального распределения
Биноминальное распределение дискретно (значения, которые
принимает переменная, всегда отличаются между собой на равную
величину). На рис.10 показаны примеры биноминальных распределений.
139

Часть III. Статистические методы Тема 7. Распределения
140
Рис.10
На примере мы видим 3 распределения, причем первое имеет правую
ассиметрию, второе – симметричное, третье – имеет левую ассиметрию.
7.4.2. Ситуации биноминального распределения
Как и все стандартные распределения, биноминальное строится
математически из теоретической ситуации. Вот пример теоретической
ситуации, когда можно говорить о биноминальном распределении:
Элементы генеральной статистической совокупности могут быть двух
типов. Каждый из элементов может быть одного и только одного типа. Доля
элементов первого типа в совокупности известна и равна Р. Тогда доля
элементов второго типа равна 1-Р. Взята случайная выборка из Н элементов.
Так как выборка случайна, то число элементов первого типа неизвестно (их
количество может быть от 0 до Н).
Из этой теоретической ситуации может быть подсчитана вероятность
того, что элементы первого типа в том или ином объеме попадут в выборку.
Если же собрать достаточно большое число выборок, то можно будет
построить гистограмму, в которой переменной будет число элементов
первого типа в выборке. Вероятности, измеренные из гистограммы, будут
достаточно хорошо совпадать с теоретически подсчитанными вероятностями
(может быть не абсолютное совпадение, все дело случая, так же как и с
монетами). Вероятности, подсчитанные теоретически, будут называться
биноминальными вероятностями, а распределение, сформированное из этих
вероятностей, будет называться биноминальным распределением.
140

Часть III. Статистические методы Тема 7. Распределения
141
Рассмотрим такое распределение на другом примере. Представим
станок, который делает микрочипы для детских электронных игрушек. Чип
после изготовления должен быть проверен и признан годным или негодным.
Станок сделан так, что процент брака составляет не более 20%. Была
отобрана выборка из 30 чипов. Предполагая, что в среднем 20% чипов
дефектны, биноминальная вероятность говорит нам о возможности того, что
выборка содержит от 0 до 30 дефектных чипа. Вероятности эти даны в
специальных таблицах биноминального распределения. Если взять несколько
выборок по 30 чипов, то мы получим распределение числа дефектных чипов
по выборкам. Частоты этого распределения должны совпадать с
теоретически подсчитанными вероятностями. Если этого не случится, то это
произойдет лишь по чистой случайности. Или это будет говорить о том, что
начальное предположение о 20% дефектных чипов было неверным.
Стандартные распределения часто используются таким образом.
Теоретические вероятности сравниваются с наблюдаемыми частотами, и
различие между ними будет говорить о том, что изначальные предположения
(в нашем случае о 20% дефектных чипов) были неверными.
Итак, биноминальное распределение имеет место в том случае, если мы
имеем дело с двумя (binom) типами элементов (дефектный/исправный,
плохой/хороший). Биноминальные вероятности – это вероятности получения
различного числа каждого из типов элементов в выборке.
Биноминальные распределения часто встречаются там, где:
• Происходят опросы общественного мнения (согласен/не согласен,
да/нет)
• Продажа (разделение продано/не продано)
• Периодические осмотры оборудования (как в нашем примере).
141

Часть III. Статистические методы Тема 7. Распределения
142
7.4.3. Использование биноминальных таблиц
Чаще всего при работе с биноминальными распределениями не
проводят математических расчетов для анализа вероятности, а используют
специальные биноминальные таблицы.
Давайте попробуем воспользоваться такими таблицами, чтобы решить
несколько задач. Если 40% электората США голосуют за республиканскую
партию, то какова вероятность того, что группа людей из 3 человек содержит
двоих республиканцев? Посмотрите на рис.11.
Рис.11
В самой левой колонке таблицы мы видим размер выборки. В данном
случае есть 4 варианта – выборка из 1, 2, 3 и 4 элементов. По горизонтали
указаны вероятности – от 0.05 до 0.50. Дальше смысла нет, ведь вероятность
события 1 равная 0.6 – это то же самое, что вероятность события 2, равная
0.4. Итак, наша выборка состоит из 3 человек. Вероятность – 0.4. По таблице
видно, что 0 республиканцев в такой выборке будут в 21,6% случае, 1
республиканец – в 43,2% случаев, 2 республиканца – в 28,8% случаев, 3 –
6,4% случаев.
Еще один пример. Производитель имеет контракт с поставщиком. В
контракте указано, что не более 5% поставляемого сырья будет дефектным.
Это сырье поступает производителю на многих-многих грузовиках. Из
каждого грузовика берется проба из 20 элементов этого груза. Если 3 или
142

Часть III. Статистические методы Тема 7. Распределения
143
больше из этой выборке дефектны, то грузовик отправляют поставщику
назад. Какова вероятность того, что грузовик будет таки возвращен
поставщику, если даже не нарушается норма 5% дефектного сырья.
Здесь имеет место именно биноминальное распределение. Ведь либо
сырье дефектно, либо кондиционно. Смотрим на таблицу биноминального
распределения для выборки в 20 элементов. Находим нашу вероятность –
0.05. Зная условия, при которых грузовик вернут назад, считаем вероятность
этого события. 0.0596+0.0133+0.0133+0.0022+0.0003≈7.6%.
Рис.12.
7.4.4. Параметры
Распределения на рис.10 различаются между собой, так как
различаются их параметры. Параметры как бы фиксируют контекст, в
котором переменная изменяет свое значение. Биноминальное распределение
имеет два параметра – размер выборки (n), и пропорция элементов первого
типа в генеральной совокупности (p). Когда пропорция около 0.5, то
биноминальное распределение симметрично, если больше, чем 0.5 (иди
меньше), то ассиметрично.
7.4.5. Когда мы выбираем биноминальное распределение
Теоретическая ситуация, когда биноминальное распределение может
быть использовано, требует выполнения некоторых предположений,
143

Часть III. Статистические методы Тема 7. Распределения
144
особенно такого, что выборка сделана случайна. Если этого не соблюсти, то
теоретически полученные вероятности не будут отражать реальное
положение вещей. Не всегда возможно убедиться в том, что выборки
сделаны случайно. В таком случае для нескольких выборок рассчитываются
вероятности опытным путем и затем сравниваются с теоретическими
(табличными) вероятностями. Если точность удовлетворяет – то значит
биноминальным распределением и его таблицами можно пользоваться.
Эта проверка не является частью анализа данных, но она позволяет
сделать вывод – биноминальное ли наше распределение или нет. Даже с теми
же грузовиками. Для начала нужно быть уверенным, что сырье идет именно с
5% брака. Проверив какое-то количество грузовиков, и убедившись, что
именно 35.8% выборок идут без брака, 37.7% выборок имеют один дефект и
т. п. мы будем уверены, что мы правомерно используем биноминальное
распределение.
7.5. Нормальное распределение
Возможно самое употребляемое распределение из стандартных – это
нормальное распределение.
7.5.1. Характеристики нормального распределения
Внешний вид нормального распределения показан на рис.13. Оно
симметрично и график его колоколообразный. Это распределение
непрерывно, в отличие от биноминального или любого наблюдаемого.
Рис.13.
144

Часть III. Статистические методы Тема 7. Распределения
145
Вы также помните, что вероятности в этот распределении считаются не
по высоте графика над осью X, а по площади областей, которые лежат под
кривой. Например, вероятность того, что X лежит между 15 и 25 – это
область под кривой нормального распределения, ограниченная
вертикальными линиями x=15 и х=25.
Существует очень интересная особенность этого распределения.
Заключается она в следующем:
• 68% значений этого распределения лежат между ±1 среднеквадратичное
отклонение от среднего значения
• 95% значений этого распределения лежат между ±2 среднеквадратичных
отклонения от среднего значения
• 99,7% значений этого распределения лежат между ±3 среднеквадратичных
отклонения от среднего значения
Существует специальные статистические таблицы, по которым можно
найти площадь под кривой нормального распределения не только
ограниченную значениями ±1, ±2 и ±3 среднеквадратичных отклонения, но
также и для дробных значений этого параметра.
7.5.2. Ситуации нормального распределения
Нормальное распределение строится математически из следующей
ситуации: проводятся повторяющиеся измерения одной и той же
переменной. Каждый раз, когда проводят измерения – значение этой
переменной может слегка колебаться из-за многочисленных факторов. Эти
колебания могут быть как положительными, так и отрицательными.
Колебания эти абсолютно независимы друг от друга.
Так как позитивные и негативные изменения переменной как бы
уравновешивают друг друга, то, значит, имеется тенденция, что большинство
значений группируется вокруг какого-то центрального значения. И чем
больше отклонение от этого значения в ту или иную сторону, тем меньше
145

Часть III. Статистические методы Тема 7. Распределения
146
таких значений переменной. В итоге на графике мы видим симметричное,
колоколообразное распределение.
Существует множество реальных ситуаций, которые могут быть легко
сопроксиммированы до такой теоретической. Абсолютно не важно знать
причину колебания переменной, которая изменяется таким образом. Вот
лишь несколько примеров ситуаций, которые подчиняются закону
нормального распределения:
• IQ людей
• рост человека одного пола
• размеры продукции, полученной механическим путем
• веса такой же продукции
• средние арифметические больших выборок
В случае IQ людей или их физиологических параметров изменения
связаны со средой обитания людей, которая так или иначе влияет на
параметры человека. Если говорить о деталях, полученных на станках – то
это и вибрации, и неточная настройка станков, и ошибки оператора и пр.
Использование этого распределения при составлении и обработке
выборок – одна из главных областей применения нормального
распределения. Значительная часть нашего следующего занятия будет
связанна именно с использованием нормального распределения при анализе
выборок.
7.5.3. Использование таблиц нормальных кривых
На рис.14 представлена специальная таблица, из которой можно
получить вероятности того или иного события при известном
среднеквадратичном отклонении (на рис. это значение z).
146

Часть III. Статистические методы Тема 7. Распределения
147
Рис.14
Напомню, что вероятность в нормальном распределении – это площадь
под кривой. Чтобы найти площадь под кривой, простирающуюся от среднего
значения до +1.18 среднеквадратичного отклонения воспользуемся таблицей.
Согласно таблице, площадь такой области (и, следовательно, вероятность)
равна 0.3810.
Пример:
Завод производит большое количество консервных банок для
различных видов пищевых продуктов. Один из станков производит крышки,
которые предназначены для банок, в которых будет содержаться кофе.
Диаметры производимых крышек распределяются согласно нормальному
закону, средних их диаметр составляет 10 см и среднеквадратичное
отклонение составляет 0.03 см.
147

Часть III. Статистические методы Тема 7. Распределения
148
(а) Какой процент крышек имеет диаметры в диапазоне от 9.97 см и 10.03
см? Этот случай очень простой. Мы видим, что значения изменяются как раз
в пределах ±1 среднеквадратическое отклонение. Соответственно, вспоминая
сказанное ранее, можно сделать вывод что 68% крышек лежит в указанном
диапазоне. Такой же вывод мы можем получить и из таблицы нормального
распределения.
(б) Крышки, размером более 10.05 см нельзя использовать и их необходимо
отправить на переплавку. За смену делается 8000 крышек. Сколько из них
будет уничтожено (см.рис.7.15)?
Рис.15
Легко подсчитать, что при размере крышки среднее
значение+1.67*среднеквадратичное отклонение крышки являются
негодными [(10.05-10.00)/0.03=1.67]. Теперь мы уже не привязаны к какому
то конкретному значению, а лишь к среднеквадратичному отклонению.
Следовательно, можно воспользоваться таблицей. Ищем значение
вероятности для 1.67 по таблице на рис.14. Значение получается из таблицы,
равное 0.4525. Нас спрашивали о крышках, которые больше, чем 10.05. То
есть вероятность такого события будет 0.5-0.4524=0.0475.
Следовательно, с вероятностью 4.75% крышки изготовленные крышки
придется отправлять на переплавку. Зная, что делается всего 8000 крышек, то
значит, за смену выбросят 4.75% от 8000 крышек, то есть примерно 380
штук.
148
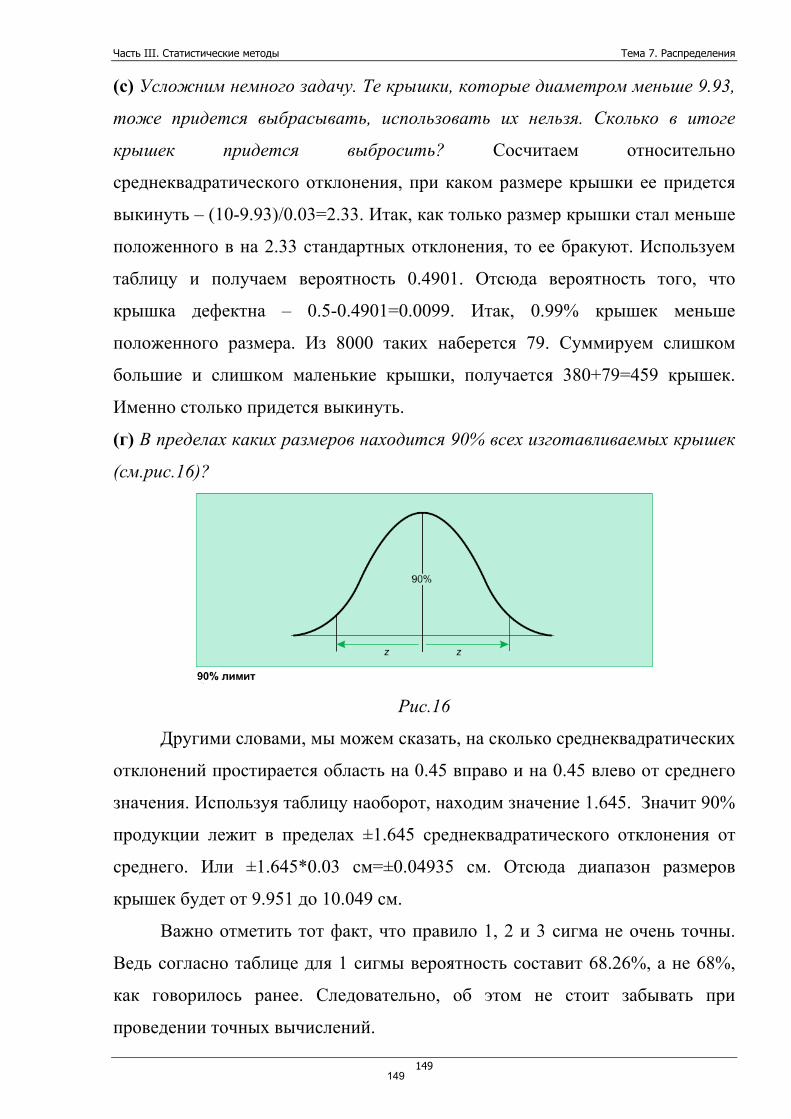
Часть III. Статистические методы Тема 7. Распределения
149
(с) Усложним немного задачу. Те крышки, которые диаметром меньше 9.93,
тоже придется выбрасывать, использовать их нельзя. Сколько в итоге
крышек придется выбросить? Сосчитаем относительно
среднеквадратического отклонения, при каком размере крышки ее придется
выкинуть – (10-9.93)/0.03=2.33. Итак, как только размер крышки стал меньше
положенного в на 2.33 стандартных отклонения, то ее бракуют. Используем
таблицу и получаем вероятность 0.4901. Отсюда вероятность того, что
крышка дефектна – 0.5-0.4901=0.0099. Итак, 0.99% крышек меньше
положенного размера. Из 8000 таких наберется 79. Суммируем слишком
большие и слишком маленькие крышки, получается 380+79=459 крышек.
Именно столько придется выкинуть.
(г) В пределах каких размеров находится 90% всех изготавливаемых крышек
(см.рис.16)?
Рис.16
Другими словами, мы можем сказать, на сколько среднеквадратических
отклонений простирается область на 0.45 вправо и на 0.45 влево от среднего
значения. Используя таблицу наоборот, находим значение 1.645. Значит 90%
продукции лежит в пределах ±1.645 среднеквадратического отклонения от
среднего. Или ±1.645*0.03 см=±0.04935 см. Отсюда диапазон размеров
крышек будет от 9.951 до 10.049 см.
Важно отметить тот факт, что правило 1, 2 и 3 сигма не очень точны.
Ведь согласно таблице для 1 сигмы вероятность составит 68.26%, а не 68%,
как говорилось ранее. Следовательно, об этом не стоит забывать при
проведении точных вычислений.
149
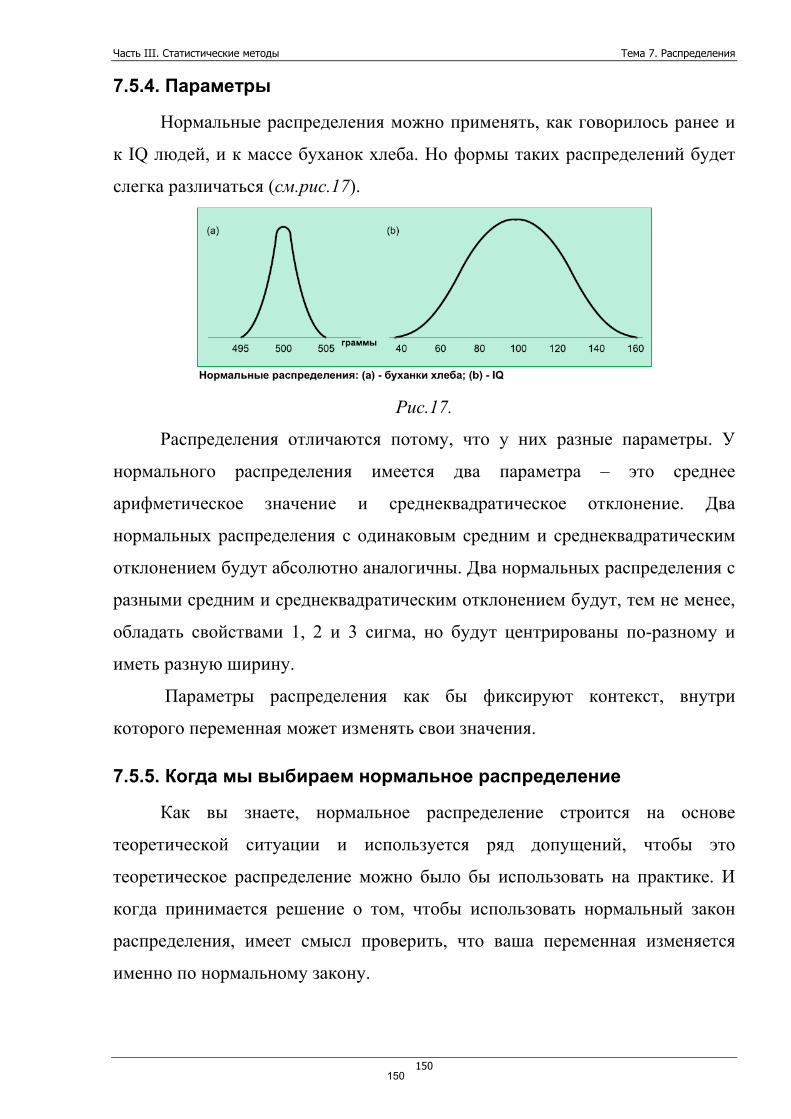
Часть III. Статистические методы Тема 7. Распределения
150
7.5.4. Параметры
Нормальные распределения можно применять, как говорилось ранее и
к IQ людей, и к массе буханок хлеба. Но формы таких распределений будет
слегка различаться (см.рис.17).
Рис.17.
Распределения отличаются потому, что у них разные параметры. У
нормального распределения имеется два параметра – это среднее
арифметическое значение и среднеквадратическое отклонение. Два
нормальных распределения с одинаковым средним и среднеквадратическим
отклонением будут абсолютно аналогичны. Два нормальных распределения с
разными средним и среднеквадратическим отклонением будут, тем не менее,
обладать свойствами 1, 2 и 3 сигма, но будут центрированы по-разному и
иметь разную ширину.
Параметры распределения как бы фиксируют контекст, внутри
которого переменная может изменять свои значения.
7.5.5. Когда мы выбираем нормальное распределение
Как вы знаете, нормальное распределение строится на основе
теоретической ситуации и используется ряд допущений, чтобы это
теоретическое распределение можно было бы использовать на практике. И
когда принимается решение о том, чтобы использовать нормальный закон
распределения, имеет смысл проверить, что ваша переменная изменяется
именно по нормальному закону.
150

Часть III. Статистические методы Тема 7. Распределения
151
Для этого ваши реальные измерения сравниваются с теоретическими
значениями. Например, подходят ли следующие данные под закон
нормального распределения?
Рис.18
С данными будет легче работать, если их представить в виде такой
таблицы:
Рис.19
Теперь сосчитаем среднее (5) и среднеквадратическое отклонение (1.9).
Теперь попробуем, зная два параметра нормального распределения,
использовать правила 1, 2 и 3 сигм.
Рис.20
В данном случае совпадение не идеальное, но для всего лишь двадцати
значений результат вполне удовлетворительный. И мне кажется, что в
данном случае использование закон нормального распределения вполне
допустимо.
Итак, идея проста. Сначала набираем какое-то количество значений.
Находим среднее арифметическое и среднеквадратическое отклонение.
Сравниваем наши измерения и табличные значения. Если результаты
совпадают, то пользуемся нормальным распределением, если нет – то нет.
7.5.6. Аппроксимация биноминального распределения нормальным
Недостатком биноминального распределения является некоторая
сложность его использования. Таблицы биноминального распределения
слишком длинны по сравнению с таблицами нормального распределения.
151

Часть III. Статистические методы Тема 7. Распределения
152
Иногда имеется возможность вместо таблиц биноминального
распределения использовать таблицы нормального распределения.
Это возможно в ситуациях, когда биноминальное распределение более-
менее симметрично. А симметрично оно тогда, когда размер выборки N
достаточно большой, а пропорция Р не очень близка к нулю.
Имеется правило, согласно которому если N*P и N*(1-P) больше 5, то
аппроксимация биноминального распределения нормальным является
допустимой.
Для того, чтобы использовать нормальное распределение вместо
биноминального, нам необходимо знать среднее арифметическое и
среднеквадратичное отклонение. Их можно получить из следующих формул:
либо
.
Рис.21
Далее следуем обычной процедуре работы с таблицами нормального
распределения.
7.6. Заключение
Анализ статистической информации часто вовлекает использование
вероятностей. Например, почтовая служба оценивает качество обслуживания
как вероятность того, что письмо достигнет своего получателя в
определенное количество дней; электрические цепи строят по такому
принципу, что существует лишь крайне малая вероятность того, что они
могут быть перегружены и т. п.
В таких ситуация, а также в тех, о которых мы сегодня говорили, а
также во многих других анализ часто основывается на использовании
наблюдаемых или стандартных распределений.
152

Часть III. Статистические методы Тема 7. Распределения
153
Наблюдаемые распределения характеризуются тем, что необходим
сбор большого количества информации, которое в итоге формирует
гистограммы, и далее по ним оценивают вероятность некоего события.
Стандартные распределения формируется математически из
теоретических ситуаций. Если реальная ситуация совпадает (с определенной
долей приближения) с теоретической, то стандартное распределение может
быть использовано для описания и анализа такой ситуации. В результате
данных требуется собирать значительно меньше.
В этой теме были рассмотрены два стандартных распределения –
биноминальное и нормальное. Для обоих типов распределений мы
рассмотрели:
• Характеристики
• Ситуации, при которых такие распределения случаются
• Использование таблиц этих распределений
• Параметры распределений
• Как можно решить, подходит ли какая то реальная ситуация под
определением того или другого распределения
На самом деле существует значительное количество различных
распределений, сегодня были рассмотрены два наиболее полезных и часто
используемых. Однако существуют ситуации, которые описываются другими
распределениями. Такие случаи мы рассмотрим на следующих занятиях.
153

Часть III. Статистические методы Тема 8. Статистический вывод
154
Тема 8. Статистический вывод
8.1. Введение
Статистический вывод – это набор методов, при помощи которых
данные из выборок могут быть превращены в более общую информацию о
генеральных совокупностях. Статистический вывод имеет в своем составе
две части:
1. Статистическое оценивание – это когда при помощи выборок оценивают
(предсказывают) параметры генеральной совокупности
2. Проверка статистических гипотез – это процедуры принятия решения о
том, поддерживают или отвергают данные выборки некую предложенную
гипотезу о генеральной совокупности.
8.2. Применение методов статистического вывода
8.2.1. Исследования рынка Значительное количество исследований рынка основывается на
изучении выборки покупателей, и затем результаты этого анализа
переносятся на весь потенциальный рынок. Например, производитель
мужских бритвенных принадлежностей решил произвести смену дизайна
упаковки всей линии продуктов. Компании необходимо выяснить количество
(или пропорцию) покупателей этих бритвенных принадлежностей женского
пола. Отдел компании, занимающийся исследованием рынка, рассмотрел
случайную выборку из 1200 покупок, сделанных в разных магазинах этой
фирмы. Выяснилось, что 728 (61%) покупок совершили женщины. Теория
статистического вывода позволяет сделать вывод (не с абсолютной, но в
очень высокой степенью уверенности), что из всех покупателей мужских
бритвенных принадлежностей женщины составляют от 58% до 64%.
154

Часть III. Статистические методы Тема 8. Статистический вывод
155
8.2.2. Медицина Когда открыт новый метод лечения от какой-то болезни, то часто
невозможно и нежелательно назначать его сразу всем, кто страдает от этой
болезни. Обычно это лечение назначается выборке больных, их «прогресс»
при лечении сравнивается с другими пациентами, которые не принимают
нового лечения, лекарства. В данном случае проверка статистических
гипотез помогает решить, есть ли какое-то отличие в выздоровлении
больных из обеих групп, и можно ли из-за этого отличия сказать, что новый
метод лечения действительно хороший.
Например, был разработан новый метод быстрого лечения растянутых
связок. Больничные записи говорят о том, что ранее лечение занимало в
среднем 12 дней с некоторым разбросом в отрицательную и положительную
стороны от этого значения. Далее, новый метод лечения был применен к
выборке из 30 пациентов. Среднее время выздоровления составило 10.5 дней.
Эта разница в 1.5 дня может говорить о том, что лечении действительно
помогает выздоравливать быстрее, или о том, что такое значение мы
получили случайно, ведь люди выздоравливают с несколько разной
скоростью.
Проверка статистических гипотез – это метод, который позволит
нам разделить эти две причины. В данном случае легко доказать, что разница
в 1.5 дня еще не является достаточным доказательством того, что новое
лечение действительно лучше.
8.3. Доверительные пределы
Выборка – это просто какая-то часть данных генеральной
совокупности. Большая же часть данных в итоге остается неизученной. Даже
не смотря на то, что выборка случайна, она, как вы знаете, может быть
нерепрезентативной. Зная эту проблему, мы не можем утверждать что-то о
генеральной совокупности со 100%-ной уверенностью.
155

Часть III. Статистические методы Тема 8. Статистический вывод
156
Поэтому все заключения, выводы о генеральной совокупности обычно
выглядят следующим образом: «Предполагается, что с 95%-ной
уверенностью среднее значение в генеральной совокупности лежит в
пределах 58-64%». Как раз это и имелось в виду, когда мы говорили с
высокой степенью уверенностью о покупках мужских бритвенных
принадлежностей женщинами. Выборка в 1200 покупателей (на которой
строилось наше предположение) может быть непредставительной. В данном
случае это неизвестно, но из-за разброса данных в выборке возможно сказать,
что 19 из 20 таких примеров попадут в указанный нами диапазон 58-64%.
Это и есть «95%-ный доверительный предел».
Все выводы делаются с каким-то определенным уровнем доверия. В
медицинском примере заключение о том, что новое лечение не лучше
старого было также сделано с 95%-ным уровнем доверия. Это значит, если
мы возьмем новую выборку из 100 случаев, то ожидается, что в 95 случаях
заключение «лечение не лучше» будет действительным.
Общепринятым в статистике является уровень в 95%. Если уровень
доверия установить много выше, это будет слишком высокий барьер, и
немного элементов смогут его преодолеть, если уровень доверия будет
слишком низкий, то он будет мало влиять на наши решения. Считается, что в
1 из 20 случаев мы можем ошибаться и это приемлемый уровень риска (это и
есть 95%). Но, конечно же, нет причины в какой-то ситуации не установить
другой уровень доверия, это не запрещено.
8.4. Выборочное распределение среднего
Статистические выводы легко и весьма точно получаются при помощи
распределений среднего значения в выборке. Представьте себе целую серию
выборок, взятых случайно из генеральной совокупности. Среднее значение
от выборки к выборке будет случайным образом колебаться, ведь выборки
были случайны.
156
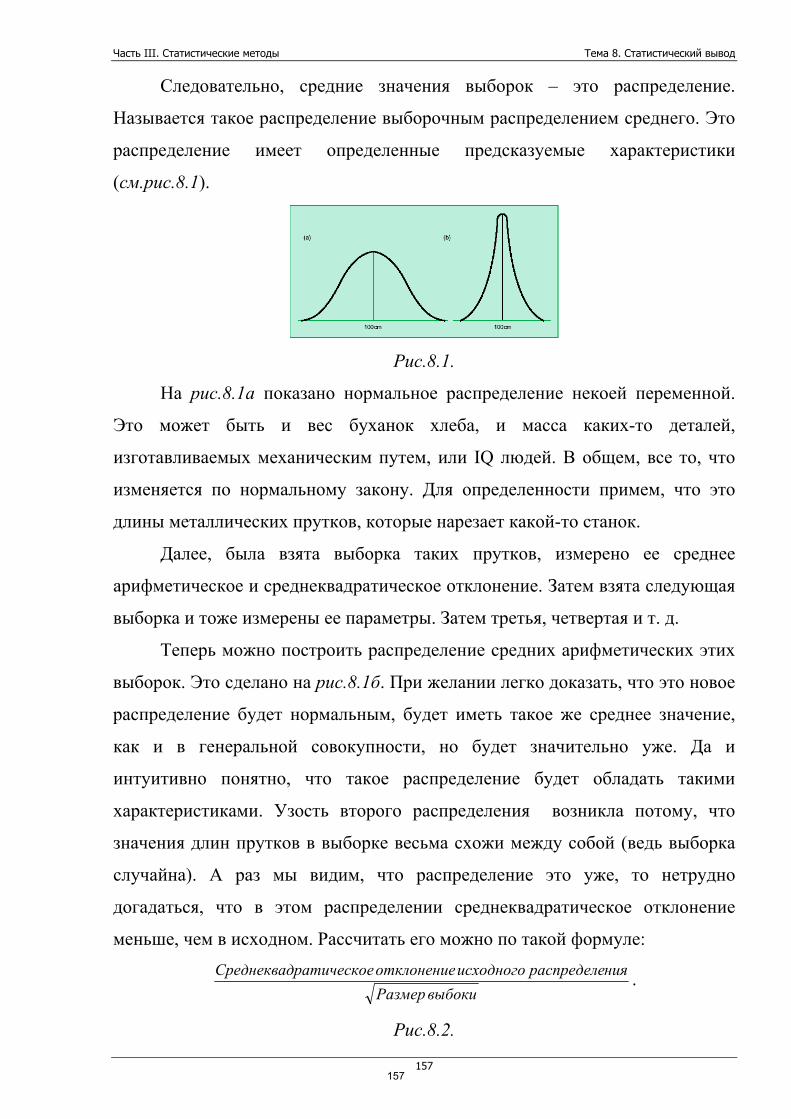
Часть III. Статистические методы Тема 8. Статистический вывод
157
Следовательно, средние значения выборок – это распределение.
Называется такое распределение выборочным распределением среднего. Это
распределение имеет определенные предсказуемые характеристики
(см.рис.8.1).
Рис.8.1.
На рис.8.1а показано нормальное распределение некоей переменной.
Это может быть и вес буханок хлеба, и масса каких-то деталей,
изготавливаемых механическим путем, или IQ людей. В общем, все то, что
изменяется по нормальному закону. Для определенности примем, что это
длины металлических прутков, которые нарезает какой-то станок.
Далее, была взята выборка таких прутков, измерено ее среднее
арифметическое и среднеквадратическое отклонение. Затем взята следующая
выборка и тоже измерены ее параметры. Затем третья, четвертая и т. д.
Теперь можно построить распределение средних арифметических этих
выборок. Это сделано на рис.8.1б. При желании легко доказать, что это новое
распределение будет нормальным, будет иметь такое же среднее значение,
как и в генеральной совокупности, но будет значительно уже. Да и
интуитивно понятно, что такое распределение будет обладать такими
характеристиками. Узость второго распределения возникла потому, что
значения длин прутков в выборке весьма схожи между собой (ведь выборка
случайна). А раз мы видим, что распределение это уже, то нетрудно
догадаться, что в этом распределении среднеквадратическое отклонение
меньше, чем в исходном. Рассчитать его можно по такой формуле:
выбокиРазмернияраспределеисходногоотклонениератическоеСреднеквад .
Рис.8.2.
157
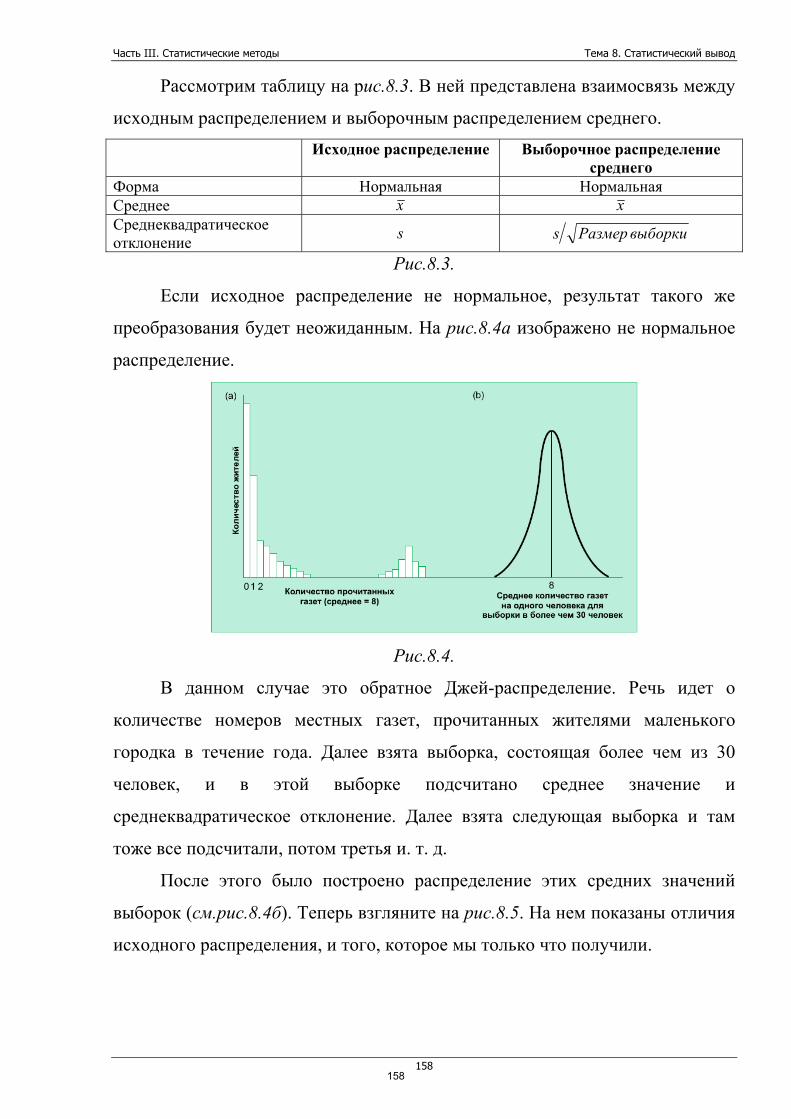
Часть III. Статистические методы Тема 8. Статистический вывод
158
Рассмотрим таблицу на рис.8.3. В ней представлена взаимосвязь между
исходным распределением и выборочным распределением среднего. Исходное распределение Выборочное распределение
среднего Форма Нормальная Нормальная Среднее x x Среднеквадратическое отклонение s выборкиРазмерs
Рис.8.3.
Если исходное распределение не нормальное, результат такого же
преобразования будет неожиданным. На рис.8.4а изображено не нормальное
распределение.
Рис.8.4.
В данном случае это обратное Джей-распределение. Речь идет о
количестве номеров местных газет, прочитанных жителями маленького
городка в течение года. Далее взята выборка, состоящая более чем из 30
человек, и в этой выборке подсчитано среднее значение и
среднеквадратическое отклонение. Далее взята следующая выборка и там
тоже все подсчитали, потом третья и. т. д.
После этого было построено распределение этих средних значений
выборок (см.рис.8.4б). Теперь взгляните на рис.8.5. На нем показаны отличия
исходного распределения, и того, которое мы только что получили.
158

Часть III. Статистические методы Тема 8. Статистический вывод
159
Исходное распределение Выборочное распределение среднего
Форма НЕ нормальная Нормальная Среднее x x Среднеквадратическое отклонение s выборкиРазмерs
Рис.8.5.
Беря выборки размером более 30, результирующее распределение
(выборочное распределение среднего) приняло форму нормального. Число
«30» было давно получено эмпирическим путем.
Если же исходное распределение нормально, то можно ограничиться и
меньшим количеством элементов в выборке. Если исходное распределение
слегка несимметрично, то можно даже ограничиться 4-5 элементами в
выборке, чтобы получить выборочное распределение среднего, которое будет
выглядеть как нормальное.
Существует такая теорема в математике, которая называется теорема о
центральном пределе. В ней говорится, что при увеличении числа элементов
выборки выборочное распределение среднего становится нормальным.
Главное польза от этой теоремы заключается в том, что даже если мы не
знаем, какую форму имеет исходное распределение (а это бывает очень
часто), то, тем не менее, мы можем быть уверены в том, что выборочное
распределение среднего значения будет нормальным. Ну а раз
результирующее распределение является нормальным, то мы может
применять наши знания о нормальных распределениях для анализа данных.
ПРИМЕР
В организации насчитывается несколько тысяч сотрудников. Имеются
записи, которые показывают, что среднее число дней, которые работник
проболел в течение года равно 14, среднеквадратическое отклонение – 6.
Если были взяты случайные выборки по 100 работников, и было подсчитано
среднее значение и среднеквадратическое отклонение для каждой из
выборок, какое распределение мы получим? Каковы будут его параметры?
ОТВЕТ
159

Часть III. Статистические методы Тема 8. Статистический вывод
160
Исходное распределение – это количество дней, которое проболел
каждый сотрудник этой организации. Мы не знаем форму этого
распределения. Но наверняка это будет обратное Джей-распределение, мы
это в сами уже говорили (см.рис.8.6а).
Рис.8.6
Среднее значение для исходного распределения – 14,
среднеквадратическое отклонение – 6. Теперь построим распределение
средних значений выборок по 100 сотрудников (рис.8.6б). Мы можем быть
уверены, что результирующее распределение будет нормальным, так как мы
взяли выборки явно больше чем 30 элементов, то есть выполнили условие
теоремы о центральном пределе. Параметры полученного распределения
будут таковы – среднее значение 14, среднеквадратическое отклонение –
6.01006 = .
8.5. Статистическое оценивание
Статистическое оценивание – это предсказание значений параметров
генеральной совокупности по известным параметрам выборки. Пример на
рис.8.6 может продемонстрировать, каким образом используется оценивание
в статистике. Мы знаем параметры выборок – число элементов 100, среднее –
14, среднеквадратическое – 0.6, распределение нормальное. Значит, что 95%
значений всех таких выборок будет лежать в диапазоне 12.8-15.2 дня. Это
следует из правила нормального распределения – мы знаем, что 95%
значений лежит в диапазоне ±2 среднеквадратических отклонения.
160

Часть III. Статистические методы Тема 8. Статистический вывод
161
Такой пример показывает, как набор средних значений в выборках
может помочь нам оценить среднее значение всей генеральной совокупности.
Но этот пример был не особенно корректный. Ведь мы уже знали, чему
равняется среднее значение в генеральной совокупности. Обычно мы этого
не знаем. Обычно у нас есть одна выборка и только.
Еще пример. Мы ничего не знаем о генеральной совокупности, но у нас
есть выборка из 100 сотрудников. Среднее значение выборки – 11.5,
среднеквадратическое отклонение 0.6. Тогда с уверенностью 95% мы можем
заключить, что среднее значение генеральной совокупности находится в
диапазоне 10.3-12.7 дней (±2 стандартных отклонения выборки). См.рис.8.7.
Рис.8.7.
В данном случае среднее значение выборки (11.5) является точечной
оценкой среднего значения генеральной совокупности; диапазон 10.3-12.7
это 95%-ный доверительный предел для нашей оценки. Обратите внимание,
что на практике берется одна выборка, для того, чтобы сделать такие выводы.
Когда мы оцениваем среднее значение генеральной совокупности, мы
используем среднеквадратическое отклонение в генеральной совокупности.
Но оно известно нам крайне редко.
Обычно его рассчитывают из выборки, и рассчитанное
среднеквадратическое отклонение выборки используют как
среднеквадратическое отклонение генеральной совокупности. К счастью,
статистическая теория позволяет нам делать такое допущение при условии,
что размер выборки превышает 30 элементов.
161

Часть III. Статистические методы Тема 8. Статистический вывод
162
Итак, теперь у нас уже есть две причины (обе эмпирически доказанные
давным-давно учёными), по которым мы должны делать выборки с числом
элементов более 30.
1. Теорема о центральном пределе рекомендует нам брать более 30
значений генеральной совокупности для построения выборки чтобы
распределение стало нормальным.
2. Чтобы мы могли использовать среднеквадратическое отклонение
выборки как среднеквадратическое отклонение генеральной
совокупности необходимо также брать выборки размером более 30
элементов.
Иногда среднеквадратическое отклонение в выборочном
распределении среднего называют стандартной ошибкой. Называют так
потому, что этот параметр указывает нам на доверительный предел, или
другими словами, на возможную ошибку в нашем оценивании.
Необходимо отметить также следующее. Чтобы отличать средние
значения совокупностей и выборок принято обозначать их разными буквами.
Итак, среднее значение генеральной совокупности обозначается греческой
буквой μ. Среднее значение выборки - x . Также, среднеквадратическое
отклонение генеральной совокупности обозначается буквой σ.
Среднеквадратическое отклонение выборки – s.
Тогда для последнего примера можно записать, что доверительный
предел для μ= x ±s.
Общая процедура оценивания среднего значения генеральной
совокупности выглядит так:
1. Взять случайную выборку размером, по крайней мере, 30. Обозначим
размер выборки за n. Минимум 30 нужен потому, чтобы мы могли
использовать теорему о центральном пределе и использовать
среднеквадратическое отклонение выборки как среднеквадратическое
отклонение генеральной совокупности. Можно ограничиться и
меньшей выборкой в том случае, если генеральная совокупность
162

Часть III. Статистические методы Тема 8. Статистический вывод
163
представляет собой нормальное распределение и если
среднеквадратическое отклонение генеральной совокупности известно.
2. Подсчитать среднее значение выборки ( x ) и среднеквадратическое
отклонение выборки (s).
3. Стандартная ошибка или среднеквадратическое отклонение
выборочного распределения среднего рассчитывается по формуле
ns .
4. Точечная оценка генеральной совокупности равна x .
5. Тогда 95%-ный доверительный предел для среднего значения в
генеральной совокупности будет равен nsx 2± .
ПРИМЕР 1
Была взята случайная выборка из 49 ламп, которые проработали в
среднем 1100 часов перед тем, как выйти из строя. Среднеквадратическое
отклонение было 70 часов. Оцените среднее время жизни лампы такой марки
в целом.
ОТВЕТ
1. Выборка случайная. Размер ее достаточен (больше 30). Следовательно,
мы можем применить теореме о центральном пределе и можем
использовать среднеквадратическое отклонение выборки как
среднеквадратическое отклонение генеральной совокупности.
2. Среднее значение выборки 1100, стандартное отклонение 70.
3. Стандартная ошибка равна 104970 = .
4. Точечная оценка равна 1100 часов.
5. 95%-ный доверительный предел в таком случае равен
112010801021100 ÷=⋅± .
Кстати говоря, мы можем также подсчитать доверительный предел
любого другого уровня, скажем 68%-ный. Он будем равен
111010901011100 ÷=⋅± . Также можно найти любой другой предел,
использую таблицы нормального распределения.
163

Часть III. Статистические методы Тема 8. Статистический вывод
164
Обратите внимание, что доверительный предел был найден без всяких
знаний о форме исходного распределения и о его параметрах. Нам
достаточно было иметь выборку и произвести некоторые весьма
простые вычисления.
ПРИМЕР 2
Пользуясь условиями первого примера, необходимо сосчитать какого
размера должна быть выборка, чтобы оценить длину жизни любой лампы из
генеральной совокупности в пределах ±5 часов (с 95%-ной уверенностью).
ОТВЕТ
Теперь ситуация обратная. Мы не знаем размер выборки, но знаем
доверительный предел.
Доверительный предел рассчитывается так - nsx 2±
n702110051100 ⋅±=±
n7025 ⋅=
n1960025 =
784=n .
Заметьте, что увеличение точности ведет к значительному увеличению
числа элементов в выборке. Скажем, чтобы точность была ±10 часов, (в два
раза хуже) размер выборки составит 196 (в четыре раза меньше).
8.6. Основные критерии значимости
Набор критериев значимости, по сути, это методология, которая
позволяет нам судить может ли какой-то вывод, полученный из набора
данных, быть распространен на всю генеральную совокупность. Это
методология включает в себя пять шагов:
1. Формулирование гипотезы. Это может быть какая-то идея,
истинность которой надо подтвердить. Вспоминая пример о лечении
растянутых связках, гипотеза могла быть такова – новое лечение никак
не влияет на скорость выздоровления больных. Или, другими словами,
скорость выздоровления больных, применяющих новый метод лечения
164

Часть III. Статистические методы Тема 8. Статистический вывод
165
и больных, которые лечатся обычным методом, равна. Такая гипотеза
обычно называется нуль-гипотеза.
В науке нуль-гипотезы традиционно являются тем, что исследователь
в ходе своих изысканий должен опровергнуть. Например, в нашем
примере о лечении нуль-гипотезой являлось то, что новое лечение
бесполезно. И мы пытаемся, проведя некоторые вычисления,
опровергнуть это. Тем не менее, нуль-гипотеза не всегда означает
отсутствие отличий. Это зависит от обстоятельств. Например, если
компания, производящая медицинские препараты, заявляет, что ее
новое лекарство снижает температуру больного на 1º, то
контролирующая организация может принять нуль-гипотезу, что
лекарство действительно снижает температуру на 1º, а потом
попытаться эту гипотезу опровергнуть.
В общем, нет каких-то строгих правил, которыми нужно
руководствоваться при выдвижении гипотезы. Чаще всего правила
определяются нашими потребностями и желаемым результатом
проверки.
Альтернативная гипотеза – это то, что мы заключаем, если нуль-
гипотеза опровергнута. Если нуль-гипотеза была, что новое лечение не
помогает, мы ее опровергли, значит, альтернативная гипотеза будет
такой: лечение помогает. Или если нуль-гипотеза была, что новый
препарат снижает температуру на один градус, то альтернативная
гипотеза будет, что температура не снижается. Описанная таким
образом альтернативная гипотеза кажется нам просто обратной к нуль-
гипотезе. Не так ли? Чуть позже мы увидим, что это не совсем так, так
как для в альтернативной гипотезе можно обусловить особые
альтернативы.
165

Часть III. Статистические методы Тема 8. Статистический вывод
166
2. Получение набора доказательств. Это сбор информации об
исследуемом предмете или событии и вычисление различных
статистических параметров. Например, значения скорости
выздоровления наших больных, получающих новое лечение, могут
составить выборку, затем мы может подсчитать среднее время
выздоровления.
3. Определение уровня значимости. Это вероятность, которая является
границей, которая лежит между двумя понятиями – верю и не верю.
Предполагается, что если событие происходит с вероятностью больше,
чем уровень значимости, то это значит, что это не есть необычное
событие и полностью правдоподобно то, что оно произошло по чистой
случайности. Если событие случается с вероятностью меньшей, чем
уровень значимости, тогда оно считается необычным событием, и мы
не верим в то, что оно произошло по чистой случайности. Значит, это
событие произошло не случайно. Обычно уровень значимости
принимается равным 5 процентам (кстати, вместо слов «уровень
значимости 5%» можно говорить «доверительный предел 95%»).
4. Вычисление вероятности того, что выборка подтвердит гипотезу. В
примере про больных мы говорили о том, что при обычном лечении
люди выздоравливали через 12 дней, выборка больных, которых
лечили новым методом, дала результат 10.5.
5. Сравнение вероятности с уровнем значимости. Если рассчитанная
вероятность больше, чем уровень значимости, то, значит, наша
гипотеза верна, и мы ее принимаем. Если вероятность события меньше,
чем установленный уровень значимости, то, значит, такое событие не
могло произойти случайно, и, следовательно, гипотеза отвергается.
166
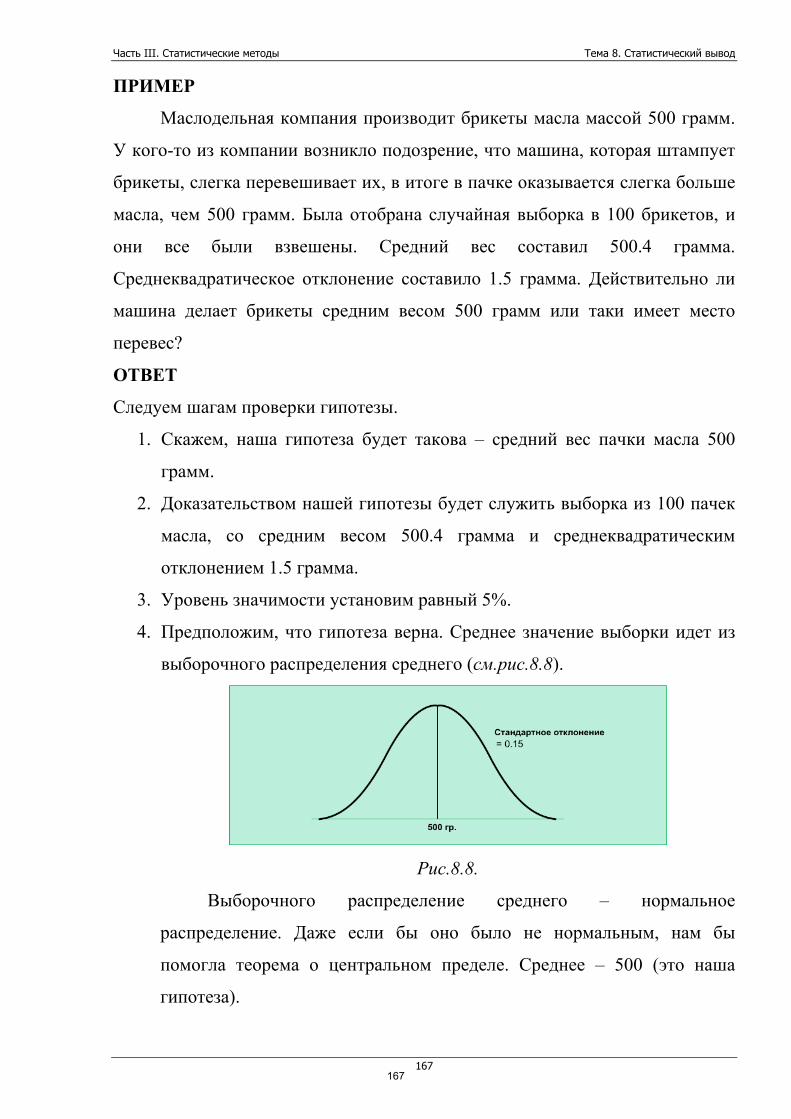
Часть III. Статистические методы Тема 8. Статистический вывод
167
ПРИМЕР
Маслодельная компания производит брикеты масла массой 500 грамм.
У кого-то из компании возникло подозрение, что машина, которая штампует
брикеты, слегка перевешивает их, в итоге в пачке оказывается слегка больше
масла, чем 500 грамм. Была отобрана случайная выборка в 100 брикетов, и
они все были взвешены. Средний вес составил 500.4 грамма.
Среднеквадратическое отклонение составило 1.5 грамма. Действительно ли
машина делает брикеты средним весом 500 грамм или таки имеет место
перевес?
ОТВЕТ
Следуем шагам проверки гипотезы.
1. Скажем, наша гипотеза будет такова – средний вес пачки масла 500
грамм.
2. Доказательством нашей гипотезы будет служить выборка из 100 пачек
масла, со средним весом 500.4 грамма и среднеквадратическим
отклонением 1.5 грамма.
3. Уровень значимости установим равный 5%.
4. Предположим, что гипотеза верна. Среднее значение выборки идет из
выборочного распределения среднего (см.рис.8.8).
Рис.8.8.
Выборочного распределение среднего – нормальное
распределение. Даже если бы оно было не нормальным, нам бы
помогла теорема о центральном пределе. Среднее – 500 (это наша
гипотеза).
167
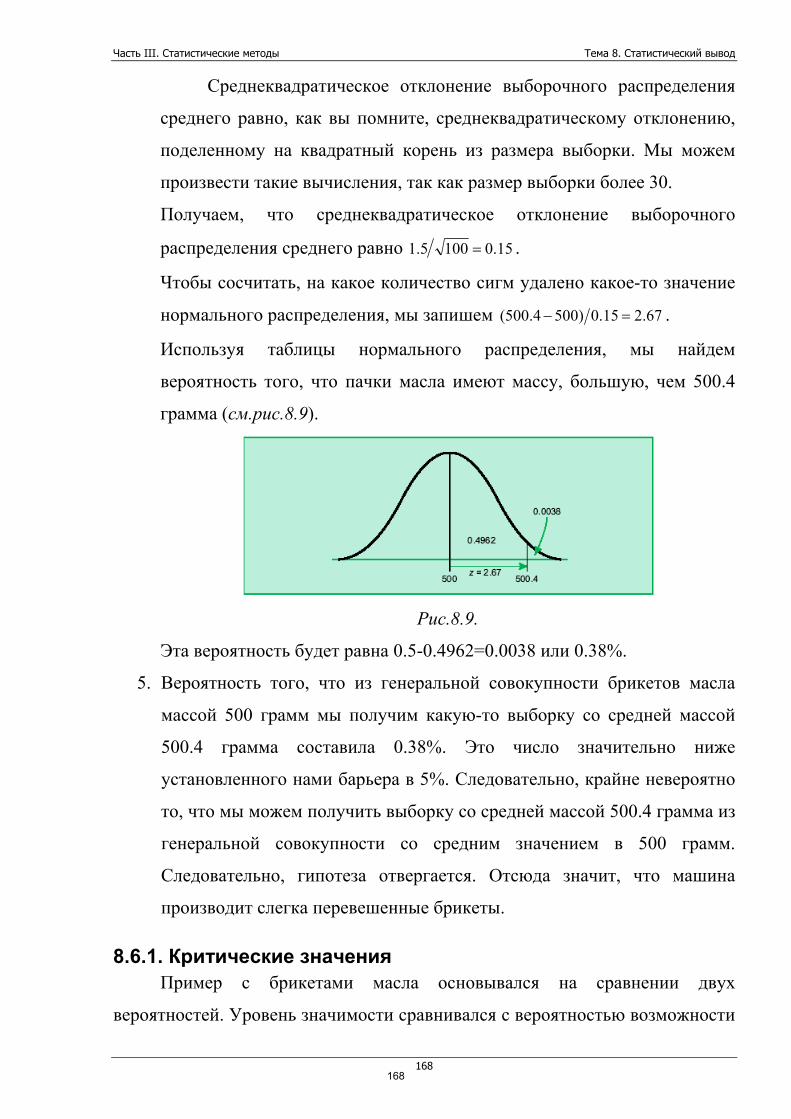
Часть III. Статистические методы Тема 8. Статистический вывод
168
Среднеквадратическое отклонение выборочного распределения
среднего равно, как вы помните, среднеквадратическому отклонению,
поделенному на квадратный корень из размера выборки. Мы можем
произвести такие вычисления, так как размер выборки более 30.
Получаем, что среднеквадратическое отклонение выборочного
распределения среднего равно 15.01005.1 = .
Чтобы сосчитать, на какое количество сигм удалено какое-то значение
нормального распределения, мы запишем 67.215.0)5004.500( =− .
Используя таблицы нормального распределения, мы найдем
вероятность того, что пачки масла имеют массу, большую, чем 500.4
грамма (см.рис.8.9).
Рис.8.9.
Эта вероятность будет равна 0.5-0.4962=0.0038 или 0.38%.
5. Вероятность того, что из генеральной совокупности брикетов масла
массой 500 грамм мы получим какую-то выборку со средней массой
500.4 грамма составила 0.38%. Это число значительно ниже
установленного нами барьера в 5%. Следовательно, крайне невероятно
то, что мы можем получить выборку со средней массой 500.4 грамма из
генеральной совокупности со средним значением в 500 грамм.
Следовательно, гипотеза отвергается. Отсюда значит, что машина
производит слегка перевешенные брикеты.
8.6.1. Критические значения Пример с брикетами масла основывался на сравнении двух
вероятностей. Уровень значимости сравнивался с вероятностью возможности
168
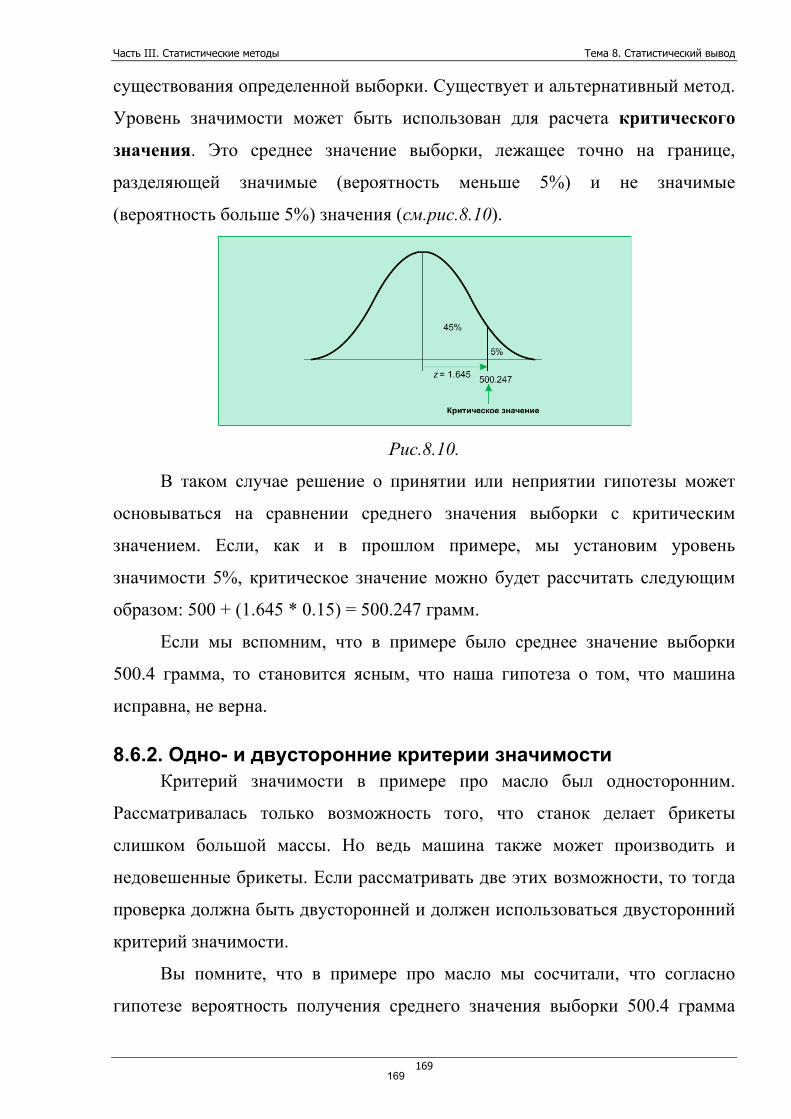
Часть III. Статистические методы Тема 8. Статистический вывод
169
существования определенной выборки. Существует и альтернативный метод.
Уровень значимости может быть использован для расчета критического
значения. Это среднее значение выборки, лежащее точно на границе,
разделяющей значимые (вероятность меньше 5%) и не значимые
(вероятность больше 5%) значения (см.рис.8.10).
Рис.8.10.
В таком случае решение о принятии или неприятии гипотезы может
основываться на сравнении среднего значения выборки с критическим
значением. Если, как и в прошлом примере, мы установим уровень
значимости 5%, критическое значение можно будет рассчитать следующим
образом: 500 + (1.645 * 0.15) = 500.247 грамм.
Если мы вспомним, что в примере было среднее значение выборки
500.4 грамма, то становится ясным, что наша гипотеза о том, что машина
исправна, не верна.
8.6.2. Одно- и двусторонние критерии значимости Критерий значимости в примере про масло был односторонним.
Рассматривалась только возможность того, что станок делает брикеты
слишком большой массы. Но ведь машина также может производить и
недовешенные брикеты. Если рассматривать две этих возможности, то тогда
проверка должна быть двусторонней и должен использоваться двусторонний
критерий значимости.
Вы помните, что в примере про масло мы сосчитали, что согласно
гипотезе вероятность получения среднего значения выборки 500.4 грамма
169
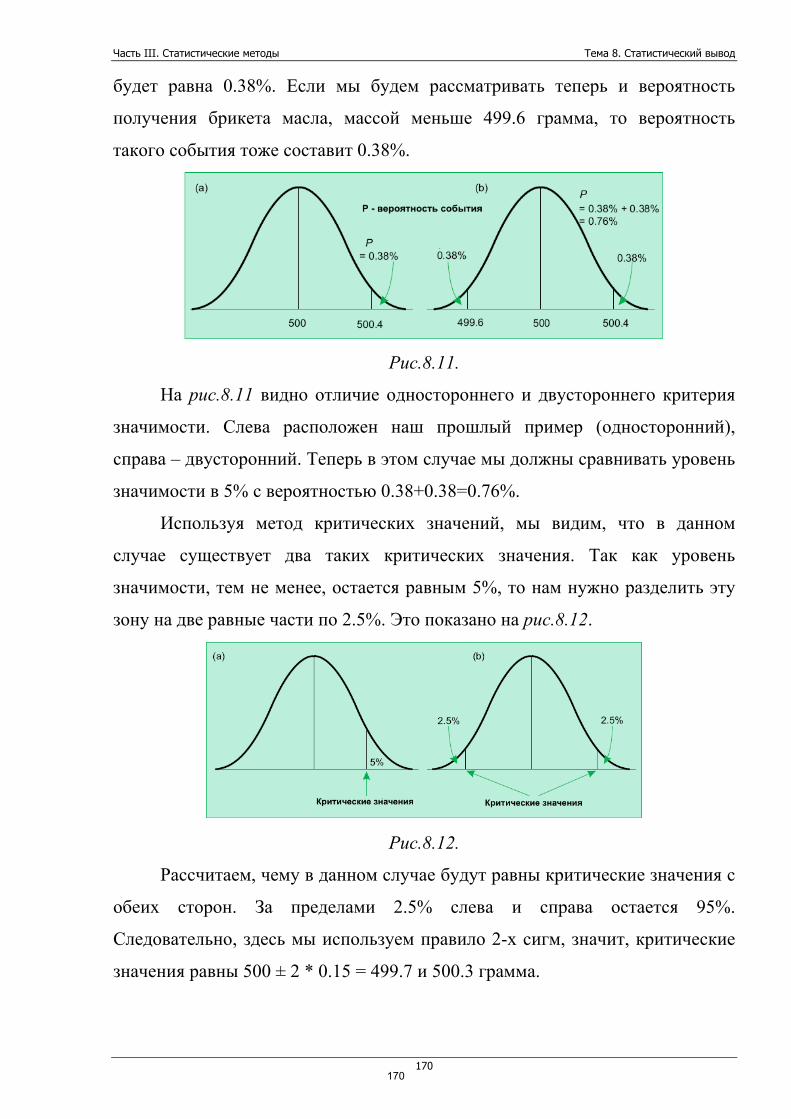
Часть III. Статистические методы Тема 8. Статистический вывод
170
будет равна 0.38%. Если мы будем рассматривать теперь и вероятность
получения брикета масла, массой меньше 499.6 грамма, то вероятность
такого события тоже составит 0.38%.
Рис.8.11.
На рис.8.11 видно отличие одностороннего и двустороннего критерия
значимости. Слева расположен наш прошлый пример (односторонний),
справа – двусторонний. Теперь в этом случае мы должны сравнивать уровень
значимости в 5% с вероятностью 0.38+0.38=0.76%.
Используя метод критических значений, мы видим, что в данном
случае существует два таких критических значения. Так как уровень
значимости, тем не менее, остается равным 5%, то нам нужно разделить эту
зону на две равные части по 2.5%. Это показано на рис.8.12.
Рис.8.12.
Рассчитаем, чему в данном случае будут равны критические значения с
обеих сторон. За пределами 2.5% слева и справа остается 95%.
Следовательно, здесь мы используем правило 2-х сигм, значит, критические
значения равны 500 ± 2 * 0.15 = 499.7 и 500.3 грамма.
170

Часть III. Статистические методы Тема 8. Статистический вывод
171
Затем среднее значение выборки сравнивается с этими двумя
критическими значениями. Если среднее значение выборки лежит между
двумя критическими, то гипотеза принимается, если за пределами – то
отвергается.
Решение о том, применять одно- или двусторонний критерий
значимости зависит от конкретной ситуации. Если брикеты получаются
слишком тяжелые – то мы несем убытки; если слишком легкие – то
возможны проблемы с законом. В данном случае выбор очевиден – надо
использовать двусторонний критерий.
Далее, в данном случае можно было принять две гипотезы – среднее
значение генеральной совокупности РАВНО 500 граммам или среднее
значение генеральной совокупности НЕ РАВНО 500 граммам.
Для надзирающих органов также возможно принятие двух гипотез –
либо среднее значение массы брикета 500 грамм, либо среднее значение
массы брикета меньше 500 грамм. Ведь им не важно, что мы можем делать
слишком тяжелые брикеты. От этого потребитель не страдает.
8.6.3. Ошибки в критериях значимости При проведении анализа данных при помощи критериев значимости
возможны ошибки. Ошибки бывают двух типов и называются ошибка 1 рода
и ошибка 2 рода.
Вероятность получения ошибки 1-го рода равна уровню значимости,
принятому при анализе данных. Если мы установили уровень значимости
равный 5%, то и вероятность того, что мы ошибочно отвергнем верную
нуль-гипотезу, составляет 5%.
Ошибки 2-го рода возникают тогда, когда мы ошибочно принимаем
гипотезу, которая на самом деле не верна. Вероятность возникновения
ошибки сосчитать несколько сложнее, так как она требует определенных
знаний об альтернативной гипотезе. Если наша гипотеза (нуль-гипотеза)
отвергается, то соответственно принимается альтернативная гипотеза. Так
171

Часть III. Статистические методы Тема 8. Статистический вывод
172
вот, ошибка второго рода – это вероятность ошибочного принятия нуль
гипотезы или (что тоже самое) непринятия альтернативной гипотезы.
Такая вероятность не может быть подсчитана за исключением случаев,
когда альтернативная гипотеза точно изложена. В примере с пачками масла
нуль-гипотеза говорила нам, что пачки масла весят ровно 500 грамм. Если
альтернативная гипотеза была бы такова – пачки масла весят в среднем 490
грамм, то тогда вероятность ошибочного принятия такой альтернативной
гипотезы может быть подсчитана. Если же альтернативная гипотеза была бы
такова «средняя масса пачки не равна 500 граммам», то вероятность ее
неверного принятия не может быть подсчитана.
На практике действительно существуют такие ситуации, когда можно
составить конкретную альтернативную гипотезу, а бывают такие, когда это
сделать непросто.
Вероятность правильного принятия альтернативной гипотезы – это
мощность критерия.
Подводя итог:
1. Если нуль-гипотеза верна (за уровень значимости примем 5%):
• Р(верного принятия нуль-гипотезы)=95%
• Р(ошибочного отклонения нуль-гипотезы)=5% (ошибка 1 рода)
2. Если верна альтернативная гипотеза:
• Р(верного принятия альтернативной гипотезы)=мощности критерия
• Р(ошибочного отклонения альтернативной гипотезы)=100%-
мощность критерия
ПРИМЕР
Производитель медицинских препаратов заявляет, что им создано
новое лекарство для детей, которое снижает температуру тела на 1ºС в
течении 12 часов. Это лекарство было опробовано на 36 детях. Среднее
снижение температуры составило 0.8ºС, среднеквадратическое отклонение
1.4ºС. С уровнем значимости 5% нужно сделать заключение, что лекарство
172
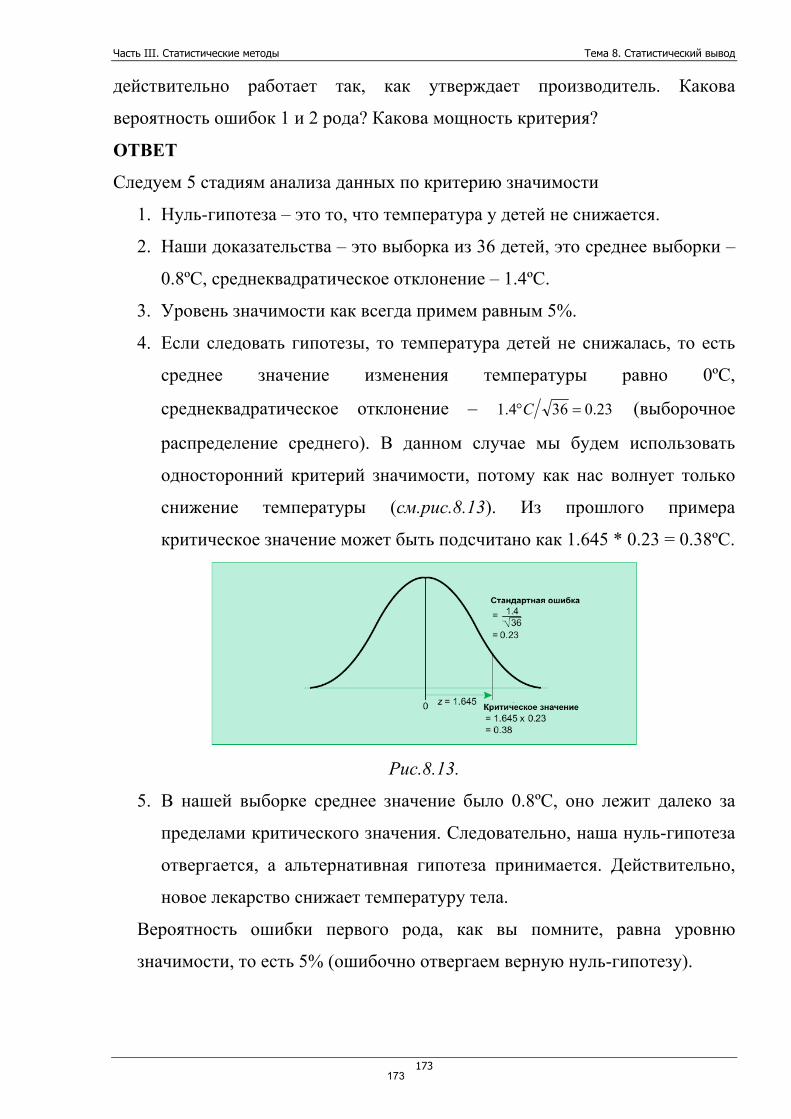
Часть III. Статистические методы Тема 8. Статистический вывод
173
действительно работает так, как утверждает производитель. Какова
вероятность ошибок 1 и 2 рода? Какова мощность критерия?
ОТВЕТ
Следуем 5 стадиям анализа данных по критерию значимости
1. Нуль-гипотеза – это то, что температура у детей не снижается.
2. Наши доказательства – это выборка из 36 детей, это среднее выборки –
0.8ºС, среднеквадратическое отклонение – 1.4ºС.
3. Уровень значимости как всегда примем равным 5%.
4. Если следовать гипотезы, то температура детей не снижалась, то есть
среднее значение изменения температуры равно 0ºС,
среднеквадратическое отклонение – 23.0364.1 =°C (выборочное
распределение среднего). В данном случае мы будем использовать
односторонний критерий значимости, потому как нас волнует только
снижение температуры (см.рис.8.13). Из прошлого примера
критическое значение может быть подсчитано как 1.645 * 0.23 = 0.38ºС.
Рис.8.13.
5. В нашей выборке среднее значение было 0.8ºС, оно лежит далеко за
пределами критического значения. Следовательно, наша нуль-гипотеза
отвергается, а альтернативная гипотеза принимается. Действительно,
новое лекарство снижает температуру тела.
Вероятность ошибки первого рода, как вы помните, равна уровню
значимости, то есть 5% (ошибочно отвергаем верную нуль-гипотезу).
173

Часть III. Статистические методы Тема 8. Статистический вывод
174
Вероятность возникновения ошибки второго рода, то есть отклонения
альтернативной гипотезы должна быть специально подсчитана
(см.рис.8.14).
Рис.8.14.
Критическое значение отмечает границу принять/отклонить для нуль-
гипотезы. Или иначе, отклонить/принять альтернативную гипотезу.
Вероятность ошибочного отклонения альтернативной гипотезы – это область
в хвосте распределения, построенного на альтернативной гипотезе
(закрашена на графике белым).
Для альтернативного распределения значение z равно
z=(0.38-1.0)/0.23=-2.70
Из таблиц нормального распределения находим вероятность,
соответствующую этому значению z. Она равна 0.4965. Поэтому
Р(ошибки второго рода)=0.5-0.4965=0.35%
Мощность критерия – это вероятность принятия альтернативной гипотезы,
когда она верна, в нашем случае мощность равна
100%-0.35%=99.65%
Когда возможно, нужно стремиться к тому, чтобы ошибки обоих родов
были примерно равны. Чем больше меньше разница между ними, тем
соответственно меньше вероятность принятия нами неверной гипотезы.
Как видно, в нашем случае ошибки не равны между собой (или не
сбалансированы). Видно, что намного более вероятно, что мы ошибочно
примем нуль-гипотезу, чем альтернативную. Баланса обычно достигают либо
изменением размера выборки, либо изменением уровня значимости.
174

Часть III. Статистические методы Тема 8. Статистический вывод
175
И в заключение, так как во многих случаях альтернативная гипотеза
неизвестна, соответственно невозможно найти вероятность возникновения
ошибки второго рода и найти мощность критерия.
175

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
176
Часть IV. Статистические зависимости
Тема 9. Регрессия и корреляция
9.1. Введение Регрессия и корреляция рассматривают связь между переменными. По
завершении изучения этой темы мы научимся понимать основные принципы
этих методов и то, как их можно использовать. Мы научимся также
проводить простой анализ при помощи калькулятора или персонального
компьютера. Также будет рассмотрено несколько «подводных камней»,
которыми можно встретиться при практическом применении регрессии.
Большая часть данного занятия посвящена изучению линейной
регрессии и корреляции на самом простом уровне. Главная наша цель – это
изложить основные концепции и принципы регрессии и корреляции и
научиться использовать их на практике.
Итак, регрессия и корреляция рассматривают связь между
переменными. Они изучают, связана ли одна переменная с одной или
несколькими другими. Регрессия – это метод определения математической
зависимости между связанными переменными, корреляция – метод
измерения силы этой взаимосвязи. Или иначе, регрессия показывает, имеется
ли связь, корреляция показывает, насколько это связь сильна и заслуживает
ли эта связь того, чтобы ее можно было использовать.
Например, представьте себе компанию, которая исследуют связь между
объемами продаж одного из ее продуктов и количеством денег, потраченных
на рекламу этого продукта. Цель может быть двояка – либо это предсказание
объемов будущих продаж, либо это оценивание эффективности рекламной
компании. Регрессия и корреляция основывается на данных, которые уже
были когда-то получены, и поэтому первый наш шаг – это сбор этих данных
из каких-то записей, источников. В нашем случае квартальные объемы
176

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
177
продаж и квартальные расходы на рекламу за последние несколько лет
известны.
Если нанести на график объемы продаж и объемы затраченных
финансовых средств на рекламу, то получится диаграмма разброса,
показанная на рис.1.
Рис.1.
Каждая точка (или наблюдение) относится к одному кварталу.
Например, точка «А» относится к кварталу, когда на рекламу было затрачено
12000 фунтов, а объем продаж составил 36000 фунтов.
Из этой диаграммы мы видим, что можно грубо провести прямую
линию, связывающую эти две переменные. Регрессия позволяет нам
построить прямую линию примерно такого вида (см.рис.2):
Рис.2.
Эта формула может быть использована для предсказания продаж в
будущих кварталах в зависимости от потраченных на рекламу денег.
Например, если на рекламу предполагается потратить 12000 фунтов, то
прогноз предполагаемых продаж составит 34500 фунтов (21.3+1.1*12).
Обратите внимание, что, не смотря на то, что была предложена прямая
линия, связывающая эти две переменные, не все точки лежат точно на этой
прямой линии. Когда мы положим на рекламу 12000, то результат нашего
выражения не будет равняться 36000 (как это видно по точке «А»), потому
что точка «А» не лежит на прямой. В этом смысле регрессия является
177

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
178
аппроксимацией (приближением). Регрессия включает в себя поиск лучшей
из многих формул, которая бы связывала переменные.
В этой связи ‘34.5’ предпочтительней ‘36’, как прогноз, потому что
этот прогноз использует информацию о нескольких кварталах, ‘36’ же
относится лишь к одному из них и само число ‘36’ может на самом деле
являться неким исключением, одноразовым событием. Так вот, смысл и суть
регрессии в том, чтобы усреднить такие факторы.
В то время как регрессия занимается поиском формулы, корреляция
показывает силу этой взаимосвязи. Она показывает степень взаимосвязи
между переменными. В нашем случае она показывает, будет ли рост
рекламных издержек вести к росту продаж, и насколько сильно будет эта
тенденция прослеживаться с течением времени.
Такой термин как регрессионный анализ очень часто используется и
для регрессии и для корреляции.
Цель нашего занятия, как говорилось уже выше, показать, где
регрессия и корреляция может быть использована, проиллюстрировать
принципы, лежащие в основе регрессии и корреляции и обратить ваше
внимание на некоторые подводные камни при практическом их
использовании. Мы в основном рассмотрим только простую линейную
регрессию. Слово простая в данном случае означает связь лишь двух
переменных; линейная значит, что связь этих переменных будет выглядеть в
виде прямой линии (но не кривой, как в более сложных регрессиях).
9.2. Применение регрессионного анализа
9.2.1. Прогнозирование Прогнозирование очень часто строится на регрессионном анализе.
Переменная, значение которой необходимо предсказать, как бы
противопоставляется той переменной, которая является причиной ее
изменения. Например, это может быть прогнозирование уровня продаж
178
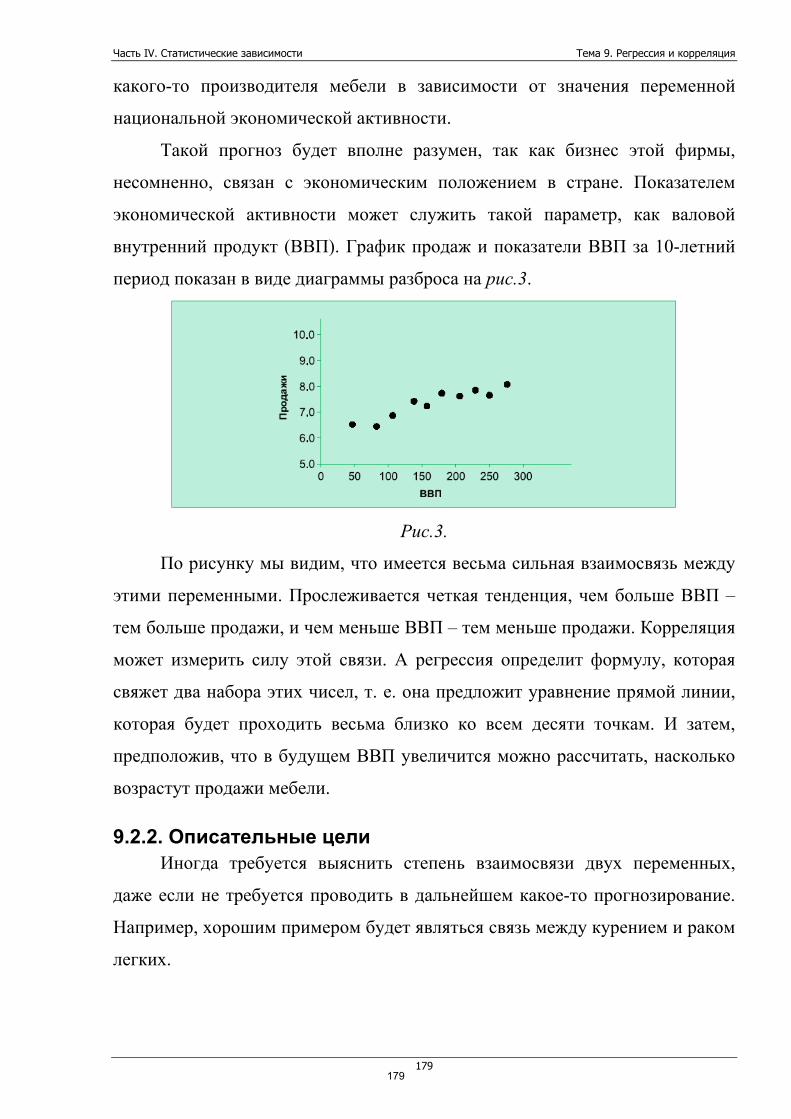
Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
179
какого-то производителя мебели в зависимости от значения переменной
национальной экономической активности.
Такой прогноз будет вполне разумен, так как бизнес этой фирмы,
несомненно, связан с экономическим положением в стране. Показателем
экономической активности может служить такой параметр, как валовой
внутренний продукт (ВВП). График продаж и показатели ВВП за 10-летний
период показан в виде диаграммы разброса на рис.3.
Рис.3.
По рисунку мы видим, что имеется весьма сильная взаимосвязь между
этими переменными. Прослеживается четкая тенденция, чем больше ВВП –
тем больше продажи, и чем меньше ВВП – тем меньше продажи. Корреляция
может измерить силу этой связи. А регрессия определит формулу, которая
свяжет два набора этих чисел, т. е. она предложит уравнение прямой линии,
которая будет проходить весьма близко ко всем десяти точкам. И затем,
предположив, что в будущем ВВП увеличится можно рассчитать, насколько
возрастут продажи мебели.
9.2.2. Описательные цели Иногда требуется выяснить степень взаимосвязи двух переменных,
даже если не требуется проводить в дальнейшем какое-то прогнозирование.
Например, хорошим примером будет являться связь между курением и раком
легких.
179

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
180
Или другой, слегка забавный пример. Исследовалась взаимосвязь
между зарплатами и весами тел руководителей высшего звена. Данные были
собраны в виде выборки из нескольких выбранных случайным образом
американских компаний. Полученная диаграмма разброса показана на рис.4.
Рис.4.
Отметьте отличия принципа построения диаграмм разброса на рис.3 и
рис.4. Первая была построена для разных моментов времени, вторая – для
одного момента времени.
На рис.4 показана взаимосвязь, но мы видим, что она не так сильна, как
предыдущая. В общем можно заключить, что высокие зарплаты связаны с
низким весом, а низкие зарплаты – с большим весом. Но связь эта очень и
очень нечеткая. Точки на диаграмме далеки друг от друга, или, иными
словами, далеки от одной прямой линии. Это и есть слабая корреляция
между переменными. Так как большое значение связано с малым и наоборот,
то такая корреляция называется негативной. В примере про мебель
корреляция была позитивной, так как большие значения ВВП были связаны с
большим объемом продаж.
Цель такого анализа добиться большего понимание того или иного
процесса. Очевидно, что регрессия в данном случае не будет использоваться
для какого-либо предсказания. Идея последнего примера ведь не состояла в
том, чтобы подсказать, сколько килограмм надо сбросить руководителю,
чтобы добиться более высокой зарплаты. Просто результаты такого
изыскания могут явиться отправной точкой для дальнейших, более
углубленных исследований.
180

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
181
9.3. Математика в регрессии и корреляции Простая линейная регрессия относится к случаю с двумя переменными,
и если значения этих переменных нанести на диаграмму, то через них
(примерно) можно провести прямую линию. Математически это значит, что
уравнение, связывающее эти две переменные, выглядит так:
Рис.5.
где «y» и «х» – переменные, а «а» и «b» фиксированные числа, константы. В
примере на рис.1 значение продаж было «y», рекламные расходы – «x», «а»
было равно 21.3, «b» – 1.1.
В общем, простая линейная регрессия – это задача поиска значений «а»
и «b», которые обеспечивали бы лучшую взаимосвязь между двумя
переменными.
9.3.1. Уравнение прямой линии Уравнение прямой линии выглядит как bxay += , где
• a – это точка пересечения, или другими словами это значение y, при
котором прямая пересекает ось ординат (ось y).
• b – это коэффициент наклона, или другими словами изменение
значения у при изменении значения х на одну единицу.
На рис.6 показано два варианта прямой линии, c положительным и
отрицательным коэффициентом наклона.
Рис.6.
181
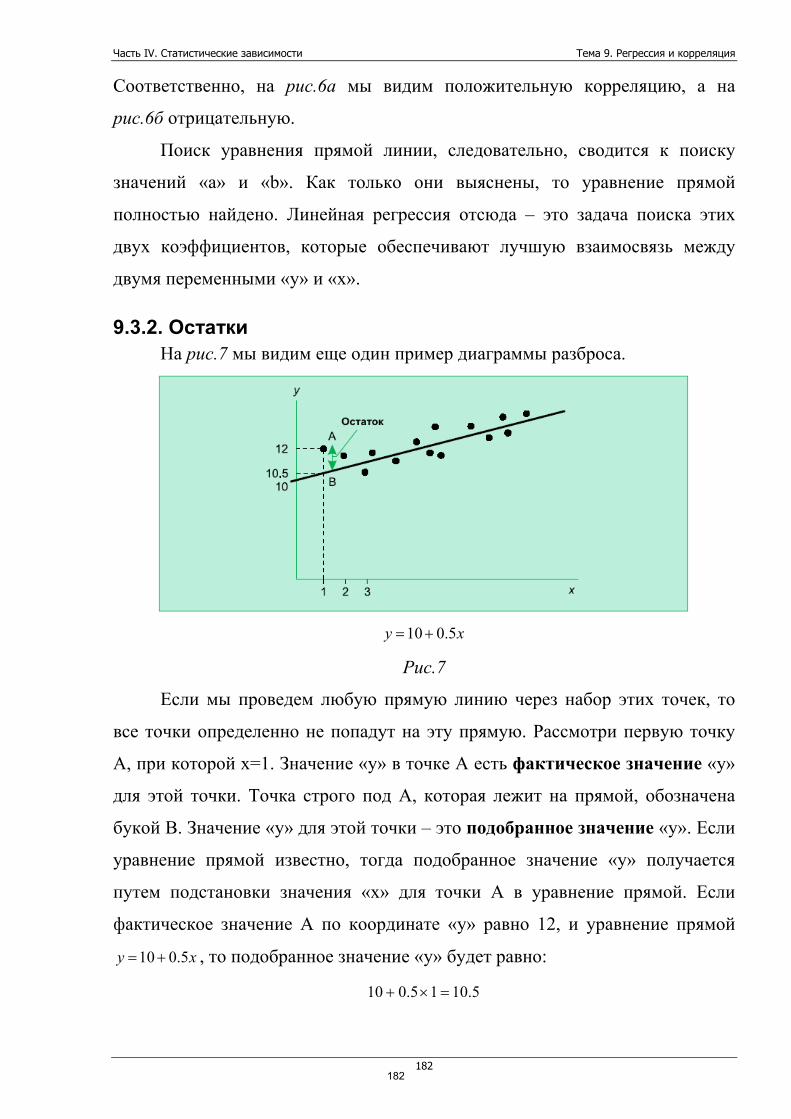
Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
182
Соответственно, на рис.6а мы видим положительную корреляцию, а на
рис.6б отрицательную.
Поиск уравнения прямой линии, следовательно, сводится к поиску
значений «a» и «b». Как только они выяснены, то уравнение прямой
полностью найдено. Линейная регрессия отсюда – это задача поиска этих
двух коэффициентов, которые обеспечивают лучшую взаимосвязь между
двумя переменными «y» и «х».
9.3.2. Остатки На рис.7 мы видим еще один пример диаграммы разброса.
xy 5.010+=
Рис.7
Если мы проведем любую прямую линию через набор этих точек, то
все точки определенно не попадут на эту прямую. Рассмотри первую точку
A, при которой х=1. Значение «у» в точке А есть фактическое значение «у»
для этой точки. Точка строго под А, которая лежит на прямой, обозначена
букой В. Значение «у» для этой точки – это подобранное значение «у». Если
уравнение прямой известно, тогда подобранное значение «у» получается
путем подстановки значения «х» для точки А в уравнение прямой. Если
фактическое значение А по координате «у» равно 12, и уравнение прямой
xy 5.010+= , то подобранное значение «у» будет равно:
5.1015.010 =×+
182

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
183
Разница между фактическим и подобранным значением «у»
называется остатком. В точка А остаток равняется 12-10.5=1.5. Если точка
лежит выше прямой, то остаток положительный, если ниже линии – то
отрицательный, если точка лежит на прямой – то остаток равен нулю. Каждая
точка имеет свой остаток. Ну и остатки будут разные в зависимости от того,
как именно проведена прямая.
9.4. Простая линейная регрессия Для определения того, какая из прямых линий будет самой лучшей для
набора точек, необходим критерий. Такой критерий, который мог бы нам
указать, какая из прямых на самом деле является самой лучшей.
А так как линия должна проходить как можно ближе ко всем точкам,
что критерий должен основываться на том, чтобы остатки были как можно
меньшими по величине.
Один из методов может называть лучшей такую прямую, при
проведении которой сумма всех остатков будет минимальна по сравнению с
любой другой прямой. Это не очень хорошо работает, так как
положительные и отрицательные остатки будут гасить друг друга, и прямая
линия будет иметь сумму даже очень больших остатков равной или близкой
к нулю. Посмотрите пример на рис.8.
Рис.8.
В самом деле, проведя даже очень неудачную линию, сумма остатков
будет равна нулю.
183

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
184
Второй метод предлагает складывать абсолютные значения остатков и
стремиться, чтобы такая сумма тоже была нулевой или близкой к нулю.
Такой подход позволяет избавиться от взаимного погашения положительных
и отрицательных остатков. К сожалению, с чисто математической точки
зрения модуль не очень подходящий элемент, и поэтому (и по ряду других
причин) такой метод используется достаточно редко. Хотя, с появлением
компьютеров, исследователи стали прибегать к нему чаще и чаще.
Третий метод, который традиционно используется, называется
методом наименьших квадратов. Отрицательные знаки устраняются путем
возведением остатков в квадрат. Когда сумма возведенных в квадрат
остатков минимально, то полученная является наилучшей. Другими словами,
лучшая линия это та, при коэффициентах «а» и «b» которой сумма
возведенных в квадрат остатков минимальна.
Или еще можно сказать, что критерием этого метода является
минимальная сумма возведенных в квадрат остатков.
Несмотря на то, что мы установили такой критерий, тем не менее, пока
не очевидно каким образом нам найти уравнение для такой прямой линии.
Оставим математику в «черном ящике», в итоге получим, что:
Рис.9.
Обычно эти формулы не используют напрямую, чаще за нас это делает
компьютер или калькулятор, но давайте разберем один пример для лучшего
усвоения материала.
ПРИМЕР
Найти регрессионную линию для таких точек:
Рис.10.
184

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
185
РЕШЕНИЕ
Из формулы с рис.9 считаем коэффициент «b»
В итоге уравнение прямой будет xy 414+= .
9.5. Корреляция Формулу для расчета коэффициентов «а» и «b» можно использовать
для любого набора парных данных. Соответственно, регрессионная прямая
может быть найдена для любой группы точек.
Даже тогда, когда мы будем видеть на диаграмме разброса точки,
распределенные по окружности, все равно расчетная регрессионная линия
будет прямой. Другими словами, регрессия находит лучшую линию для
набора точек, но не показывает, насколько эта линия является хорошим
представлением для этих точек. Корреляция как раз и заполняет этот пробел
регрессии. Корреляция помогает нам решить, можно ли пользоваться
полученной в итоге линией или нельзя. Имеет ли эта линия какое-либо
практическое значение или нет. Это делается путем определения силы
линейной взаимосвязи, или, иначе, корреляция измеряет одновременно
близость всех точек к той или иной линии.
9.5.1. Коэффициент корреляции Коэффициент корреляции, определяющий силу взаимосвязи между
двумя переменными, обозначается буквой «r» (квадрат этого коэффициента
пишется как большая R2) и вычисляется по такой формуле:
Рис.11.
185
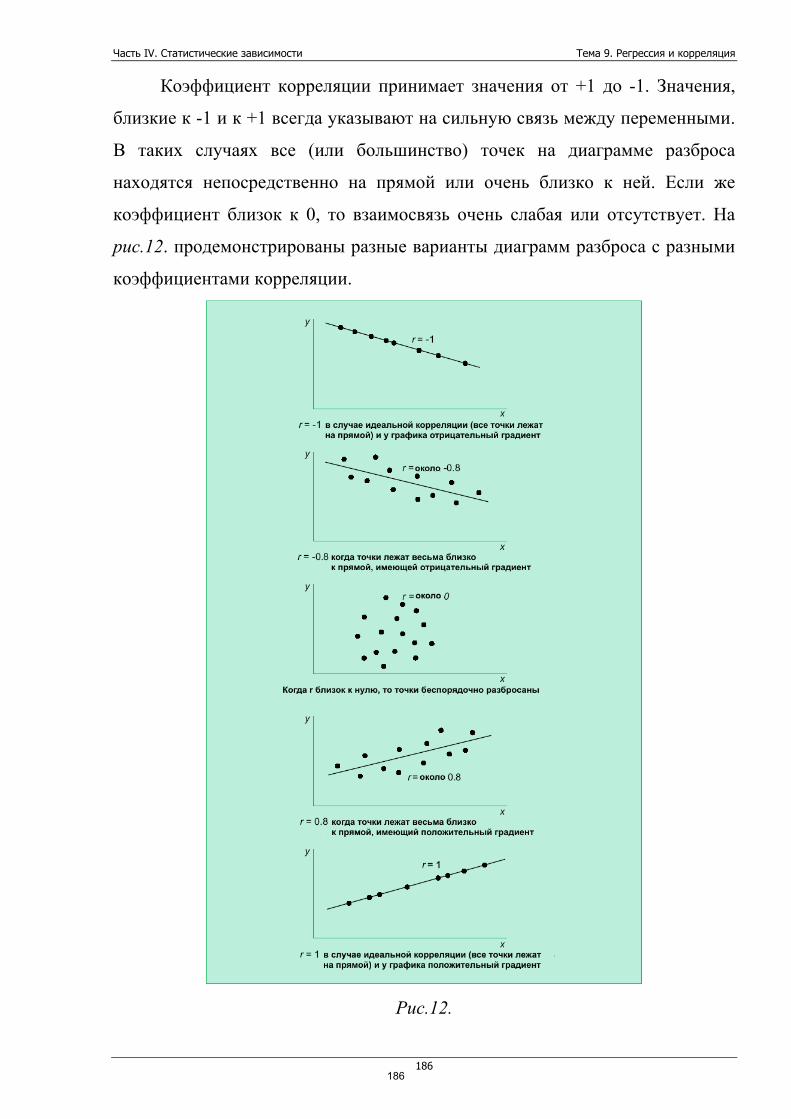
Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
186
Коэффициент корреляции принимает значения от +1 до -1. Значения,
близкие к -1 и к +1 всегда указывают на сильную связь между переменными.
В таких случаях все (или большинство) точек на диаграмме разброса
находятся непосредственно на прямой или очень близко к ней. Если же
коэффициент близок к 0, то взаимосвязь очень слабая или отсутствует. На
рис.12. продемонстрированы разные варианты диаграмм разброса с разными
коэффициентами корреляции.
Рис.12.
186

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
187
Иногда используется коэффициент «r», иногда «R2». Если используется
R2, то значения от 0.75 и выше говорят об очень высокой степени связи
переменных, 0.5-0.75 о достаточной степени взаимосвязи, ниже 0.50 –
взаимосвязь подвергается серьезным сомнениям.
ПРИМЕР
Найти коэффициент корреляции для примера с рис.10.
РЕШЕНИЕ
Кое-что мы уже подсчитали:
Рис.13.
Все, что нам нужно, это найти значение следующего выражения:
Рис.14
И тогда коэффициент корреляции будет равен:
Рис.15.
Коэффициент корреляции весьма близок к 1, что говорит о сильной
положительной корреляции. Если подсчитать коэффициент корреляции R²
(он считается по другой формуле), то результат будет такой:
R²=0.91.
Если извлечь отсюда корень, то мы получим точно такое же значение – 0.95.
187

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
188
9.6. Анализ остатков После того, как найдено регрессионное уравнение, легко подсчитать
чему равняются остатки для каждой из точек. Остатки находятся как разница
между фактическим и подобранным значением. Для простого примера с
известной регрессионной функцией подсчитаны остатки для каждой из точек
(см.рис.16):
Рис.16.
Причина, по которой важно изучать эти остатки заключается в том, что
кроме роли, которую они играют в методе наименьших квадратов, они также
помогают нам решить связаны ли переменные линейно или нет. Конечно,
коэффициент корреляции один из тестов на то, что переменные связаны
линейно. Но этого коэффициента недостаточно. Дополнительная проверка
заключается в том, что остатки должны быть случайны по величине,
показывая тем самым, что в их величинах нет никакой закономерности,
тенденции или порядка.
На рис.17 показан случай, когда коэффициент корреляции весьма
высок, но прямая линия не полностью представляет собой закон, которым на
самом деле связаны переменные.
Рис.17.
188

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
189
Возможно, в данном случае в линейном уравнении регрессии не
учтены некоторые сезонные или циклические колебания. Кратко, если
величина остатков изменяется случайным образом от одного к другому, то
лучшее уравнение регрессии – линейное. Если же остатки изменяются
тенденциозно, по какому-то закону – то линейное уравнение не является
лучшим методом представления этой взаимосвязи.
В статистике также существует большое количество методов, которые
позволяют убедиться в случайности или в неслучайности получающихся
остатков. Самый простой метод, это построить диаграмму разброса остатков,
см.рис.18 (то есть вместо значения «у» откладывать на оси ординат сами
остатки).
Рис.18.
9.7. Регрессионный анализ на персональном компьютере Ситуации, которые мы до сих пор исследовали были простыми
линейными регрессиями небольших наборов данных (несколько
наблюдений). Но даже в этих случаях вычисления коэффициентов были
весьма длинными и достаточно утомительными. К счастью все персональные
компьютеры и инженерные калькуляторы могут рассчитывать регрессию и
корреляцию. Поэтому в наше время искусство правильно проводить
регрессионный анализ – это не есть аккуратное проведение расчетов, но
также и умение интерпретировать длинные распечатки компьютеров,
занимающихся этим однообразным делом.
189

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
190
До сих пор процедура регрессионного анализа выглядела следующим
образом и включала 4 шага:
1) анализ диаграммы разброса
2) расчет регрессионных коэффициентов
3) расчет коэффициента корреляции
4) проверка остатков на случайность
Все эти четыре шага теперь делаются при помощи ПК. Естественно,
что мы не будет обсуждать на занятии, какие кнопки надо нажимать, но сама
процедура регрессионного анализа при помощи компьютерной программы
весьма схожа.
Следующая ситуация будет использована для демонстрации как такой
пакет программ может работать. Компания, производящая одежду пытается
спрогнозировать продажи одежды для 4-летних детей. На первом шаге
анализируется регрессионная модель, связывающая продажи одежды и
рождаемость. Это имеет смысл сделать, так как вполне возможно, что
продажи могут быть связаны с количеством детей, которым нужна одежда. В
ПК уже имеются данные за прошедшие 20 лет о продажах детской одежды и
рождаемости. Назовем эти данные «продажами» и «рождаемостью».
9.7.1. Анализ диаграмм разброса Для создания диаграммы разброса компьютер спросит нас о
переменной, которая должна располагаться по оси ординат (y) и о
переменной, которая должна располагаться по оси абсцисс (x). Пусть у нас
продажи будут по «y», а рождаемость по «х».
На рис.19 показана построенная компьютером диаграмма разброса.
Рис.19.
190

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
191
На ней 20 точек, по одной на каждый из 20 лет. Каждая точка
соответствует определенному уровню продаж в выбранный год. Диаграмма
показывает, что существует весьма строгая линейная зависимость между
этими двумя переменными и поэтому имеет смысл в этом случае
использовать простую линейную регрессию.
Имей мы, скажем, диаграмму как на рис.20, было бы мало причин
использовать линейную регрессию.
Рис.20.
Диаграмма разброса – это первая проверка на то, что дальнейший
анализ вообще имеет смысл. Она также дает аналитику большее понимание
сути исходной ситуации.
9.7.2. Подсчет регрессионных коэффициентов Далее компьютер спросит нас о зависимой переменной (переменной
«у», еще ее называют левосторонняя переменная, у нас это «продажи»), и о
независимой переменной (переменной «х», правосторонняя переменная, у
нас это «рождаемость»). Примерно так будет выглядеть итоговая распечатка
компьютерного пакета (рис.21).
Рис.21.
Эти результаты означают, что уравнение, связывающее продажи и
рождаемость, будет выглядеть так (рис.22):
191

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
192
ьРождаемостПродажи ×+= 14.365.8 Рис.22.
Если рождаемость была 18, то легко сосчитать, что продажи составят
65.17 и так далее…
9.7.3. Подсчет корреляционного коэффициента В той же распечатке с компьютера мы видим, что квадрат
коэффициента корреляции составил 0.93, он показывает весьма высокий
уровень взаимосвязи переменных.
Это подтверждает наше интуитивное предчувствие, полученное из
диаграммы разброса, что данные связаны между собой весьма тесно.
Единственное на этой распечатке, что нам может показаться лишним –
это то, что мы видим на ней среднеквадратическое отклонение остатков –
число 5.62 (другими словами «сигма»). Это значение (не углубляясь в пучину
математической статистики) нам говорит о том, что любое предсказанное
значение по нашему регрессионному уравнению с 95%-ным уровнем доверия
будет лежать в пределах ±2σ, или, для нашего случая ±11.24.
9.7.4. Анализ остатков Для анализа получившихся остатков компьютер построит еще одну
диаграмму разброса, в данном случае диаграмму остатков и подобранных
значений. Такая диаграмма показана на рис.23.
Рис.23.
192
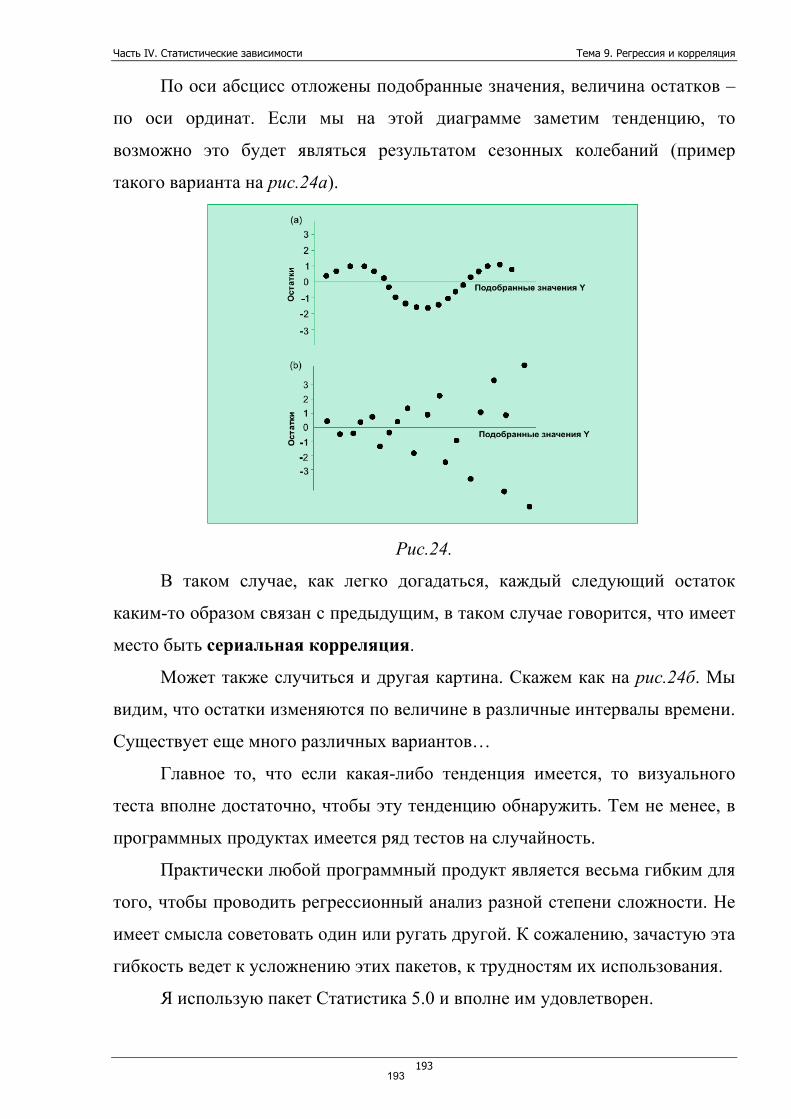
Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
193
По оси абсцисс отложены подобранные значения, величина остатков –
по оси ординат. Если мы на этой диаграмме заметим тенденцию, то
возможно это будет являться результатом сезонных колебаний (пример
такого варианта на рис.24а).
Рис.24.
В таком случае, как легко догадаться, каждый следующий остаток
каким-то образом связан с предыдущим, в таком случае говорится, что имеет
место быть сериальная корреляция.
Может также случиться и другая картина. Скажем как на рис.24б. Мы
видим, что остатки изменяются по величине в различные интервалы времени.
Существует еще много различных вариантов…
Главное то, что если какая-либо тенденция имеется, то визуального
теста вполне достаточно, чтобы эту тенденцию обнаружить. Тем не менее, в
программных продуктах имеется ряд тестов на случайность.
Практически любой программный продукт является весьма гибким для
того, чтобы проводить регрессионный анализ разной степени сложности. Не
имеет смысла советовать один или ругать другой. К сожалению, зачастую эта
гибкость ведет к усложнению этих пакетов, к трудностям их использования.
Я использую пакет Статистика 5.0 и вполне им удовлетворен.
193

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
194
9.8. Замечания о регрессии и корреляции Неаккуратность, некомпетентность, бессистемность – вот возможно
один из основных источников затруднений и ошибок в регрессионном
анализе. Особенно это касается регрессионного анализа, проводимого на
компьютере. Компьютер построит регрессионное уравнение для любого
набора данных, а вот с понимание отнестись к полученной модели и
правильно ее интерпретировать может далеко не каждый.
Важно помнить, что статистика легко может показать, что переменные
как-либо связаны, но она нам не в состоянии ответить на вопрос как
изменение одной переменной влияют на изменения другой.
Приведем такой пример. Допустим, у нас имеется сходная с
предыдущим примером ситуация (высокая корреляция, вполне случайные
остатки). Пусть это будет цена на водку и зарплата служителей церкви. Это
не значит, что эти две переменные причинно-зависимые.
Рост их зарплаты вряд ли приведет к тому, что они станут больше
денег тратить на водку, опустошать прилавки винных магазинов и тем самым
повышать цену на водку. В данном случае более вероятно то, что имеется
третий факт, такой как инфляция или общий уровень достатка в обществе,
который влияет на обе переменные (цена на водку, зарплата духовенства). И
именно поэтому обе этих переменные растут одновременно. Компьютер
заметить этого в принципе не может, и здесь необходимо простое
применение здравого смыла и иногда дополнительных знаний об изучаемом
предмете.
К экстраполяции при помощи регрессионной модели нужно также
относиться с большой осторожностью. Под экстраполяцией в данном случае
понимается использование регрессионного уравнения за пределами того
диапазона, на основе которого была построена модель. Скажем, если мы
построили регрессионное уравнение при значении «х» от 100 до 200, то
прогнозировать значение «у» при х=400 может быть весьма опасным
мероприятием. Ведь нам ничего не известно о том, как себя ведет «у» при
194

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
195
х=400. Хотя, не смотря на эту опасность, регрессионную модель используют
таким образом. Поэтому в таком случае нужно относится к такой
аппроксимации очень и очень осторожно.
Регрессия применяется только к одиночным наборам данных. На
рис.25а мы видим два набора данных и через эти два набора проведена
регрессионная прямая. Но на самом деле для этого случая необходимо
использовать две разных прямые, такие, как на рис.25б.
Рис.25.
9.9. Заключение Регрессия и корреляции являются важными приемами для
предсказания и понимания взаимосвязей данных. Они имеют очень широкий
диапазон применения: экономика, прогнозирование продаж,
бюджетирование, планирование кадров, корпоративное планирование и
многое другое. Мы рассмотрели только простую линейную регрессию,
существует также ряд других, более сложных ее разновидностей. В нашем
курсе мы оставляем рассмотрение разновидностей за бортом, но напомню,
что все статистические пакеты в состояние выполнять весьма сложный
регрессионный анализ, в том числе как сложный линейный (там больше
коэффициентов), так и нелинейный (так переменные возводятся в квадрат
или большую степень).
195

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
196
Часть V. Прогнозирование конъюнктуры
Тема 10. Временные ряды
10.1. Введение
Метод временных рядов – это такой метод прогнозирования, который
позволяет предсказать будущие значения переменной исключительно из ее
значений за прошлые периоды времени. Это достигается путем
идентификации закономерностей в прошлых данных и переноса этих
закономерностей в будущее. Методов таких множество и они различаются по
типам рядов, к которым эти методы можно применять. Существуют
следующие виды рядов:
• Стационарные
• Ряды с трендом (тенденцией)
• Ряды с трендом и сезонностью
• Ряды с трендом, сезонностью и циклами
В сегодняшнем занятии мы рассмотрим технические приемы, при
помощи которых мы можем такие ряды обрабатывать.
10.2. Область применения метода временных рядов
Методы временных рядов используются часто в следующих ситуациях:
• В стабильных условиях. Если нет никаких изменяющихся обстоятельств,
то вполне можно заключить, что причина, изменяющая переменную в
прошлом, останется и в будущем. И будет изменять переменную точно
таким же образом. В таком случае метод временных рядов позволяет
делать очень неплохие прогнозы.
• Для краткосрочных прогнозов. Если не прошло достаточно большое
время для серьезных изменений в условиях, то методы временных рядов
также вполне применимы. В коротких промежутках времени временные
ряды в будущем ведут себя так же, как и в прошлом.
196

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
197
• Для подготовки основы будущего прогноза. Основной прогноз
показывает, что было бы, если бы будущее оставалось таким же, как и
прошлое. Даже если условия изменяются, методы временных рядов
позволяют создать какой-то начальный прогноз, на основе которого
можно строить предположения об различных изменяющихся условиях.
• Для фильтрации, анализа данных. Методы временных рядов помогают
найти закономерности в значениях переменной за прошлые периоды
времени. Эти закономерности могут быть использованы для лучшего
понимания произошедших изменений в переменной. Например, можно
выяснить, что относительно высокий уровень продаж за последний месяц
так или иначе связан с сезонностью или цикличностью чего-либо.
10.3. Стационарные ряды
Ряды данных являются стационарными, если данные в них меняются
вокруг какого-то постоянного уровня, и не прослеживается какой-то общей
тенденции, из-за которой изменения данных в одном периоде будут сильно
отличаться от изменений данных в другом периоде времени. Или, другими
словами, стационарные ряды не имеют какой-либо тенденции изменения
переменной и постоянной дисперсии.
На самом деле, в долгосрочном периоде, не существует стационарных
рядов. Но в коротком промежутке времени они вполне имеют право на
жизнь. Например, еженедельные цены на акции какой-то стабильной
компании в течение пары месяцев могут быть стационарным рядом. Но тот
же показатель за 5 лет уже вряд ли будет являться таковым.
10.3.1. Скользящее среднее Исходные ряды заменяются сглаженными рядами, такие значения
получаются путем замены исходных значений на среднее из текущего
значения, и значений, находящихся рядом. Процесс усреднения предназначен
для сглаживания возможных случайных флуктуаций, выбросов во временных
рядах.
197

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
198
Если каждое значение рассчитывается из трех наблюдений, то говорят,
что это трехточечное скользящее среднее, если из пяти – пятиточечное
скользящее среднее. На рис.1 и рис.2 показан пример проведения
усреднения по трем точкам.
Рис.1.
Рис.2.
Прогнозом для будущего времени (в нашем случае для квартала) будет
число 18.7 для всех периодов времени. Для всех периодов времени потому,
что временной ряд является стационарным.
Для того чтобы были сглажены случайные и сезонные флуктуации,
необоримо производить сглаживание по достаточно большому количеству
точек. Например, чтобы удалить компонент сезонности в течение года,
необходимо произвести сглаживание по 12 месяцам. Или, другими словами,
рассчитать 12-точечное скользящее среднее. Каждый месяц будет включен
единожды и, поэтому, сезонные вариации будут усреднены.
Однако использование четного количества точек создает новую
проблему. Полученное сглаженное значение уже не будет относиться к
какому-то конкретному интервалу времени. Оно скорее будет
соответствовать половине пути между двумя интервалами времени.
198

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
199
Например, 3-точечное скользящее среднее для Января, Февраля и Марта –
это сглаженное значения для Февраля.
А вот 4-точечное скользящее среднее для Января, Февраля, Марта и
Апреля – это сглаженное значение между Февралем и Мартом.
В принципе, нам это не особенно важно, когда мы имеем дело со
стационарными рядами данных, но об этом не стоит забывать, когда
временные ряды не стационарны. Мы вернемся к этой проблеме позднее.
Обычно количество точек, включенных в скользящее среднее, делают
равным сезонности данных. При отсутствии сезонности, среднее значение
должно включать достаточное количество точек для того, чтобы можно было
сгладить все случайности и флуктуации в данных, но не должно быть таким
большим, чтобы сглаживание привело в значительным изменениям в данных.
На практике обычно применяют 3-х и 5-точечное скользящее среднее.
Даже в случае нестационарных рядов такой метод, как скользящее
среднее, находит свое применение. Его применяют для сглаживания
случайных выбросов. Это позволяет сделать результирующие временные
ряды более четкими, гладкими.
10.3.2. Экспоненциальное сглаживание В случае скользящего среднего, каждое значение в среднем получает
одинаковый вес. В 3-точечном скользящем среднем каждое значение
получает вес 1/3. Экспоненциальное сглаживание – это путь расчета
среднего, при котором более поздним переменным даются большие веса.
Сглаживание происходит вот по такой формуле (см.рис.3):
)()()1(
значениеоенесглаженнПоследнеезначениесглаженноеПредыдущеезначениесглаженноеНовое
⋅+⋅−=
αα
или иначе
ttt xSS ⋅+⋅−= − αα 1)1( .
Рис.3.
где α может принимать значения от 0 до 1.
199

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
200
Значение α (альфа) выбирается человеком интуитивно. Чем больше
значение α, тем больший вес будет дан последним значениям.
Есть некоторые методики, которые позволяют выяснить, какое же
значение α лучше использовать. На практике α принимают равной от 0,1 до
0,4.
ПРИМЕР Данные, рассмотренные нами на рис.1 и рис.2 были экспоненциально
сглажены и помещены в таблицу на рис.4 (использовался коэффициент
сглаживания α=0.2).
Рис.4.
Так как формула экспоненциального сглаживания требует
предыдущего сглаженного значения, примем за первое сглаженное значение
принимают первое неслаженное. Это вполне допустимо.
На рис.5 показано, как экспоненциальное сглаживание работает для
сглаживания случайных флуктуаций. Так же, как и для скользящего
среднего, для стационарного ряда как прогноз берется самое последнее
сглаженное значение, в нашем случае – 17,84.
Рис.5.
200

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
201
10.4. Ряды с трендом
Использование метода скользящего среднего или экспоненциального
сглаживания может обнаружить существование тренда (направления
развития) в ряду, или даже этот тренд будет виден безо всякого сглаживания.
Давайте рассмотрим несколько дополнительных методов или понятий, перед
тем, как погрузиться в изучение самих рядов с трендами.
Существует несколько вариантов расчета скользящего среднего и
экспоненциального сглаживания, которые могут использоваться в рядах с
трендами. Один из методов экспоненциального сглаживания, метод Холта,
будет рассмотрен ниже.
10.4.1. Метод Холта Оставим, как обычно, математику для математиков и сразу перейдем к
формулам, предложенным этим исследователем. Выглядят она так:
ttmt
tttt
tttt
bmSFSSbb
xbSS
⋅+=−⋅+⋅−=++⋅−=
+
−−
−−
)()1()()1(
11
11
γγαα
Рис.6.
где: xt – исходное значение в момент времени t
St – сглаженное значение в момент времени t
α, γ – сглаживающие коэффициенты (от 0 до 1)
bt – сглаженный тренд в момент времени t
Ft+m – прогноз на m периодов вперед.
Процедура расчета начинается с того, что нам уже изначально нужно
сглаженное значение и значение тренда. Сглаженные значения для 1 и 2-го
периодов времени принимаются равными исходным значениям. Значения
тренда для 1-го периода времени найти невозможно. Для 2-го момента
времени оно равно разнице между вторым и первым исходными значениями.
На рис.7 продемонстрировано использование метода Холта.
201

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
202
Рис.7.
10.5. Ряды с трендом и сезонностью
Сезонность определяется как некий регулярный характер изменения
переменной в большую и меньшую сторону, повторяющийся с интервалом
менее года (раз в месяц, раз в квартал и т. п.). Существует несколько методик
работы с такими рядами. Мы рассмотри лишь одну из них. Она носит
название метод Холта-Винтерса.
Как и все прочие методики работы с рядами, она технически сложна, и
мы не будем вдаваться в детали. Мы лишь рассмотрим принципы, лежащие в
ее основе. По сути, метод Холта-Винтерса это расширение метода Холта.
Как вы помните, метод Холта основывается на двух сглаживающих
формулах. Первая относится к самому ряду (и имеет константу α в своем
составе), вторая относится к тренду (и имеет константу γ). В методе Холта-
Винтерса введено третье уравнение (уравнение сезонности) и в нем введена
новая сглаживающая константа β.
Наблюдаемая сезонность в рядах (месяца, кварталы и т. п. в
зависимости от сути данных) всегда расположена выше или ниже
сглаженного значения. Например, продажи охладительных напитков
наверняка будут выше в летние месяцы и ниже в зимние месяцы. И так из
года в год.
Сезонность измеряется как отношение между исходными и
сглаженными данными:
202

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
203
Сезонность = Исходные данные / Сглаженные данные.
Так же, как и тренд в методе Холта сглаживался константой γ, так и
сезонность сглаживается в методе Холта-Винтерса константой β. Итоговые
уравнения для расчета прогнозируемого значения не здесь приводятся из-за
их сложности. Обычно на практике прогнозы по этому методы выполняются
при помощи статистических пакетов программ на персональном компьютере.
Сглаживающая константа для сезонности (β) выбирается согласно тем же
правилам, что и α и γ.
10.6. Ряды с трендом, сезонностью и циклами
Цикл определяется как некий регулярный характер изменения
переменной в большую и меньшую сторону, повторяющийся с интервалом
длиной более года (в отличие от сезонности, где повторения происходят в
течение одного года). Один из наиболее известных методов, который
используется для таких рядов – это метод декомпозиции.
10.6.1. Метод декомпозиции Метод декомпозиции предполагает, что временной ряд может быть
разложен на четыре отдельных элемента:
• Тренд
• Цикл
• Сезонность
• Случайность
Все эти элементы считаются независимыми друг от друга.
10.6.1.1. Тренд
Тренд изолируется методом регрессионного анализа между временем и
данными (см.рис.8).
203

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
204
ttt ubax ++=
Рис.8.
Другими словами, наблюдения (xt) регрессируют относительно
времени (t), где время принимает значения 1 (для первого периода), 2 (для
второго периода), 3, 4, 5 и. т. д.
Регрессионное уравнение будет выглядеть примерно так: ttt ubax ++= ,
где xt – исходные данные, a+bt – элемент тренда, ut – остатки, включающие в
себя сезонность, цикличность и случайность.
10.6.1.2. Цикл
Следующим шагом будет изолирование цикла в данных. Используя
подходящее скользящее усреднение (12 для года, 6 для полугодия и т. д.)
случайная и сезонная составляющая будут исключены. Останется только
тренд и цикл. И если St это скользящее среднее, то отношение между St и
трендом (a+bt) и будет циклом.
Если отношение St/a+bt приблизительно одинаково для всех периодов
времени, то тогда цикла в данном ряду нет. Если же отношение это меняется
с течением времени, то его дополнительно анализирует с целью выяснения
природы цикла. Например, если это отношение для какого-то конкретного
случая нанести на график, то мы можем получить такой график, как на рис.9.
Рис.9.
204

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
205
В данном случае четко прослеживается цикл длиной 12 кварталов или 3
года. Как видно, отношение вновь становится равной величиной ровно через
эти 12 кварталов и потом картина повторяется.
Размер этого циклического эффекта рассчитывается путем вычисления
среднего отношения для каждой точки в цикле. Например, циклический
эффект можно рассчитать по формуле на рис.10.
,...29,17,5
,...29
,17
,5
555
=+++
=
tдляba
Sba
Sba
SотСреднееэффектйЦиклически
Рис.10.
10.6.1.3. Сезонность
Сезонность изолируется примерно таким же методом, как и
цикличность. Для скользящего среднего St включает в себя тренд и
цикличность; реальные же значения ряда включают в себя тренд,
цикличность, сезонность и случайный эффект. Отношение
t
t
Sxили
среднееСкользящеезначенияРеальные
Рис.11.
должно соответственно содержать лишь сезонность и случайный эффект.
Предположим, что у нас имеются данные по кварталам, тогда сезонность для,
скажем, первого квартала будет рассчитана путем усреднения отношений
,...,,19
9
5
5
1
1
Sx
Sx
SxотСреднеекварталадляСезонность =
Рис.12.
Сезонность для остальных трех кварталов рассчитывается
аналогичным образом. Усреднение помогает исключить случайный эффект,
который содержится в отношениях.
205
Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
206
10.6.1.4. В итоге
Делая прогноз, все три изолированных элемента перемножаются между
собой. Предположим, что нам необходимо сделать прогноз на будущий
квартал (t=50). Рассчитаем мы его так: СезонностьЦиклТрендПрогноз ××=
Рис.13.
Если наши данные поквартальны, цикл длинной 12 кварталов, t=50 и
это второй период цикла и второй период сезонности. Поэтому:
кварталадляэффектСезонныйциклапериодадляэффектйЦиклическиbaПрогноз
22)50( ××+=
Рис.14.
ПРИМЕР Данные из таблицы на рис.15 относятся к квартальным поставкам
некоего продукта со склада. Предложите Ваш прогноз для каждого квартала
1999 г.
Рис.15.
Используем метод декомпозиции. Необходимые расчеты и справочные
данные даны на рис.16.
206

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
207
Рис.16.
1. Рассчитаем тренд. Регрессионный анализ проведем по переменной «y»
(поставки) и переменной «x» (время в кварталах). Получим такую таблицу и
такое уравнение регрессии:
ВремяПоставки ××= 838.0851.2
Рис.17.
2. Рассчитаем цикличность. Как Вы помните, цикличность рассчитывается
как отношение между скользящим средним и трендом. Скользящее среднее
должно быть у нас 4-точечным для того, чтобы включить все 4 квартала и
207
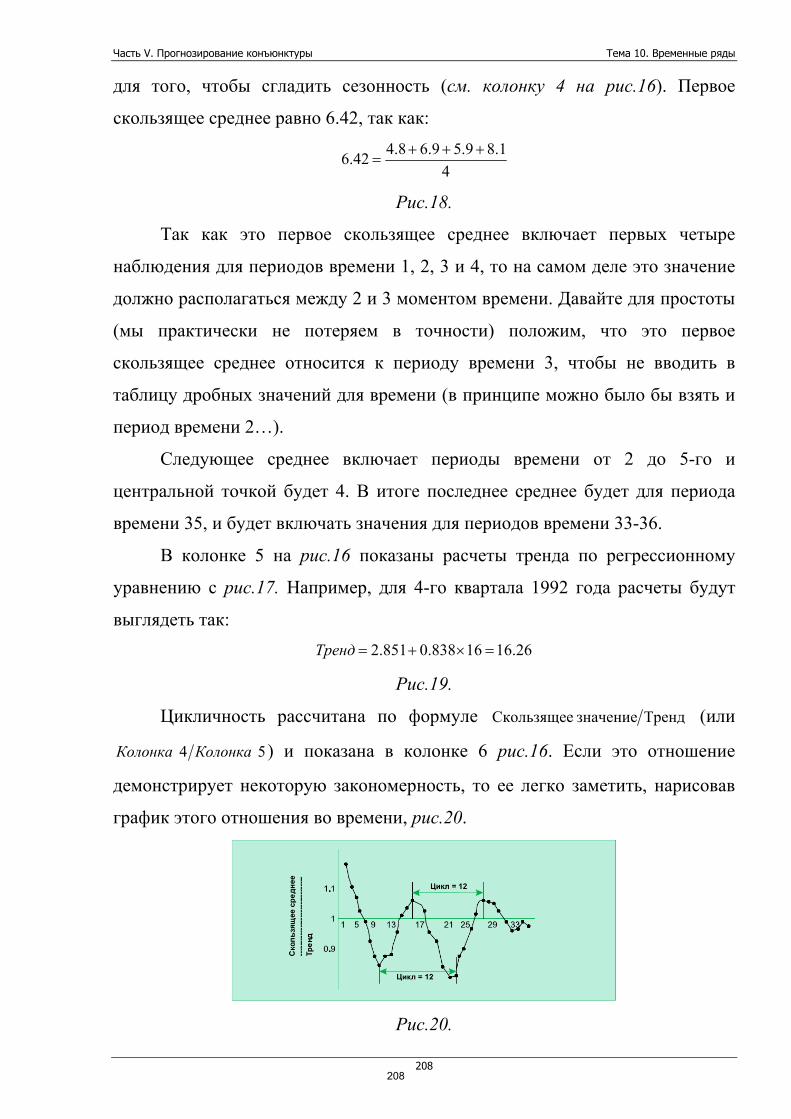
Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
208
для того, чтобы сгладить сезонность (см. колонку 4 на рис.16). Первое
скользящее среднее равно 6.42, так как:
41.89.59.68.442.6 +++
=
Рис.18.
Так как это первое скользящее среднее включает первых четыре
наблюдения для периодов времени 1, 2, 3 и 4, то на самом деле это значение
должно располагаться между 2 и 3 моментом времени. Давайте для простоты
(мы практически не потеряем в точности) положим, что это первое
скользящее среднее относится к периоду времени 3, чтобы не вводить в
таблицу дробных значений для времени (в принципе можно было бы взять и
период времени 2…).
Следующее среднее включает периоды времени от 2 до 5-го и
центральной точкой будет 4. В итоге последнее среднее будет для периода
времени 35, и будет включать значения для периодов времени 33-36.
В колонке 5 на рис.16 показаны расчеты тренда по регрессионному
уравнению с рис.17. Например, для 4-го квартала 1992 года расчеты будут
выглядеть так: 26.1616838.0851.2 =×+=Тренд
Рис.19.
Цикличность рассчитана по формуле Трендзначение Скользящее (или
54 КолонкаКолонка ) и показана в колонке 6 рис.16. Если это отношение
демонстрирует некоторую закономерность, то ее легко заметить, нарисовав
график этого отношения во времени, рис.20.
Рис.20.
208

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
209
По графике четко видно, что имеется цикл длинной в 12 кварталов. Для
каждого 12 периодов внутри одного цикла этот эффект может быть
подсчитан путем усреднения через все такие периоды.
Эффект цикличности для всех 12 периодов рассчитан из данных
колонки 6 и показан на рис.21.
Рис.21.
3. Расчет сезонного эффекта. Напомню, что эффект сезонности – это
отношение исходных данных к скользящему среднему, усредненное для
каждого квартала. Эти отношения рассчитаны и занесены в таблицу в
колонку 7 (колонка 3 / колонку 4). Например, индекс сезонности для первого
квартала каждого года будет рассчитан так (рис.22):
82.08
80.081.085.080.087.078.077.088.0=
+++++++
Рис.22.
На рис.23 показаны рассчитанные для всех четырех кварталов индексы
сезонности.
Рис.23.
209

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
210
К сожалению, имеется одна проблема с этими полученными сезонными
индексами. Среднее значение сезонного индекса не равно 1 (равно 1.025).
Это и ошибки расчета, и прочие наши допущения. Приведем индексы в такой
вид, чтобы среднее равнялось ровно 1. Для этого поделим все значения на
1.025. В итоге таблица сезонных индексов предстанет в таком виде, как это
показано на рис.24.
Рис.24.
Теперь среднее значение сезонного индекса равно ровно 1, то есть
нейтрально. И это правильно.
4. Сделаем прогноз. Исходный временной ряд был «декомпозирован» на
тренд, цикл и сезонность. Для того, чтобы произвести прогноз на 1999 год,
соберем вместе все эти три элемента. Прогноз показан на рис.25.
Рис.25.
А) Линия тренда – это ВремяПоставки ××= 838.0851.2 . Подставляя вместо
«Времени» числа 41-44 (1-4 квартал 1999 года) получим значения тренда для
1999 года.
Б) Каждый цикл, как выяснилось, продолжается 12 периодов. Один из циклов
начинается с 1 квартала 1989 года циклы таковы – 1989-1991, 1992-1994,
1995-1997. Следовательно, четыре квартала 1999 года – это периоды времени
цикла с 5 по 8. Циклические эффекты берем из рис.21.
В) Сезонные эффекты для каждого квартала берем из рис.24.
Г) Тогда наш прогноз будет таков 26.3180.005.121.37 =××=Прогноз
Рис.26.
210

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
211
и так для каждого квартала.
10.7. Обзор различных методов временных рядов
На рис.27 резюмирована информация по различным методам обработки
временных рядов согласно их типам.
Рис.27.
Конечно, для каждого из вида ряда существует еще множество других
методов, которые мы не изучаем в курсе. По таблице видно, что мы уже
умеем иметь дело со всеми типами рядов, кроме одного. И нам еще не знаком
метод Бокса-Дженкинса. Кстати считается, что этот метод является одним из
самых точных. Давайте рассмотрим его.
10.7.1. Метод Бокса-Дженкинса Метод Бокса-Дженкинса позволяет делать прогнозы путем
компенсирования ошибок. Это делается включением ошибок
прогнозирования (или прошлых остатков) в уравнение прогноза, которое
таким образом изменяется в ответ на предыдущие ошибки.
Уравнения прогноза, которые объединяют прошлые значения
переменной и прошлые значения остатков, известны как авторегрессивные
уравнения (ARMA – autoregressive moving average).
Метод Бокса-Дженкинса лучше описать как некий пошаговый процесс:
Стадия 1. «Отбеливание». Под этим термином Бокс и Дженкинс понимают
удаление тренда из временного ряда. Позднее, когда будет проводиться
прогноз, тренд, несомненно, будет использован.
211

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
212
Стадия 2. Идентификация. Выбор таких прошлых значений и остатков,
которые, как Вам кажется, наиболее сильно влияют на будущие значения.
Это делается путем анализа автокорреляционных коэффициентов.
Понятие автокорреляционных коэффициентов и метод их анализа выходит за
рамки курса. Но результатом этого шага может явиться, например такая
формула:
месяцаэтогоостаткамисмесяцапрошлогоиэтогозначенийКомбинациямесяцследующийнаПрогноз =
Рис.28.
Стадия 3. Оценивание. Определение коэффициентов для каждого из
прошлых значений, выбранных в предыдущем шаге. Для этого имеется
специальный компьютерный алгоритм. В результате формула на следующий
месяц приобретет уже такой вид:
месяцаэтогоОстатокмесяцапрошлогоЗначениемесяцатекущегоЗначениемесяцследующийнаПрогноз
×−×+×=
24.009.093.0
Рис.29.
Стадия 4. Контроль. Если в итоге мы получили модель, и остатки
распределены случайным образом – то мы добились цели. Если остатки не
случайны, то необходимо учитывать другие прошлые значения или остатки.
Следовательно, шаги 2, 3, 4 должны быть повторены (см.рис.30).
Рис.30.
Стадия 5. Прогноз. Как только остатки становятся случайными, мы можем
использовать полученное уравнение для прогнозирования.
212

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
213
Метод Бокса-Дженкинса является достаточно сложным методом
прогнозирования, которые вовлекает использование компьютера,
квалифицированная рабочая сила и значительное временя. Он требует также
большого и специфического опыта от человека, проводящего анализ. И этот
метод не полностью по сей день автоматизирован. С другой стороны, этот
метод является одним из самых точных на сегодняшний день. Горизонт
прогнозирования по этому методу находится в пределах от 3 до 6 месяцев.
10.8. Заключение
Несмотря на то, что практика показала эффективность методов
временных рядов, тем не менее, их полезность до сих пор недооценивается.
Во многом это связано с тем, что считается, раз будущие значения
переменной оцениваются исключительно по прошлым значениям, то это
оценивание не учитывает различных новых обстоятельств, изменений в
конъюнктуре рынка и т. п.
Тем не менее, методы временных рядов весьма и весьма точны при
проведение краткосрочных прогнозов. Более того, они имеют одно большое
преимущество перед другими методами. Так как они имеют дело лишь с
прошлыми значениями переменной, то значительная часть процесса может
быть автоматизирована. Представьте себе большой склад, на котором
хранится тысячи наименований продукции. Многие из которых стоят совсем
немного. И менеджеру просто не хватит времени уделять внимание каждому
товару в отдельности, это просто будет невыгодно с экономической точки
зрения. В то же время менеджеру не нужно строить какой-то долгосрочный
прогноз. А вот краткосрочный будет в самый раз.
Чтобы предсказать, что и когда нужно еще завезти на склад товар. Причем
это предсказание можно сделать автоматически при помощи компьютера, и
без участия человека.
213

Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
214
Можно так спроектировать программу, что она раз в неделю будет
напоминать менеджеру чего и сколько нужно закупить исходя из остатков на
складе.
Несомненно, что изначально необходимо будет произвести некоторые
изыскания, сформировать формулы и получить значения констант
сглаживания, проверить точность и т. п. Но как только такое исследование
будет проведено, на этом практически закончатся издержки. Дальше все
будет идти само собой. Ну, может быть раз в год нужно будет
подкорректировать коэффициенты. Только и всего. Поэтому, наверное,
самый главный наш вывод – постараться не недооценивать метод временных
рядов. Такие методы имеют несомненное преимущество в цене, и, для
краткосрочных прогнозов, в точности получаемых результатов.
214
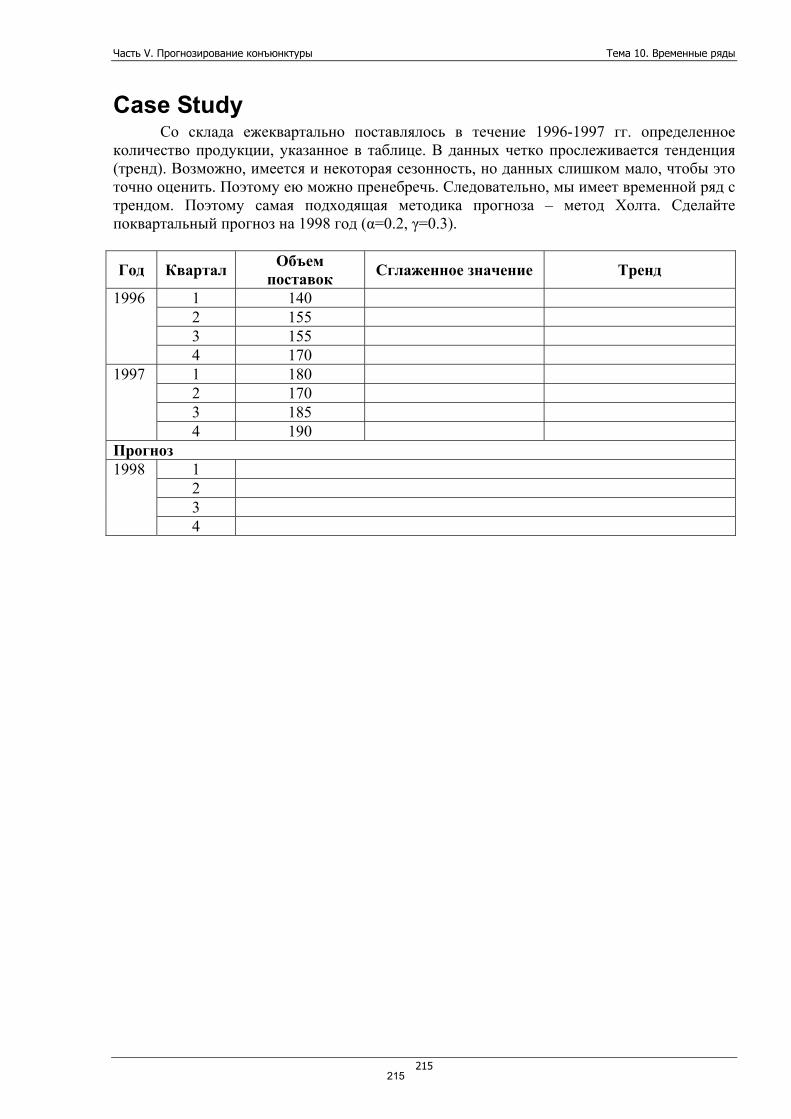
Часть V. Прогнозирование конъюнктуры Тема 10. Временные ряды
215
Case Study Со склада ежеквартально поставлялось в течение 1996-1997 гг. определенное
количество продукции, указанное в таблице. В данных четко прослеживается тенденция (тренд). Возможно, имеется и некоторая сезонность, но данных слишком мало, чтобы это точно оценить. Поэтому ею можно пренебречь. Следовательно, мы имеет временной ряд с трендом. Поэтому самая подходящая методика прогноза – метод Холта. Сделайте поквартальный прогноз на 1998 год (α=0.2, γ=0.3).
Год Квартал Объем поставок Сглаженное значение Тренд
1996 1 140 2 155 3 155 4 170
1997 1 180 2 170 3 185 4 190
Прогноз 1998 1
2 3 4
215

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
Вопросы 1.1. Одной из причин, почему вероятность так важна в статистике, является то, что если изучаемые данные представляют собой выборку, то никакое заключение об этих данных не может быть вынесено со 100%-ной уверенностью. Так ли это? 1.2. Из колоды карт случайным образом достали туз. Карту в колоду не вернули. Какова вероятность того, что следующая случайно взятая из колоды карта тоже окажется тузом? (a) 1/4 (b) 1/13 (c) 3/52 (d) 1/17 (e) 1/3 1.3. Какое из утверждений является истинным? (a) Вероятность события – это число от 0 до 1. (b) Так как ничто не бесспорно, то нет такого события, вероятность которого была бы равна 1. (c) Классическая школа статистики считает, что субъективный метод измерения вероятности не может быть использован. (d) Байесовская школа статистики считает, что субъективный метод – это единственно верный метод измерения вероятности. 1.4. Монету бросили восемь раз, и каждый раз выпадал «орел». Если бросить монету девятый раз, то какова вероятность выпадения «решки»? (a) Меньше чем ½ (b) ½ (c) Больше чем ½ (d) 1 Вопросы 1.5-1.7 основаны на следующей информации: Данные о ежедневных продажах ж/д билетов (в тыс. $) за последний квартал (= 13 недель = 78 дней) отображены на диаграмме.
1.5. Сколько дней продажи были не менее $50000? (a) 17 (b) 55 (c) 23 (d) 48 1.6. Какова вероятность того, что в какой-то день продажи будут $60000 и более? (a) 1/13 (b) 23/78 (c) 72/78 (d) 0
216

Часть I. Введение в статистику Тема 1. Введение в статистику. Примеры использования статистики
1.7. Какой уровень продаж превышается в 90% дней? (a) $20 000 (b) $30 000 (c) $40 000 (d) $50 000 (e) $60 000 1.8. Какие из следующих утверждений о нормальном распределении верны? (a) Нормальное распределение – это другое название стандартного распределения. (b) Нормальное распределение – это один из случаев стандартного распределения. (c) Нормальное распределение – это дискретное распределение. (d) Нормальное распределение может быть как симметричным, так и не симметричным (в зависимости от параметров). 1.9. Нормальное распределение имеет следующие параметры: среднее – 60, стандартное отклонение – 10. Каков процент значений лежит в диапазоне 60–70? (a) 68% (b) 50% (c) 95% (d) 34% (e) 84% 1.10. Пост ГИБДД в течение недели замерял скорости проезжающих автомобилей. В итоге получилось нормальное распределение со средним значением 82 км/ч и стандартным отклонением 11 км/ч. Какая скорость была превышена 97,5% автомобилей? (a) 49 (b) 60 (c) 71 (d) 104
Case Study 1.1: Продажа авиабилетов При планировании строительства новых билетных касс авиакомпания собрала
данные о времени ожидания клиентом около кассы своего билета (время обслуживания). Было зарегистрировано время ожидания для каждого из 100 клиентов. Эти данные и занесены в таблицу.
0.9 3.5 0.8 1.0 1.3 2.3 1.0 2.4 0.7 1.0 2.3 0.2 1.6 1.7 5.2 1.1 3.9 5.4 8.2 1.5 1.1 2.8 1.6 3.9 3.8 6.1 0.3 1.1 2.4 2.6 4.0 4.3 2.7 0.2 0.3 3.1 2.7 4.1 1.4 1.1 3.4 0.9 2.2 4.2 21.7 3.1 1.0 3.3 3.3 5.5 0.9 4.5 3.5 1.2 0.7 4.6 4.8 2.6 0.5 3.6 6.3 1.6 5.0 2.1 5.8 7.4 1.7 3.8 4.1 6.9 3.5 2.1 0.8 7.8 1.9 3.2 1.3 1.4 3.7 0.6 1.0 7.5 1.2 2.0 2.0 11.0 2.9 6.5 2.0 8.6 1.5 1.2 2.9 2.9 2.0 4.6 6.6 0.7 5.8 2.0
Классифицируйте данные по интервалам (1 интервал = 1 минута). Постройте частотную гистограмму. Какое максимальное время обслуживания будет превышено для 10% клиентов?
217
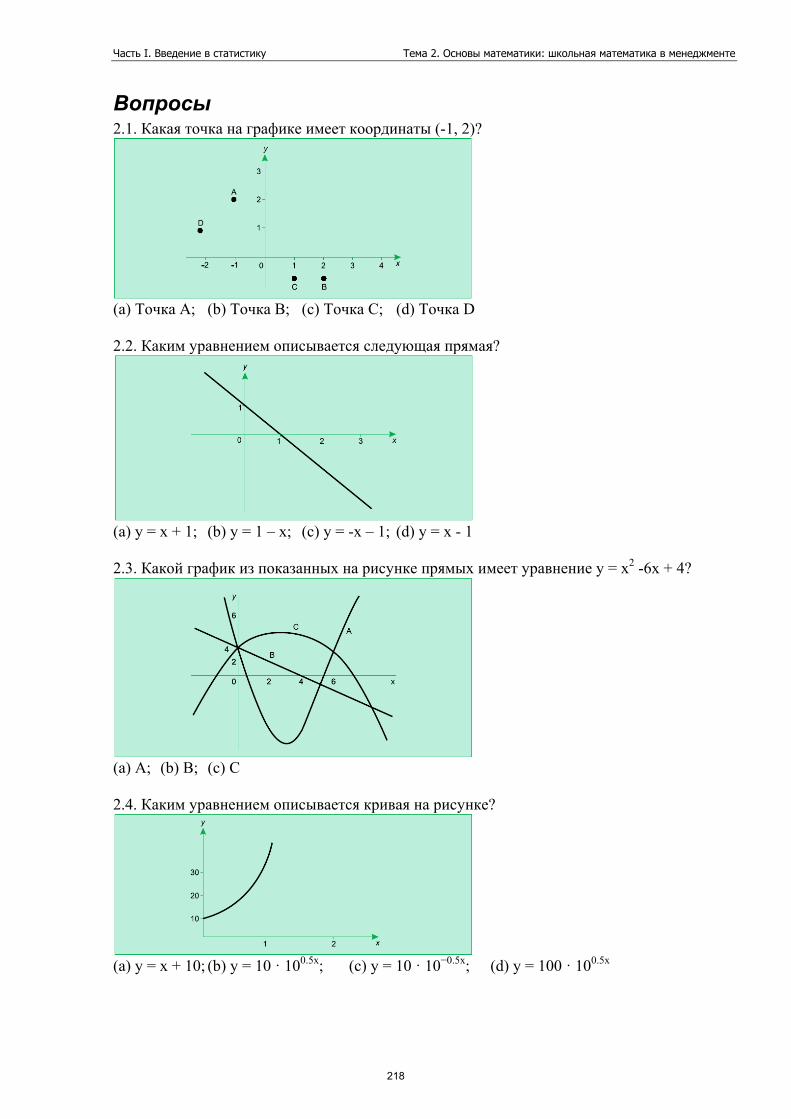
Часть I. Введение в статистику Тема 2. Основы математики: школьная математика в менеджменте
Вопросы 2.1. Какая точка на графике имеет координаты (-1, 2)?
(а) Точка A; (b) Точка B; (c) Точка C; (d) Точка D 2.2. Каким уравнением описывается следующая прямая?
(а) y = x + 1; (b) y = 1 – x; (c) y = -x – 1; (d) y = x - 1 2.3. Какой график из показанных на рисунке прямых имеет уравнение y = x2 -6x + 4?
(а) A; (b) B; (c) C 2.4. Каким уравнением описывается кривая на рисунке?
(a) y = x + 10; (b) y = 10 · 100.5x; (c) y = 10 · 10−0.5x; (d) y = 100 · 100.5x
218

2
2.5. Чему равняется у для 6x + 4 = 2y − 4? (a) y = 3x (b) x = (y − 4) / 3 (c) y = 3x + 4 (d) y = 3x + 8 2.6. Чему равняется y для (2y + 3) / 2 = (y2 − y + 5) / y? (a) y2 = 10 − 5y (b) y = 10 (c) y2 + 2y − 10 = 0 (d) y = 2 2.7. Каково уравнение прямой с точкой пересечения равной 3 и проходящей через точку (3, 9)? (a) y = 3x + 2 (b) y = 6x + 3 (c) y = 4x + 3 (d) y = 2x + 3 2.8. Каково уравнение прямой, проходящей через точки (-1, 6) и (3, -2)? (a) y = 2x + 8 (b) y = 4 − 2x (c) y = −½x + 5½ (d) y = 2x − 8
2.9. Решить систему уравнений 4y + x = 5 и 2y − x = 7. (a) y = −1, x = 9 (b) y = 1, x = 1 (c) y = −1, x = −9 (d) y = 2, x = −3 2.10. Решить систему уравнений 2y + 7x = 3 и 3y − 2x = 17. (a) y = 113/17, x = 25/17 (b) y = 5, x = −1 (c) y = −2, x = 1 (d) y = −1, x = 5 2.11. Чему равно (16)-3/2? (a) −64 (b) 1/64 (c) 1/24 (d) − 1/64 2.12. Чему равно log28? (a) 0.9031 (b) 1/3 (c) 3 (d) 256
Case Study 2.1: CNX Armaments Co. Оружейная фирма CNX Armaments Co. разработала две новых системы
вооружения. В таблице приведены данные о себестоимости и ценах на эти системы. Постоянные
издержки Переменные издержки Цена
Система 1 100 4 5 Система 2 1200 4 8
Вычислить точку самоокупаемости производства каждой системы, т. е. сколько нужно произвести экземпляров каждой системы чтобы затраты на производство сравнялись с прибылью.
Case Study 2.2: Собачья еда Собачья еда фирмы Bonzo содержит 30% мяса и 70% злаков. Собачья еда фирмы
Woof Corporation содержит 40% мяса и 60% злаков. Управляющий собачьим питомником знает, что собака должна получать в течение для 6 унций мяса и 10 унций злаков (не больше, не меньше). При помощи двух уравнений выразите количество этих двух видов еды, которое каждая собака должна съедать в течение дня. В какой пропорции смешать корма этих двух производителей, чтобы собака была накормлена правильно?
Case Study 2.3: Сотовые телефоны Продажи мобильных телефонов растут экспоненциально (т. е. по закону y = kecx).
Шесть лет назад было продано 10000 тыс. телефонов. В прошлом году продано 40000 тыс. Каковы ожидаемые продажи в этом году? (для справки: loge4=1.386, e1.662=5.27).
219

Часть II. Обработка числовой информации Тема 3. Представление данных
Вопросы (возможно несколько ответов на один вопрос) 3.1. Каким принципам необходимо следовать при работе с данными? (a) Требования будущего пользователя этих данных первостепенны. (b) Тенденции изменения данных должны быть явно видны. (c) Данные должны быть представлены в формате «два знака после запятой». (d) Данные необходимо сначала проанализировать, а потом уже передавать заинтересованному лицу. 3.2. Количество знаков после запятой свидетельствует о точности данных. Так ли это? 3.3. Необходимо задавать такую точность данных, которая не повиляет на принимаемое на основе этих данных решение. Так ли это? 3.4. Если округлить число 3732.578 до двух значимых цифр, то получится: (a) 3732.58; (b) 3700; (c) 3730; (d) 3732 3.5. Если округлить до двух значимых цифр следующий набор данных – 1732, 1256.3, 988.42, 38.1, то получится: (a) 1730, 1260, 988, 38; (b) 1730, 1260, 990, 38; (c) 1700, 1300, 990, 38 3.6. По каким причинам лучше сравнивать данные в столбцах, чем в строках? (a) Сразу видна разница между 2-х и 3-значными числами. (b) Вычитания в уме одного числа из другого происходит быстрее. (c) Цифры расположены ближе, и поэтому их проще анализировать. 3.7. Если строки в таблице (каждая строка – это данные о филиале большой компании) необходимо отсортировать, то что следует выбрать критерием сортировки? (a) Числа в самой левой колонке. (b) Денежный оборот филиала. (c) Количество рабочей силы в филиалах. 3.8. За что можно покритиковать эту таблицу?
Регион Продажи ($000) Восточный 1230 Северный 1960 Юго-западный 1340 Южный 1030 Центральный 1220
(a) Данные не округлены до двух значимых цифр. (b) Регионы не отсортированы по размеру. (c) Большое расстояние между колонками. (d) Нет вертикальной линии между столбцом РЕГИОН и ПРОДАЖАМИ. 3.9. К отчетным бухгалтерским документам можно применять лишь некоторые из правил представления данных. Потому что: (a) Округлять нельзя, так как проверяющий может захотеть проверить точность данных. (b) Округление вообще запрещено. (c) Данные в бухгалтерских документах нельзя сортировать, так как имеется строго определенная форма, от которой нельзя отступать.
220
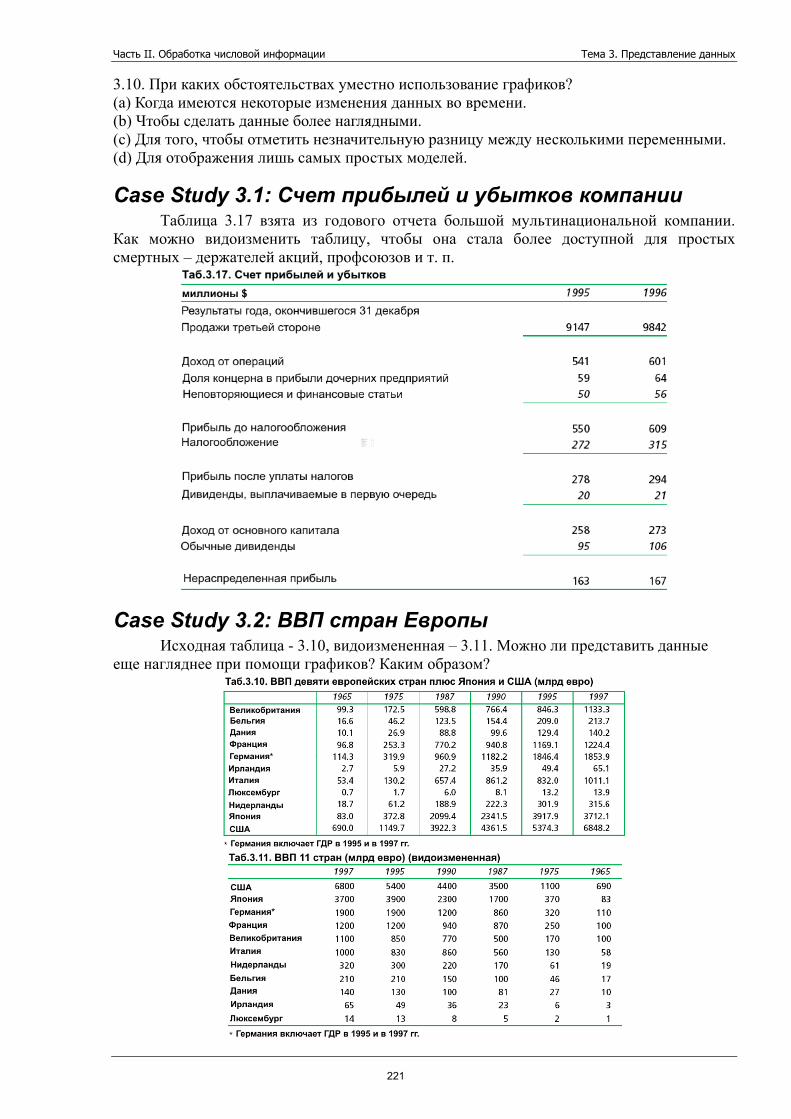
Часть II. Обработка числовой информации Тема 3. Представление данных
3.10. При каких обстоятельствах уместно использование графиков? (a) Когда имеются некоторые изменения данных во времени. (b) Чтобы сделать данные более наглядными. (c) Для того, чтобы отметить незначительную разницу между несколькими переменными. (d) Для отображения лишь самых простых моделей.
Case Study 3.1: Счет прибылей и убытков компании Таблица 3.17 взята из годового отчета большой мультинациональной компании.
Как можно видоизменить таблицу, чтобы она стала более доступной для простых смертных – держателей акций, профсоюзов и т. п.
Case Study 3.2: ВВП стран Европы Исходная таблица - 3.10, видоизмененная – 3.11. Можно ли представить данные
еще нагляднее при помощи графиков? Каким образом?
221

Часть II. Обработка числовой информации Тема 4. Анализ данных
Вопросы (возможно несколько ответов на один вопрос) 4.1. Традиционные статистические методики вряд ли смогут помочь менеджеру в анализе данных. Так ли это? 4.2. Требования к умению обрабатывать и анализировать статистическую информацию с каждым годом возрастают, так как большая часть анализа данных производится на компьютерах, и результаты этого анализа зачастую выглядят все более сложно. Так ли это? 4.3. Первым шагом в анализе данных является сокращение количества самих данных. Это делается потому что: (a) Большинство наборов данных содержит в себе неточности. (b) Человек способен обработать лишь ограниченное количество данных в определенный отрезок времени. (c) Большая часть наборов данных содержит данные, важность которых второстепенна. 4.4. Если имеющийся набор данных (указанных с точностью до восьмого знака после запятой) округлить, то это округление никоим образом не повлияет на принятие решения? Так ли это? 4.5. Какое из утверждений является верным? Модель используется для подведения итогов таблицы потому что: (a) Исключения будут более заметны. (b) Проще сравнивать данные с другими наборами данных. (c) Модель будет более точна, чем исходные данные. 4.6. Какая из моделей лучше описывает указанные данные?
Год Продажи (мил. $) 1993 3.2 1994 4.0 1995 5.0 1996 6.2
(a) Ежегодный рост в 1 млн. $. (b) Ежегодный рост на 25%. (c) В 1996 продажи были наиболее удачными. (d) В среднем за эти годы продажи = 4.6 млн. $. 4.7. Компания имеет четыре отделения. Прибыль и капитал каждого подразделения указан в таблице. Какое подразделение является исключением? Прибыль Капитал Отделение 1 4.8 80.3 Отделение 2 7.2 191.4 Отделение 3 3.6 59.4 Отделение 4 14.5 242.0
(a) Отделение 1 (b) Отделение 2 (c) Отделение 3 (d) Отделение 4 4.8. Предполагалось, что количество произведенной продукции на новом заводе по производству кондитерских изделий будет расти на 5% ежемесячно в течение 36 месяцев. Тем не менее, в 11 месяцах из 36 эта модель не сработала. Были следующие исключения – 5
222

Часть II. Обработка числовой информации Тема 4. Анализ данных
месяцев производство стояло из-за различных забастовок; 3 декабря и 3 августа завод почти не работал из-за летних и зимних отпусков. Будем ли мы вправе сказать, что эта модель не подходит для данного случая (+5% ежемесячно), так как имеем 11 исключений (что слишком много) из 36 месяцев? 4.9. Для того чтобы завершить исследование потребления алкоголя в США, какой еще анализ бы был полезен и интересен? (a) Потребление чистого алкоголя по провинциям Франции. (b) Потребление вина по провинциям Франции. (c) Потребление вина по штатам США. (d) Потребление виски по штатам США. 4.10. При анализе данных предпочтительно использовать простые модели, чем сложные, так как сложные модели зачастую могут скрывать истинные закономерности изменения данных. Так ли это?
Case Study 4.1: Безопасность движения В феврале 1997 года были оглашены результаты исследований дорожной полиции: «Десять лет назад, в 1986 году было зарегистрировано 0.1 смертей на каждые 1 млн. км пробега автомобилей. В 1991 году на 12 млн. км приходилась одна жертва. В прошлом году погибло 6400 человек при общем пробеге автотранспорта в 92 000 млн. км». (a) Проанализируйте данные. (b) Было ли вождение в 1996 более безопасным, чем в 1986 году? (c) Каков прогноз смертей на 2000 год? (d) Чем вы руководствовались, делая прогноз на 2000 год?
Case Study 4.2: Расходование средств Таблица взята из годового отчета крупной Британской компании, в ней указаны расходы компании по географическим подразделениям, разбитые на категории. Например, для региона Wessex было потрачено всего $48 545 000, в том числе $573 000 на зарплату, $13 224 000 на сырье и т. д. Проанализируйте таблицу и укажите на регионы с ненормальными (весьма отличающимися от средних) расходами.
223

Часть II. Обработка числовой информации Тема 5. Сводные измерения
Вопросы 5.1. С какими из следующих утверждений о сводных измерениях Вы согласны? (a) Они более точны, чем исходные данные. (b) Легче иметь дело с информацией, представленной в виде сводных значений. (c) Они никогда не могут ввести в заблуждение об исходных данных. (d) Средние значения и показатели разброса охватывают все основные особенности данных. Вопросы 5.2-5.4 касаются следующего набора данных: 1, 5, 4, 2, 7, 1, 0, 8, 6, 6, 5, 2, 4, 5, 3, 5 5.2. Чему равно арифметическое среднее? (a) 4 (b) 5.5 (c) 4.25 (d) 4.5 (e) 5 5.3. Чему равна медиана? (a) 4 (b) 5.5 (c) 4.25 (d) 4.5 (e) 5 5.4. Чему равна мода? (a) 4 (b) 5.5 (c) 4.25 (d) 4.5 (e) 5 5.5 Среднее арифметическое значение… (a) Всегда «лучше», чем медиана или мода. (b) Чаще всего вводит в заблуждение. (c) Лучше, чем медиана или мода, за исключением случаев, когда они примерно равны. (d) Должно использоваться, если распределение данных U-образное. 5.6. Самолет должен облететь квадрат со стороной, равной 200 км. Из точки А до точки В самолет летел со скоростью 200 км/ч, из B в C со скоростью 300 км/ч, из C в D со скоростью 400 км/ч и из D в A со скоростью 600 км/ч. Какова средняя скорость всего полета из точки А до точки А?
(a) 325 км/ч (b) 320 км/ч (c) 375 км/ч (d) 350 км/ч
224

Часть II. Обработка числовой информации Тема 5. Сводные измерения
5.7. С какими утверждениями о показателях разброса Вы согласны? (a) Если используются средние значения, то обязательно использование и показателей разброса. (b) Показатели разброса – альтернатива средним значениям. (c) Можно ожидать, что значения показателя разброса будет невелико, если данные сгруппированы близко, и велико, когда данные сильно разбросаны. Вопросы 5.8-5.12 касаются следующего набора данных: 23, 27, 21, 25, 26, 22, 29, 24, 27, 26 5.8. Чему равен размах вариации? (a) 7 (b) 8 (c) 9 (d) 10 5.9. Чему равен интерквартильный размах вариации? (a) 2 (b) 4 (c) 8 (d) 5 5.10. Чему равно среднее линейное отклонение? (a) 3 (b) 2 (c) 1.8 (d) 2.2
5.11. Чему равна дисперсия? (a) 5.6 (b) 6.2 (c) 5.2 (d) 6.5 5.12. Чему равно среднее квадратическое отклонение? (a) 6.2 (b) 5.6 (c) 2.4 (d) 2.5
5.13. Какие из следующих утверждений истинны? (a) Так как нет какого-то «наилучшего» показателя разброса, то нет разницы какой именно использовать. (b) Интерквартильный размах вариации хорош тем, что на него не влияют экстремальные значения. (c) Дисперсия и среднее квадратическое отклонение измеряют разброс, но в квадратных единицах (например не в см, а в см2). (d) Среднее линейное отклонение предпочтительней, чем интерквартильный размах вариации, так как с математической точки зрение среднее линейное отклонение проще. 5.14. Какие из указанных ниже утверждений истинны, если в данных имеется какое-то резко выделяющееся из других значение (выброс)? (a) Выброс нужно либо оставить, либо исключить из набора. (b) Выброс нужно обязательно оставить, если когда подсчитывается среднее арифметическое. (c) Выброс, который явно не является частью закономерности в наборе данных обычно исключают из вычислений. 5.15. Имеется следующая информация о двух индексах жизни:
1993 1994 1995 1996 Стоимость жизни 100 109.7 118.3 128.6 Зарплата 100 111.2 123.1 133.5
225

Часть II. Обработка числовой информации Тема 5. Сводные измерения
Сравнивая 1995 и 1996 годы, рост стоимости жизни по сравнению с ростом зарплаты: (a) Значительно больше? (b) Немного больше? (c) Они равны? (d) Немного меньше? (e) Значительно меньше?
Case Study 5.1: Лампы дневного света Образцы ламп дневного света были получены от двух поставщиков. Лампы были проверены в лаборатории. Были получены следующие результаты о продолжительности работы этих ламп:
Продолжительность работы лампы (в часах) 700-899 900-1099 1100-1299 1300-1499 Всего Поставщик А 12 14 24 10 60 Поставщик В 4 34 19 3 60
(a) У какого поставщика лампы имеют большую продолжительность работы? (b) Качество ламп какого поставщика более стабильно? (c) Какого поставщика Вы бы выбрали?
Case Study 5.2: Отчет о командировке Отчет о шести командировках мистера Смита дан в таблице. Босс Смита считает, что расходы слишком велики, так как средние траты за командировку составили 35 долларов. Другой же сотрудник в среднем тратил около 20 долларов на командировку. Как можно предложить варианты оправданий перед боссом за 35 долларов? Командировка Дней Траты ($) Траты в день ($)
1 2 64 32 2 8 128 16 3 0.5 40 80 4 9 108 12 5 4 80 20 6 0.5 25 50
Всего 24 445 210
Case Study 5.3: Занятость рабочей силы Статистика занятости в четырех отделениях компании Икс такова:
Отделение компании А В C D Количество рабочей силы (в месяц) 10560 4891 220 428 Стандартное отклонение 606 302 18 32 Сравнить стабильность уровня занятости в разных подразделениях компании.
Case Study 5.4: Расстояния до работы Расстояние от дома до работы для жителей Лондона таково:
Расстояние от дома до работы (в км) 0 1 2 3 4-5 6-7 8-9 10-11 12-14 15-19 20-29 более 30 % жителей 3 7 9 10 16 12 11 8 8 4 6 6 Среднее расстояние от дома до работы составляет 10.5 км. Вычислить моду, медиану и два показателя разброса. Как бы вы вкратце могли резюмировать эти данные?
226

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
Вопросы 6.1. Какие утверждения верны? Необходимость в выборках возникает потому что: (a) Невозможно получить значения всей генеральной совокупности данных. (b) Выборки позволяют получить более точные результаты. (c) Выборки позволяют сэкономить время и деньги при обследовании всей генеральной совокупности данных. 6.2. Какие утверждения верны? Случайность в выборках используется во многих методах выборочного обследования для того, чтобы: (a) выборка стала более репрезентативной. (b) снизить стоимость получения выборки. (c) не приходилось оперировать с данными всей генеральной совокупности. 6.3. Британская фирма разделяет Великобританию на 9 регионов. Необоримо случайным образом выбрать три региона. Если использоваться предложенную таблицу случайных чисел, то какие регионы будут выбраны? (таблицу использовать слева сверху, по строкам).
Регионы: 1. North West England 2. Eastern England 3. Midlands 4. London 5. South East England 6. South West England 7. Wales 8. Scotland 9. Northern Ireland Итоговая выборка: (a) SE England, Scotland, SE England? (b) SE England, Scotland, London? (c) Scotland, SE England, NW England? (d) SE England, Wales, SW England? (e) NW England, N Ireland, NW England? 6.4. Преимуществом многоступенчатой выборки перед простой случайной является следующее: (a) Нужно собирать меньше данных. (b) Не нужно составлять список всей генеральной совокупности. (c) Можно сохранить деньги и время ограничив себя некоторыми областями генеральной совокупности. (d) Легче подсчитать точность результатов. 6.5. Какие утверждения о расслоенной выборке являются истинными? (a) Она обычно более репрезентативна, чем простая случайная выборка. (b) Она не может быть также групповой выборкой. (c) Она дороже, чем простая случайная выборка.
227

Часть II. Обработка числовой информации Тема 6. Методы выборочного обследования
6.6. Когда используются не вполне случайные выборки: (a) Когда невозможно использовать случайные. (b) Не вполне случайные выборки могут быть более репрезентативны за те же деньги, что и случайные (c) Так как имеется вероятность допустить ошибку (или быть необъективным) при построении случайной выборки. 6.7. Была взята выборка из 25 детей 10-летнего возраста и измерен их рост. Утверждается, что точность составила ±12 см. Какова будет точность, если размер выборки будет 400 детей? (a) ±3 см (b) ±0.75 см (c) ±48 см (d) ±4 см Case Study 6.1: Вопросник бизнес-школы
Французская бизнес-школа собирает информацию о карьерах своих выпускников. Они решили сделать выборку по своим выпускникам и послать им вопросник.
Выборка была построена следующим образом. Со случайного места в списке «Ассоциации выпускников» брали каждое 20-ое имя. С другой стороны из общего списка выпускников взяли каждое 20-ое имя (чей адрес был известен), исключая тех, кто числится в «Ассоциации выпускников».
Оба списка были в алфавитном порядке. В итоге было получено 1200 ответов на вопросник. Была ли эта выборка случайной?
228

Часть III. Статистические методы Тема 7. Распределения
Вопросы 7.1. Какой метод измерения вероятности используется для оценки вероятностей в наблю-даемых распределениях? (a) Априори (b) Относительных частот (c) Субъективный 7.2. Станок изготавливает металлические стержни номинальной длинной 100 см для же-лезнодорожных локомотивов. Была отобрана выборка из 1000 стержней, стержни были обмерены, их длины были сгруппированы по классам с шагом 0.1 см. Затем была по-строена частотная гистограмма. Из гистограммы были подсчитаны вероятности. Какого типа распределение было в итоге сформировано? (a) Наблюдаемое (b) Биноминальное (c) Нормальное Вопросы 7.4-7.6 касаются следующей ситуации: У врача имеется книга отметки посещений его кабинета 20-ю больными. Иногда больной может не придти, даже не предупредив врача. Из прошлого опыта врача была вычислена вероятность неявки больных на приём.
Р(0 неявок) 32% Р(1 неявка) 29% Р(2 неявки) 22% Р(3 неявки) 11% Р(4 неявки) 3% Р(5 неявок или более) 3%
Всего 100%
7.4. Какова вероятность того, что в какой-то из дней будет не более чем одна неявка? (a) 61% (b) 29% (c) 39% (d) 9% 7.5. Какова вероятность того, что в следующие один за другим два дня не будет не одной неявки? (a) 64% (b) 16% (c) 10.2% (d) 9.1%
229

Часть III. Статистические методы Тема 7. Распределения
7.7. Необходимо из восьми претендентов на работу в новом офисе отобрать три человека. Сколько вариантов выбора имеется? (a) 1 344 (b) 336 (c) 40 320 (d) 56 7.8. Какие имеются преимущества при использовании стандартных распределений по сравнению с наблюдаемыми? (a) Нет нужды собирать данные. (b) Уже доступна многая информация о таких распределениях (например, таблицы веро-ятностей). (c) Более высокая точность. 7.9. Какое стандартное распределение лучше подходит для следующей ситуации: были опрошены 100 жителей г. Томска, и их спрашивали, смотрят ли они передачу «Крутой по-ворот»? (a) Нормальное (b) Биноминальное 7.10. В вопросе 7.9, аппроксимация биноминального распределения нормальным возмож-на. Так ли это? 7.11. Компания планирует изготавливать новый вид шоколадных батончиков. Предпола-гается, что через три месяца после начала продаж 40% населения будут уже знакомы с этой маркой. Если действительно будет так, то какова вероятность того, что в случайной выборке из пяти человек только один будет знать о новом виде батончиков, появившемся на рынке? (a) 0.08 (b) 0.05 (c) 0.13 (d) 0.26
Вопросы 7.12-7.14 касаются следующей ситуации: В одном из офисов крупной компании клерки обрабатывают некие бухгалтерские квитан-ции. Известно, что число обработанных в день квитанций можно описать нормальным распределением, со средним значением 190 и стандартным отклонением 25. В офисе рабо-тает 12 клерков. 7.12. Вычислить общее количество квитанций, обрабатываемых в течении дня всеми клерками. (a) 2280 (b) 300 (c) 190 (d) 2880 7.13. Вычислить количество клерков, кто обрабатывает более 215 квитанций в день. (a) 1 (b) 1 клерк через день (c) 2 (d) 3
230

Часть III. Статистические методы Тема 7. Распределения
7.14. В каком диапазоне находится количество обработанных квитанций любым клерком в любой день в вероятностью 95%? (a) от 140 до 240 (b) от 165 до 215 (c) от 115 до 265 (d) от 140 до 215
Case Study 7.1: Экзаменационные оценки После изучения студентами курса по статистике их оценки распределились сле-
дующим образом – средняя оценка 69.8 балла и среднеквадратическое отклонение 11.6. Курс прослушало 180 студентов. Предполагая, что распределение оценок нормальное, оп-ределить: (a) количество студентов, чьи оценки выше, чем 85 баллов. (b) количество студентов, чьи оценки ниже, чем 40 баллов.
Таблица нормального распределения
231

Часть III. Статистические методы Тема 7. Распределения
Case Study 7.2: Запчасти Компания производит запчасти для автомобилей. Система проверки качества уст-
роена следующим образом. Через регулярные интервалы времени случайным образом проверяется 6 деталей. Количество дефектных деталей подсчитывается и протоколирует-ся. За сто проверок в 52 случаях дефектные деталей не было, в 34 случаях была всего одна дефектная деталь, в 10 случаях были замечены две дефектные детали, в остальных случа-ях были три дефектные детали. (a) Не противоречат ли результаты проверки деталей утверждению, что в среднем выпус-кается 10% бракованных деталей? (b) Почему Вы так считаете?
Таблица биноминального распределения
232

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
Вопросы 9.1. Какие из следующих утверждений верны? (a) Корреляция и регрессия – это слова-синонимы. (b) Корреляция может помочь найти линейную связь между весами тел бизнесменов (одна выборка) и зарплатами (другая выборка). (c) Годовые объемы продаж 17 отделений одной компании могут быть представлены в ви-де таблицы, содержащей 17 пар значений. (d) Если большие значения одной переменной связаны с небольшими значениями другой переменной, то говорят, что переменные имеют отрицательную корреляцию. 9.2. Какие из следующих утверждений верны? Остатки регрессионной прямой: (a) это длины перпендикуляров, опущенных из действительных точек на прямую. (b) это разница между действительными и подобранными значениями. (c) всегда положительны. (d) все равны нулю, если регрессионная прямая идеальна. Вопросы 9.3-9.6 относятся к следующему набору данных
x 4 6 9 10 11 y 2 4 4 7 8
9.3. Какой наклон регрессионной линии? (a) 8 (b) 0.765 (c) 1.12 (d) -0.71 (e) 5 9.4. В какой точке регрессионная линия пересекает ось ординат? (a) 5 (b) 0.765 (c) -1.12 (d) 1.12 (e) 0.68 9.5. Каково значение корреляционного коэффициента? (a) 0.91 (b) 0.76 (c) -0.76 (d) 0.83 9.6. Чему равен остаток для точки (4, 2)? (a) 0.06 (b) -0.06 (c) -1.12 (d) 1.59 (e) -1.59
233

Часть IV. Статистические зависимости Тема 9. Регрессия и корреляция
9.7. Какова взаимосвязь между возрастом мужей и жён: (a) сильная положительная корреляция. (b) слабая положительная корреляция. (c) нулевая корреляция. (d) слабая отрицательная корреляция. (e) сильная отрицательная корреляция. 9.8. Верно или нет следующее? Исследования показали, что имеется сильная положительная корреляция между возрас-том, в котором человек умирает и количеством визитов к доктору. Исследователь сделал вывод, что посещения в врачу продлевают жизнь. Вопрос 9.9 относится к следующей распечатке, полученной из статистической про-граммы. Речь идет об объёмах продаж и расходами на рекламу. Коэффициент Расходы на рекламу 6.3 Константа 14.7 R2 0.70 Сумма квадратов остатков 900 9.9. Каковы Ваши предсказания о будущих продажах, если расходы на рекламу устано-вить в 5 единиц? (a) 21.0 (b) 31.5 (c) 46.2 (d) 7.74 9.10. Изучается связь между продажами компании (y) и их расходами на рекламу (x). Бы-ли найдены две регрессионные линии – зависимость (x) от (y) и зависимость (y) от (x). Ка-кие из следующих утверждений верны? (a) Корреляционные коэффициенты равны в обоих случаях. (b) Наклоны двух регрессионных линий равны. (c) Точки пересечения с осью ординат равны в обоих случаях.
Case Study 9.1. Клерки Имеется следующая информация о шести отделениях компании, и о клерках этой
компании, выполняющих схожие операции: Офисы
1 2 3 4 5 6 Операции (у) 11 7 12 17 19 18 Клерки (x) 3 1 3 4 6 7
(a) Нарисуйте диаграмму разброса и определите, имеется ли линейная взаимосвязь между y и x. Рассчитайте корреляционный коэффициент. (b) Следующие три прямых неплохо связывают y и x между собой: (i) Прямая, проходящая через точки (1,7) и (6,19). (ii) Прямая, проходящая через точки (1,7) и (7,18). (iii) Регрессионная прямая (зависимость y от x). Найдите уравнение для каждой прямой. Измерьте остатки.
234


















